本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
Amazon SageMaker AI 模型质量报告(也称为绩效报告)为 AutoML 作业生成的最佳候选模型提供见解和质量信息。这些信息包括作业详细信息、模型问题类型、目标函数和其他与问题类型相关的信息。本指南介绍如何以图形方式查看 Amazon SageMaker AI Autopilot 性能指标,或者如何在 JSON 文件中以原始数据形式查看指标。
例如,在分类问题中,模型质量报告包括以下内容:
-
混淆矩阵
-
接收者操作特征曲线下的面积 (AUC)
-
用于了解假阳性和假阴性的信息
-
在真阳性和假阳性之间权衡
-
在查准率和查全率之间权衡
Autopilot 还会提供所有候选模型的性能指标。这些指标使用所有训练数据进行计算,用于估算模型性能。默认情况下,主工作区域包括这些指标。指标的类型由所要解决的问题类型确定。
有关 Autopilot 支持的可用指标列表,请参阅 A mazon SageMaker API 参考文档。
您可以使用相关指标对候选模型进行排序,以帮助您选择和部署能满足业务需求的模型。有关这些指标的定义,请参阅 Autopilot 候选指标主题。
要查看 Autopilot 作业的性能报告,请按照以下步骤操作:
-
从左侧导航窗格中选择 “主页” 图标 (
 ),查看顶级 Amazon SageMaker Studio Classic 导航菜单。
),查看顶级 Amazon SageMaker Studio Classic 导航菜单。 -
从主工作区选择 AutoML 卡片。这将打开新的 Autopilot 选项卡。
-
在名称部分中,选择包含您要检查的 Autopilot 作业的详细信息。这将打开新的 Autopilot 作业选项卡。
