本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
有关 SageMaker 人工智能推理托管的常见问题解答,请参阅以下常见问题解答。
通用托管
以下常见问题解答项回答了 SageMaker AI 推理的常见一般问题。
答:在您构建和训练模型之后,Amazon SageMaker AI 提供了四个部署模型的选项,以便您可以开始进行预测。实时推理适用于要求毫秒级延迟、负载大小最大 6 MB、处理时间最长 60 秒的工作负载。批量转换非常适合对预先提供的大批量数据进行离线预测。异步推理设计用于没有亚秒延迟要求、负载大小不超过 1 GB、处理时间最多 15 分钟的工作负载。借助无服务器推理,您可以快速部署用于推理的机器学习模型,无需配置或管理底层基础设施,而且您只需为处理推理请求所用的计算容量付费,这非常适合间歇性工作负载。
答:下图可以帮助您选择 SageMaker AI Hosting 模型部署选项。
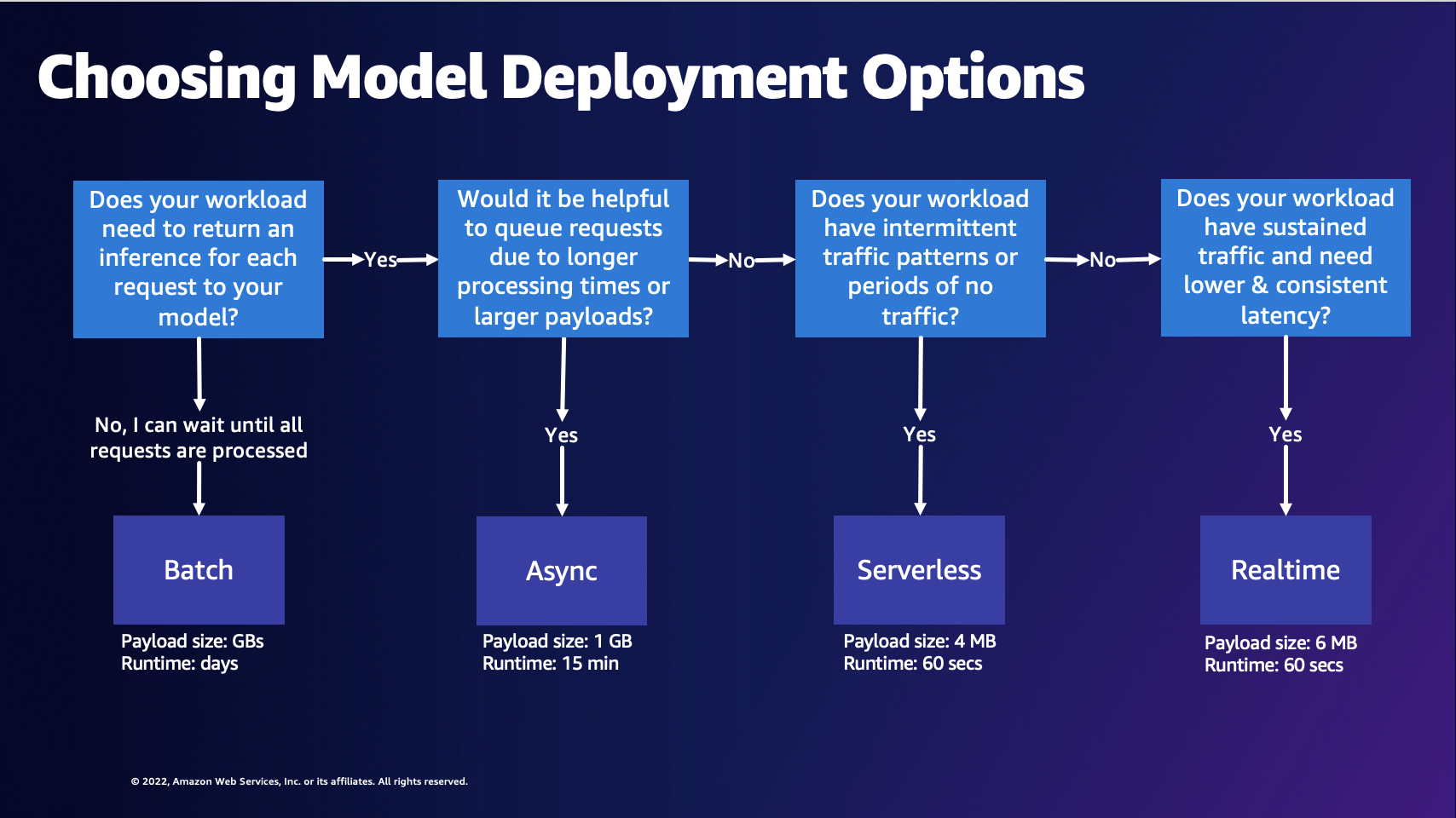
上图引导您了解以下决策过程。如果要批量处理请求,您可能需要选择批量转换。否则,如果您想接收发送到模型的每个请求的推理,则可能需要选择异步推理、无服务器推理或实时推理。如果您的处理时间较长或负载较大,并且想要对请求进行排队,则可以选择异步推理。如果您的工作负载具有不可预测或间歇性的流量,则可以选择无服务器推理。如果您有持续的流量并且需要较低且一致的请求延迟,则可以选择实时推理。
答:下图可以帮助您选择 SageMaker AI Hosting 模型部署选项。
上图引导您了解以下决策过程。如果要批量处理请求,您可能需要选择批量转换。否则,如果您想接收发送到模型的每个请求的推理,则可能需要选择异步推理、无服务器推理或实时推理。如果您的处理时间较长或负载较大,并且想要对请求进行排队,则可以选择异步推理。如果您的工作负载具有不可预测或间歇性的流量,则可以选择无服务器推理。如果您有持续的流量并且需要较低且一致的请求延迟,则可以选择实时推理。
答:要使用 SageMaker AI Inference 优化成本,您应该为自己的用例选择正确的托管选项。您还可以使用推理功能,例如 Amazon A SageMaker I Savings Plan