-
Autopilot 作业面板在模型名称下列出指标值,包括各个模型的目标指标。最佳模型列在模型名称下的列表顶部,并在模型选项卡中突出显示。
-
要查看模型详细信息,请选择您感兴趣的模型,然后选择查看模型详细信息。这将打开一个新模型详细信息选项卡。
-
-
选择解释功能与构件选项卡之间的性能选项卡。
-
在选项卡的右上角,选择下载性能报告按钮上的向下箭头。
-
向下箭头提供了两个选项用于查看 Autopilot 性能指标:
-
您可以下载性能报告的 PDF 文件来查看指标图表。
-
您可以下载 JSON 文件,以原始数据格式查看指标。
-
-
有关如何在 SageMaker Studio Classic 中创建和运行 AutoML 作业的说明,请参阅。使用 AutoML API 为表格数据创建回归或分类作业
性能报告分为两个部分。第一部分包含有关生成模型的 Autopilot 作业的详细信息。第二部分包含模型质量报告。
Autopilot 作业详细信息
报告的第一部分提供了有关生成模型的 Autopilot 作业的一些常规信息。这些作业详细信息包括以下内容:
-
Autopilot 候选项名称
-
Autopilot 作业名称
-
问题类型
-
目标指标
-
优化方向
模型质量报告
模型质量信息由 Autopilot 模型见解生成。所生成报告的内容取决于其解决的问题类型:回归、二元分类还是多元分类。报告指定了评估数据集中包含的行数,以及进行评估的时间。
指标表
模型质量报告的第一部分包含指标表。它们适用于模型所解决的问题类型。
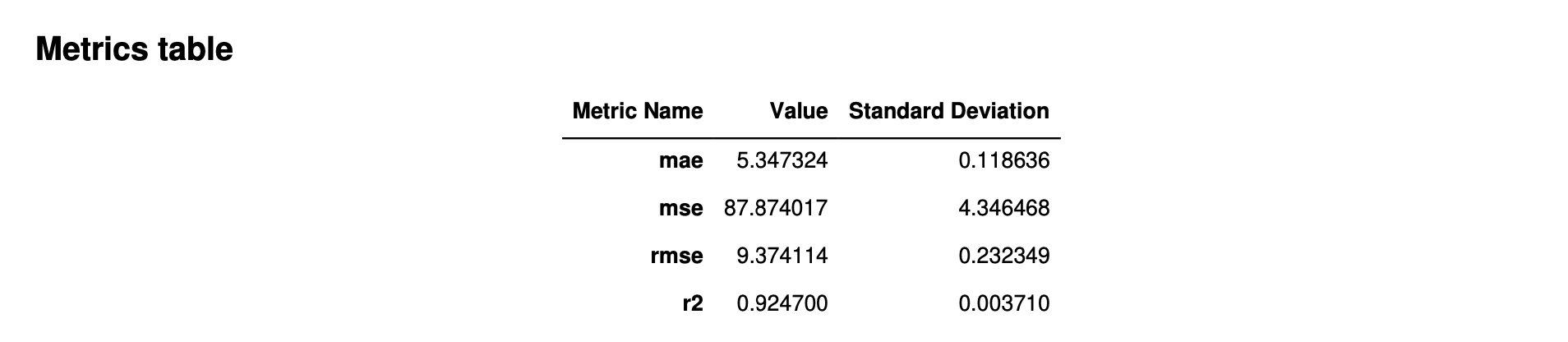
下图是 Autopilot 针对回归问题生成的指标表示例。它显示指标名称、值和标准差。
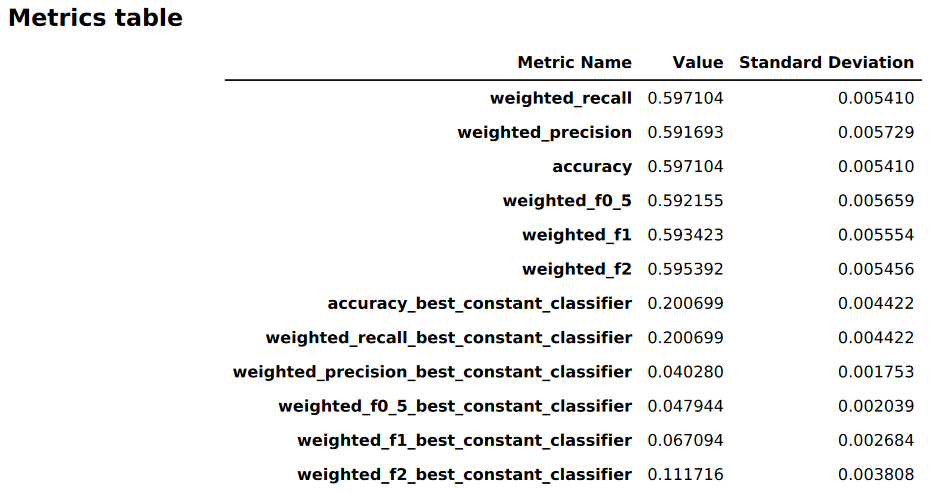
下图是 Autopilot 针对多元分类问题生成的指标表示例。它显示指标名称、值和标准差。
图形模型性能信息
模型质量报告的第二部分包含图形信息,用于帮助您评估模型性能。此部分的内容取决于建模中使用的问题类型。
接收者操作特征曲线下面积
接收者操作特征曲线下面积表示在真阳性和假阳性之间的权衡。它是用于二元分类模型的行业标准确性指标。AUC(Area Under the Curve,曲线下面积)衡量模型为针对阳性样本进行预测,相比针对阴性样本进行预测得到更高分数的能力。AUC 指标提供了在所有可能的分类阈值中,模型性能的综合度量。
AUC 指标返回从 0 到 1 的数值。接近 1 的 AUC 值指示高度准确的机器学习模型。接近 0.5 的值指示模型的性能基本相当于随机猜测。AUC 值接近 0 表示模型已经学习了正确的模式,但做出了完全不准确的预测。接近零的值表示数据有问题。有关 AUC 指标的更多信息,请转到维基百科上的接收者操作特征
以下是接收者操作特性曲线下面积图示例,用于评估二元分类模型所做的预测。虚线表示对 no-better-than-random猜测进行分类的模型将得分的接收器操作特性曲线下方的区域,AUC 分数为 0.5。更准确的分类模型的曲线高于这个随机基线,其中真阳性的比率超过了假阳性。表示二元分类模型性能的接收者操作特征曲线下面积采用粗实线。
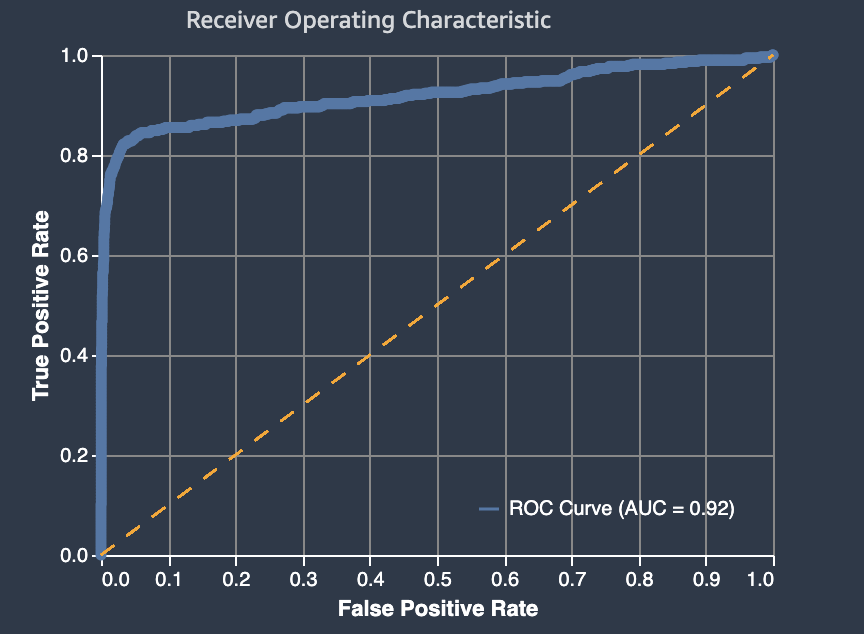
图中假阳性率 (FPR) 和真阳性率 (TPR) 的组成部分摘要定义如下。
-
正确预测
-
真阳性 (TP):预测的值为 1,真正的值为 1。
-
真阴性 (TN):预测的值为 0,真正的值为 0。
-
-
错误预测
-
假阳性 (FP):预测的值为 1,但真正的值为 0。
-
假阴性 (FN):预测的值为 0,但真正的值为 1。
-
假阳性率 (FPR) 衡量的是被错误预测为阳性 (FP) 的真阴性 (TN) 占 FP 和 TN 之和的比例。范围为 0 至 1。值越小说明预测准确性越高:
-
FPR = FP/(FP+TN)
真阳性率 (TPR) 衡量的是被正确预测为阳性的真阳性 (TP) 占 TP 和假阴性 (FN) 之和的比例。范围为 0 至 1。较大的值表示更好的预测准确度。
-
TPR = TP/(TP+FN)
混淆矩阵
混淆矩阵提供了一种方法,用于可视化模型针对不同问题的二元分类和多元分类预测的准确性。模型质量报告中的混淆矩阵包含以下内容。
-
针对实际标签的正确和错误预测的数量和百分比
-
准确预测的数量和百分比按照从左上角到右下角沿对角线排列。
-
不准确预测的数量和百分比按照从右上角到左下角沿对角线排列。
在混淆矩阵上,错误预测是混淆值。
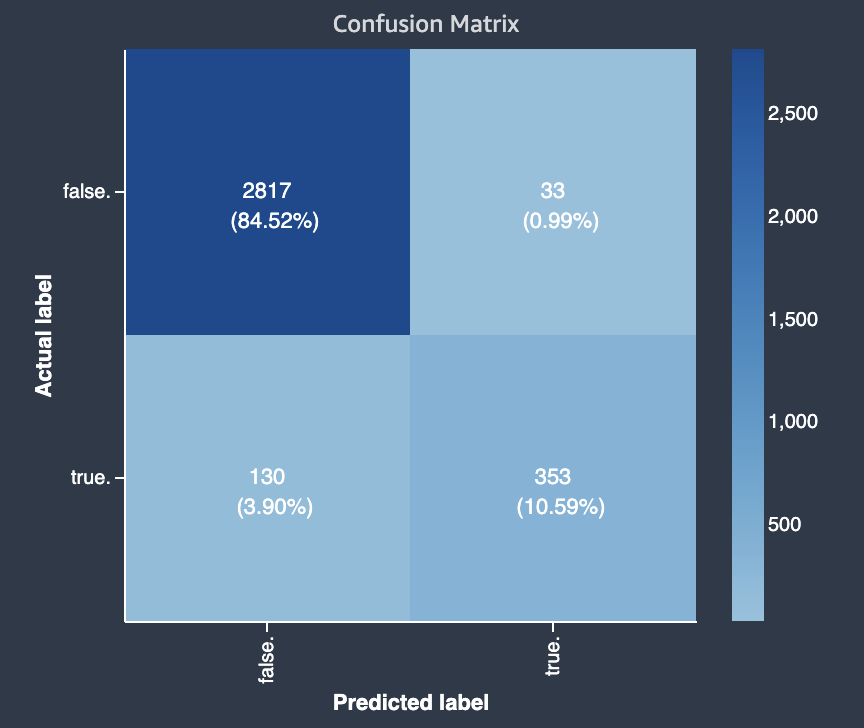
下图是一个二元分类问题的混淆矩阵的示例。它包含以下信息:
-
垂直轴分为两行,分别包含正确和错误的实际标签。
-
水平轴分为两列,包含模型所预测的正确和错误的标签。
-
彩色条形图为较多数量的样本分配较深的色调,以直观地指示分类到每个类别中值的数量。
在此示例中,模型正确预测了实际的 2817 个假值,正确预测了 353 个实际的真值。模型错误地将 130 个实际的真值预测为假,并将 33 个实际的假值预测为真。色调的差异表明数据集不平衡。这种不平衡是因为实际的假标签比实际的真标签多得多。
下图是一个多元分类问题的混淆矩阵的示例。模型质量报告中的混淆矩阵包含以下内容。
-
垂直轴分为三行,包含三个不同的实际标签。
-
水平轴分为三列,包含模型所预测的标签。
-
彩色条形图为较多数量的样本分配较深的色调,以直观地指示分类到每个类别中值的数量。
在下面的示例中,模型正确预测了标签 f 的 354 个实际值、标签 i 的 1094 个值和标签 m 的 852 个值。色调的差异表明数据集不平衡,因为值 i 的标签比值 f 或 m 要多得多。
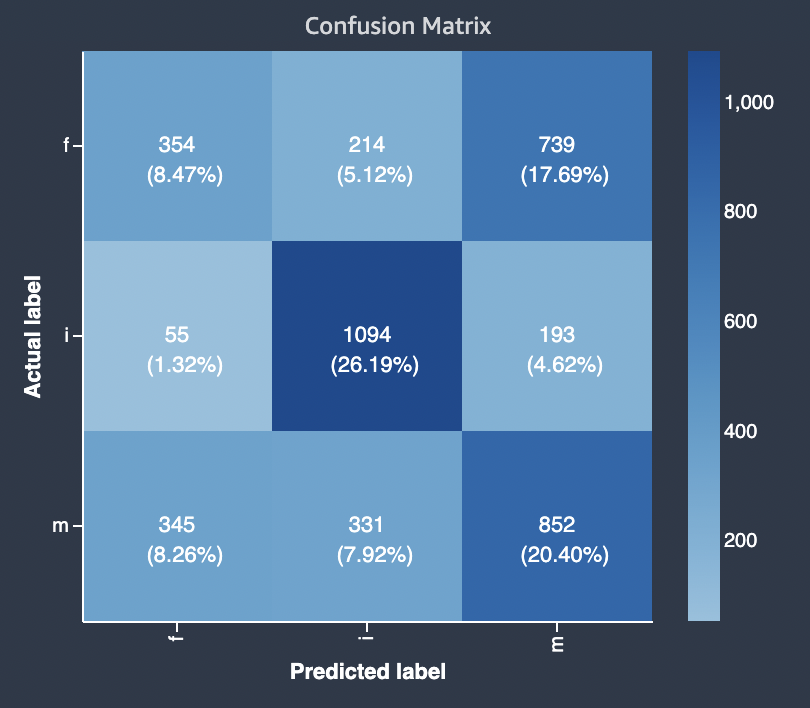
模型质量报告提供了一个混淆矩阵,对于多元分类问题类型,最多可容纳 15 个标签。如果与标签对应的行显示 Nan 值,这意味着用于检查模型预测的验证数据集不包含带有该标签的数据。
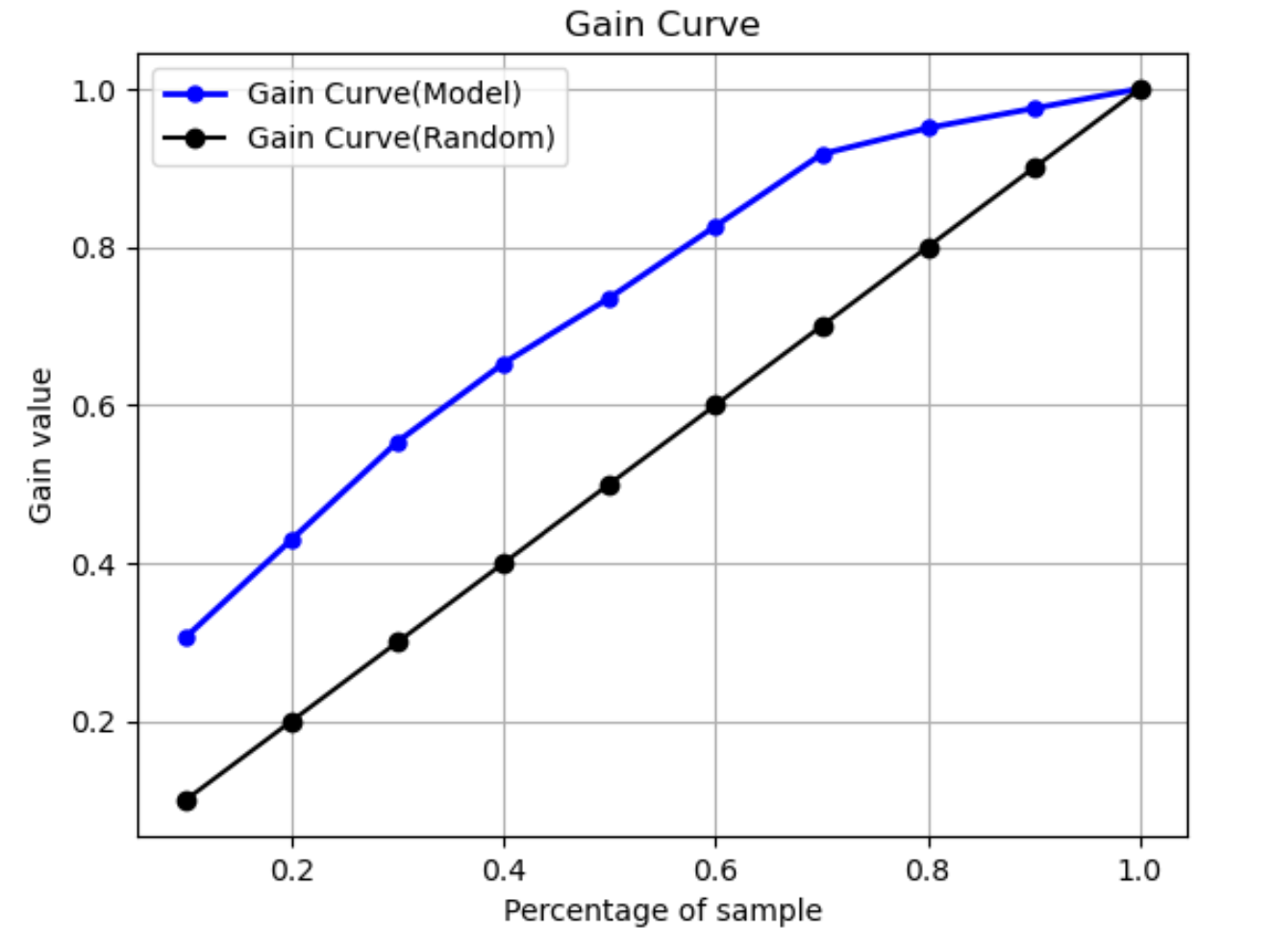
增益曲线
在二元分类中,增益曲线预测使用一定百分比的数据集来寻找阳性标签的累计收益。在训练期间,通过在每个十分位数将累计的阳性观察数据数量,除以数据中阳性观察数据的总数,以此来计算增益值。如果训练期间创建的分类模型代表了未用于训练的数据,则可以使用增益曲线来预测为获得一定百分比的阳性标签,而必须作为目标的数据百分比。使用的数据集百分比越大,找到的阳性标签的百分比就越高。
在下面的示例图中,增益曲线是斜率变化的线段。直线是通过从数据集中随机选择一定百分比的数据而找到的阳性标签的百分比。将数据集的 20% 作为目标后,您会发现超过 40% 的阳性标签。举个例子,您可以考虑使用收益曲线来确定在营销活动中的投放量。在我们的增益曲线示例中,要让社区中 83% 的人购买饼干,您需要向大约 60% 的社区人员发送广告。
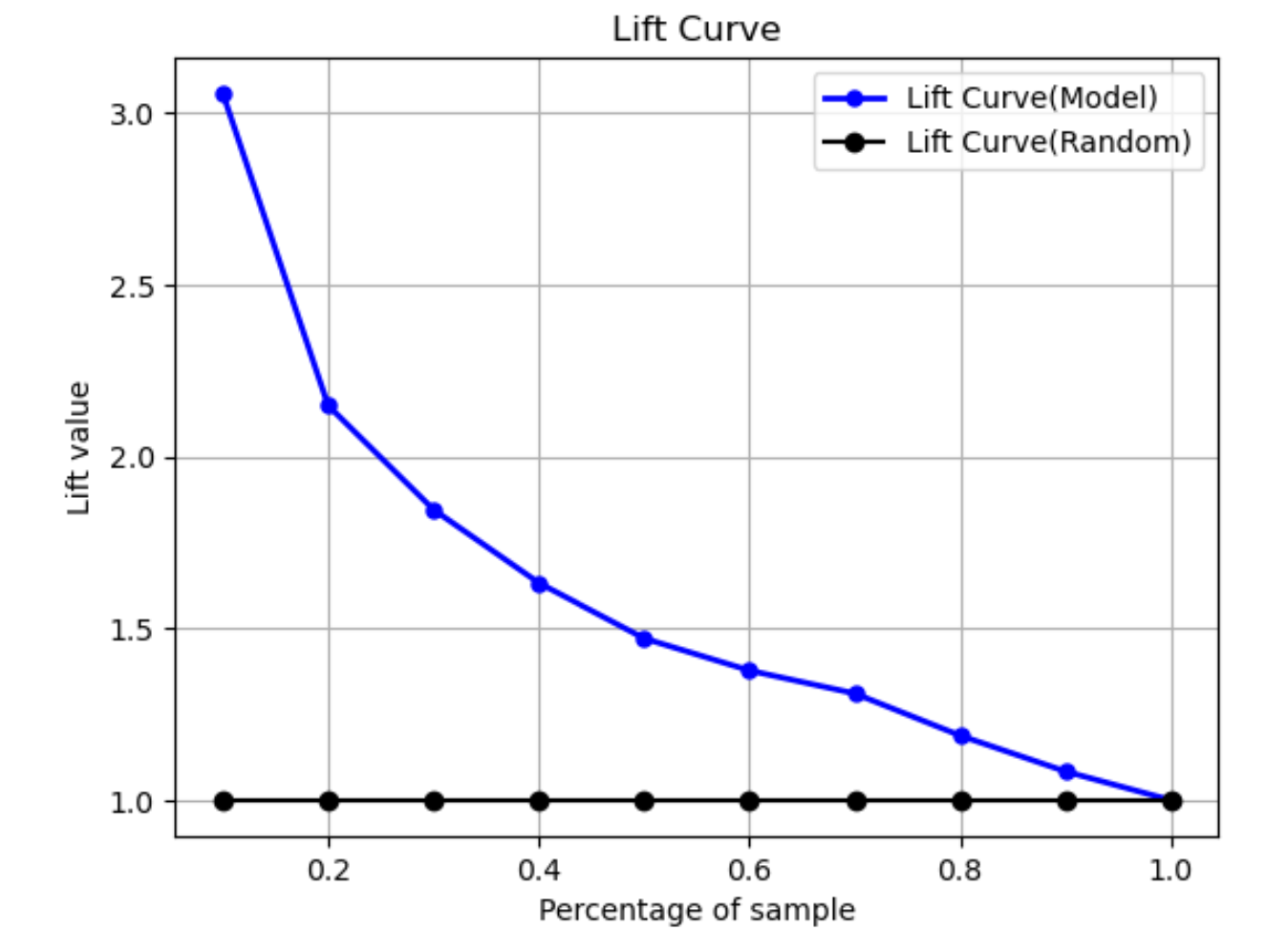
提升曲线
在二元分类中,提升曲线说明了使用经过训练的模型进行预测时,与随机猜测相比,找到阳性标签的可能性的提升。在训练期间,在每个十分位数,使用百分比增益相对于阳性标签的比率来计算提升值。如果训练期间创建的模型代表了未用于训练的数据,则使用提升曲线来预测使用模型相比随机猜测的增益。
在下面的示例图中,提升曲线是斜率变化的线段。直线是与从数据集中随机选择对应百分比相关的提升曲线。对模型的分类标签使用 40% 的数据集作为目标后,您预计找到的阳性标签数量,约为通过随机选择 40% 的未用于训练的数据所能找到的阳性标签数量的 1.7 倍。
查准率-查全率曲线
查准率-查全率曲线代表了在二元分类问题中,在查准率和查全率之间的权衡。
查准率衡量在所有阳性预测(TP 和假阳性)中,预测为阳性的实际阳性 (TP) 的比例。范围为 0 至 1。较大的值表示预测值有更好的准确性。
-
查准率 = TP/(TP+FP)
查全率衡量在所有实际阳性预测(TP 和假阴性)中,预测为阳性的实际阳性的比例。这也被称为敏感度或真阳性率。范围为 0 至 1。值越大表示可以更好地检测样本中的阳性值。
-
查全率 = TP/(TP+FN)
分类问题的目标是正确地标注尽可能多的元素。查全率高但查准率低的系统返回的假阳性百分比很高。
下图描绘了将每封电子邮件标记为垃圾邮件的垃圾邮件筛选器。它的查全率很高,但查准率低,因为查全率不能衡量假阳性。
如果您的问题对假阳性值的惩罚很低,但对错过真阳性结果的惩罚很高,则更重视的是查全率而不是查准率。例如,在自动驾驶车辆中检测即将发生的碰撞。
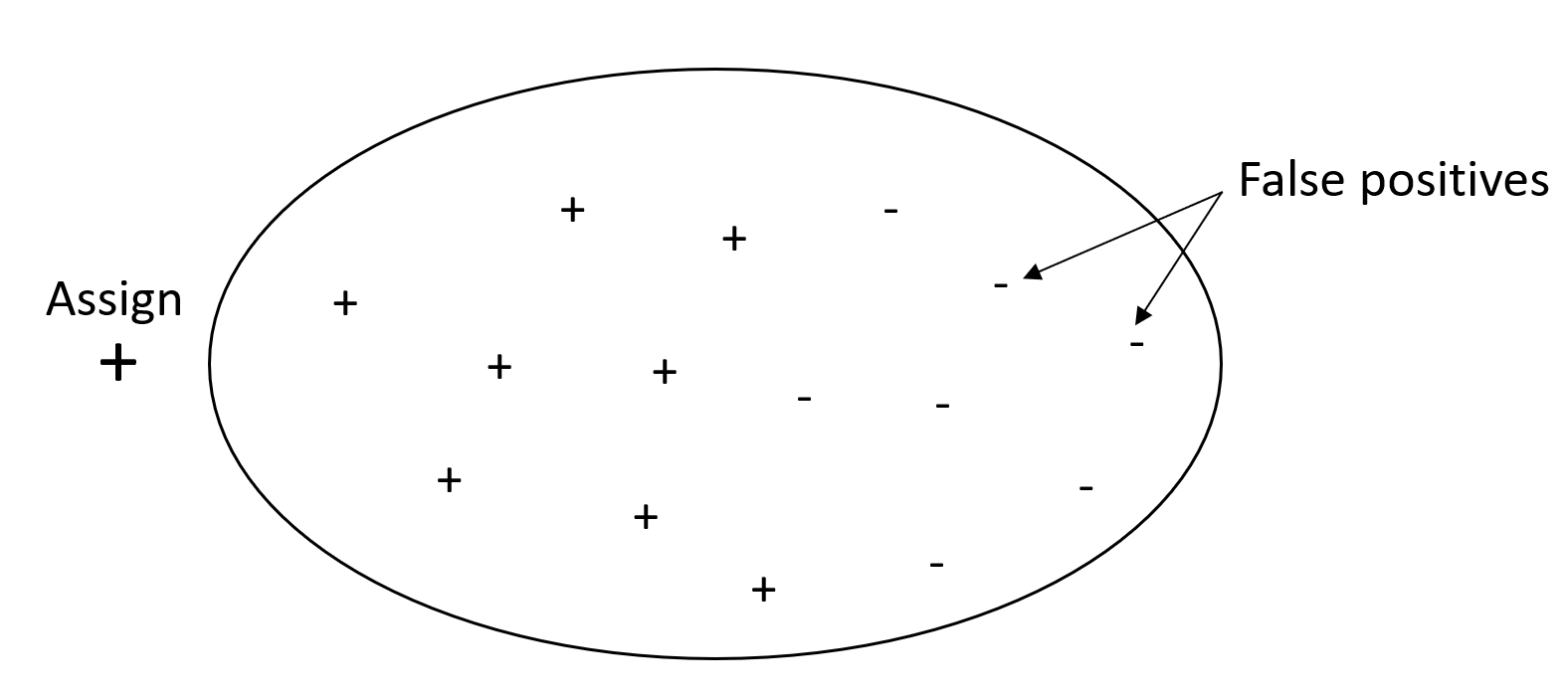
相比之下,查准率高但查全率低的系统返回的假阴性百分比很高。将每封电子邮件标记为正常电子邮件(而不是垃圾邮件)的垃圾邮件筛选器查准率高,但查全率低,因为查准率无法衡量假阴性。
如果您的问题对假阴性值的惩罚很低,但对错过真阴性结果的惩罚很高,则更重视的是查准率而不是查全率。例如,标记可疑筛选条件用于税务审计。
下图描绘了一个垃圾邮件筛选器,具有高查准率,但查全率低,因为查准率不能衡量假阴性。
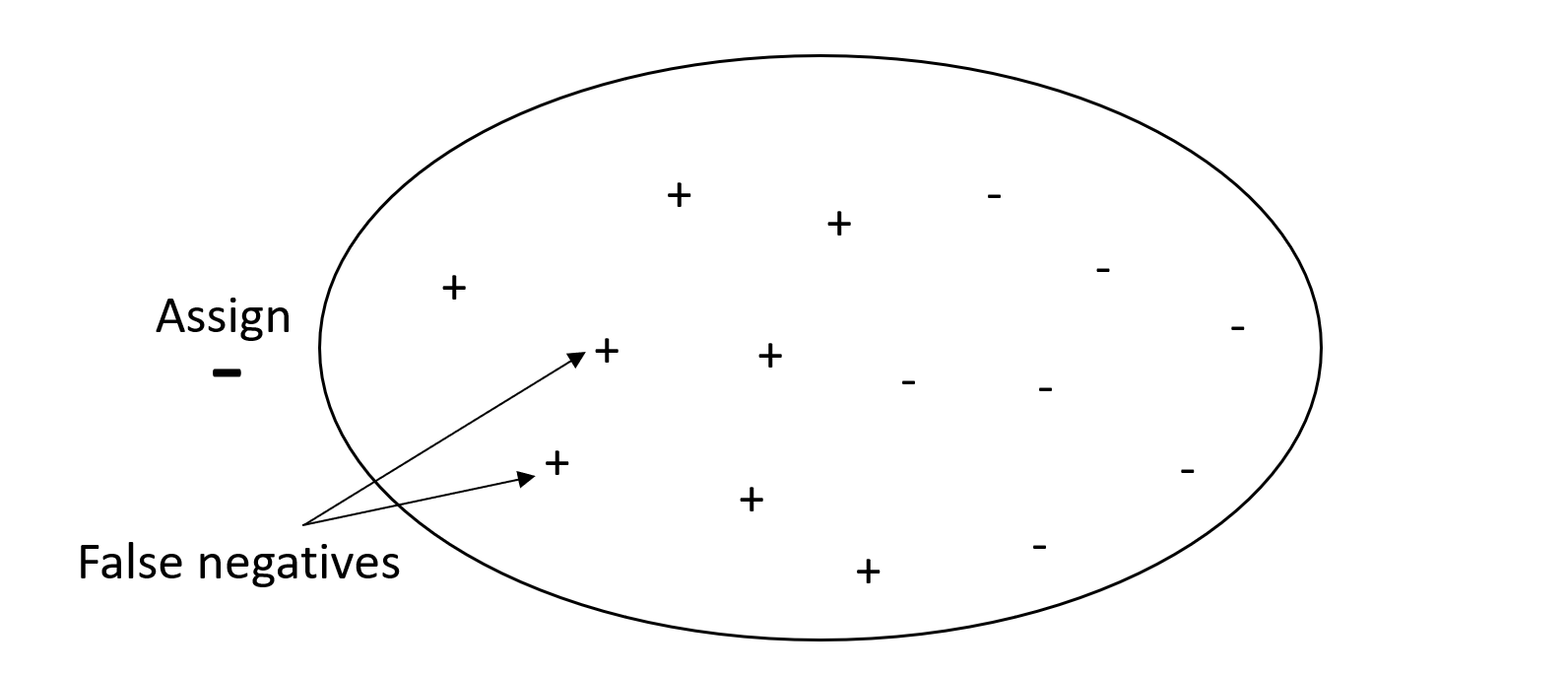
能够同时进行高查准率和高查全率预测的模型,可以得到大量正确标注的结果。有关更多信息,请参阅维基百科中的查准率和查全率
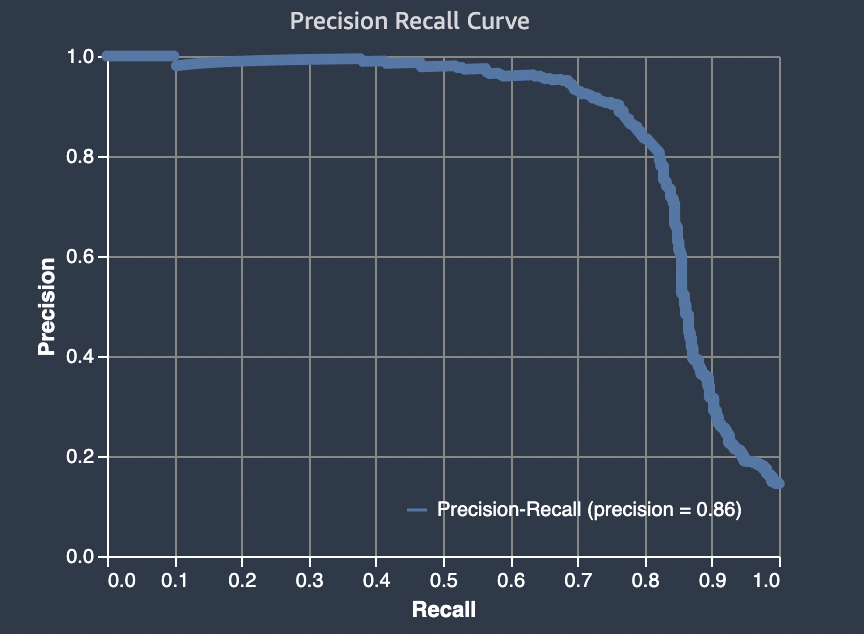
查准率-查全率曲线下面积 (AUPRC)
对于二元分类问题,Amazon A SageMaker utopilot 包括精确召回曲线 (AUPRC) 下方区域的图表。AUPRC 指标提供了在所有可能的分类阈值中,同时使用查准率和查全率的模型性能综合度量。AUPRC 不考虑真阴性的数量。因此,在数据中存在大量真阴性的情况下,它对于评估模型性能会很有用。例如,对包含罕见突变的基因进行建模。
下图是 AUPRC 图表的示例。查准率的最高值 1,查全率为 0。在图表的右下角,查全率是其最高值 (1),查准率为 0。在这两点之间,AUPRC 曲线说明了在不同阈值下精度和查全率之间的权衡。
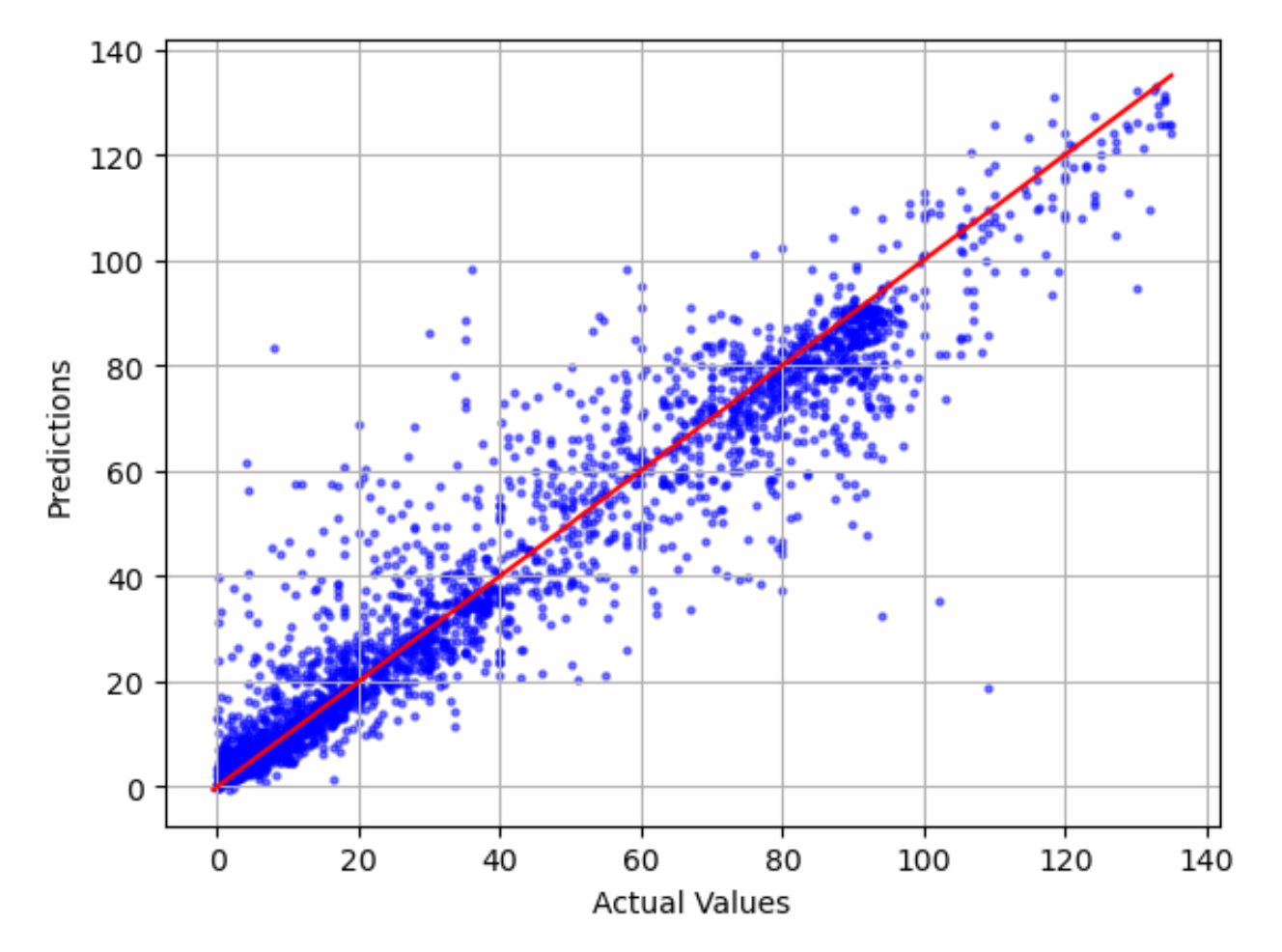
实际值与预测值图表
实际值与预测值的图表显示了实际模型值与预测模型值之间的差异。在下面的示例图中,实线是一条最佳拟合的直线。如果模型的准确性为 100%,则每个预测点将等于其实际点,并位于这条最佳拟合线上。距离最佳拟合线的距离直观地指示了模型误差。距离最佳拟合线的距离越大,模型误差越大。
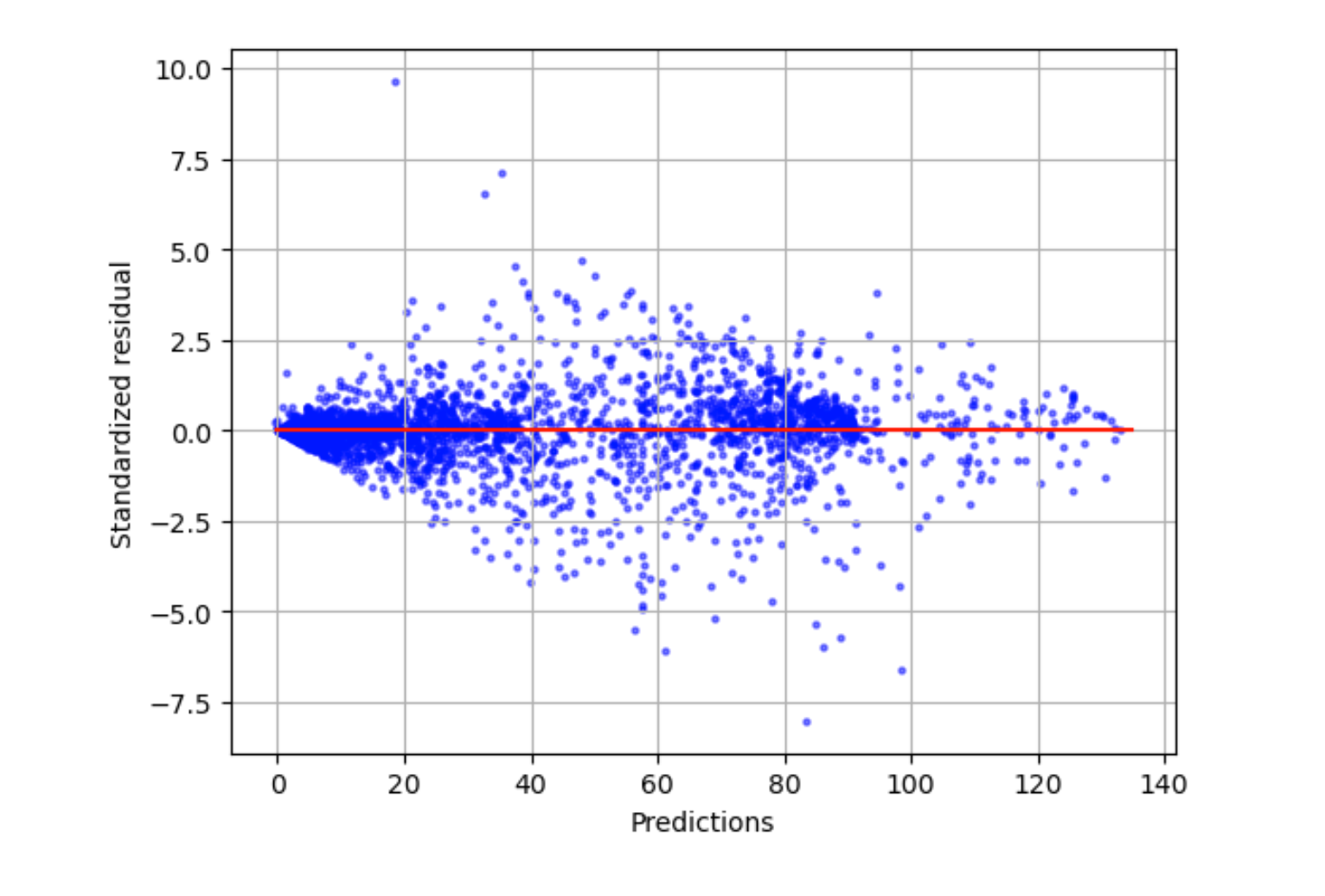
标准化残差图
标准化残差图包含以下统计项:
residual-
(原始)残差显示实际值与模型的预测值之间的差异。差异越大,残差值越大。
standard deviation-
标准差用于衡量值相对平均值的差异。高标准差表明有许多值与其平均值存在很大差异。低标准差表明有许多值接近其平均值。
standardized residual-
标准化残差将原始残差除以其标准差。标准化残差以标准差为单位,在识别数据中的异常值时非常有用,无论原始残差的比例有多大。如果某个标准化残差远小于或远大于其他标准化残差,则表明模型对这些观察数据的拟合效果不佳。
标准化残差图衡量观察数据与预期值之间差异强度。实际预测值显示在 x 轴上。差值的绝对值超过 3 的点通常被视为异常值。
以下示例图表显示,大量标准化残差聚集在水平轴上 0 附近。接近零的值表示模型对这些点的拟合效果良好。图形顶部和底部的点表示模型无法很好地预测这些点。
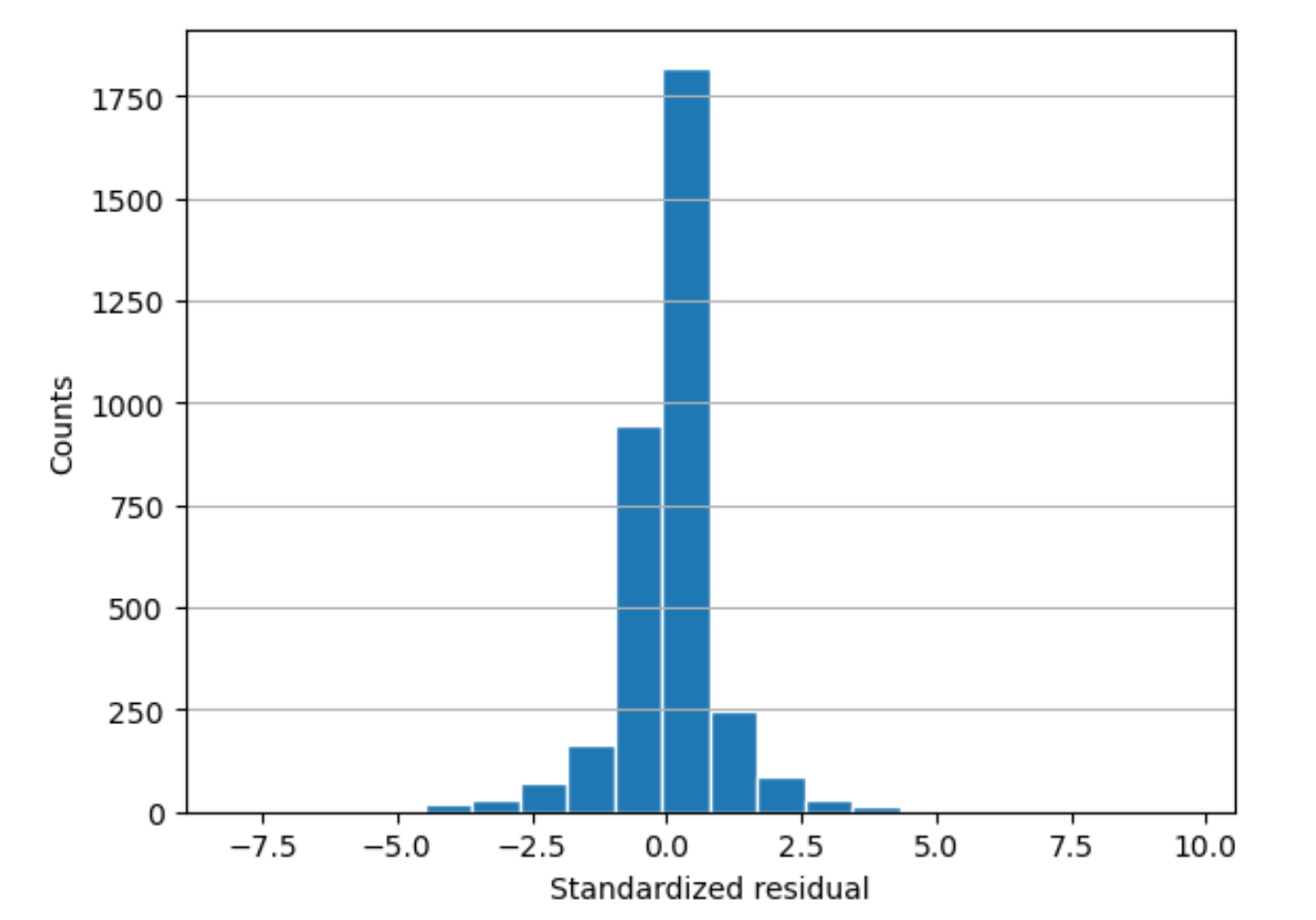
残差直方图
残差直方图包含以下统计项:
residual-
(原始)残差显示实际值与模型的预测值之间的差异。差异越大,残差值越大。
standard deviation-
标准差用于衡量值相对平均值的差异程度。高标准差表明有许多值与其平均值存在很大差异。低标准差表明有许多值接近其平均值。
standardized residual-
标准化残差将原始残差除以其标准差。标准化残差以标准差为单位。这些值在识别数据中的异常值时非常有用,无论原始残差的比例有多大。如果某个标准化残差远小于或远大于其他标准化残差,则表明模型对这些观察数据的拟合效果不佳。
histogram-
直方图是显示值出现频率的图表。
残差直方图显示标准化残差值的分布。呈钟形分布并且中心在零的直方图,指示模型不会系统性地过高或过低预测目标值的任何特定范围。
在下图中,标准化的残差值表明模型对数据的拟合效果良好。如果图表显示的值远离中心值,则表明模型不能很好地拟合这些值。