答:如果您需要推荐正确的终端节点配置以提高性能和降低成本,则应使用 Amazon SageMaker Inference Recommerder。以前,想要部署模型的数据科学家必须运行手动基准测试,以选择合适的端点配置。首先,他们必须根据模型和示例负载的资源要求,从 70 多种可用实例类型中选择合适的机器学习实例类型,然后优化模型以考虑不同的硬件。接下来,他们必须进行广泛的负载测试,以验证是否满足了延迟和吞吐量要求并且成本很低。Inference Recommender 可帮助您实现:
-
提供实例推荐,在几分钟内即可开始使用。
-
对各种实例类型进行负载测试,以便在数小时内获得有关端点配置的建议。
-
自动调整容器和模型服务器参数,并针对给定实例类型执行模型优化。
答: SageMaker AI 端点是使用容器化 Web 服务器(包括模型服务器)的 HTTP REST 端点。这些容器负责加载和处理机器学习模型的请求。它们实施在端口 8080 上响应 /invocations 和 /ping 的 Web 服务器。
常见的模型服务器包括 TensorFlow 服务服务器 TorchServe 和多模型服务器。 SageMaker AI 框架容器内置了这些模型服务器。
答: SageMaker AI 推理中的所有内容都是容器化的。 SageMaker AI 为流行的框架(例如 TensorFlow SKlearn、和)提供托管容器 HuggingFace。有关这些映像的最新完整列表,请参阅可用映像
有时,您可能需要为一些自定义框架构建容器。这种方法被称为自带容器,简称 BYOC。使用 BYOC 方法,您可以提供 Docker 映像来设置框架或库。然后,你将镜像推送到亚马逊弹性容器注册表 (Amazon ECR) Container Registry,这样你就可以将镜像与 AI 一起使用。 SageMaker 有关 BYOC 方法的示例,请参阅 Amazon AI 容器概述
或者,您可以扩展容器,而不是从头开始构建映像。你可以获取 SageMaker AI 提供的基础映像之一,然后在 Dockerfile 中在其上面添加依赖关系。
答: SageMaker AI 提供了将你自己在 AI 之外训练过的框架模型带到任何 SageMaker A SageMaker I 托管选项上的能力。
SageMaker AI 要求您将模型打包成model.tar.gz文件并具有特定的目录结构。每个框架都有自己的模型结构(有关示例结构,请参阅以下问题)。有关更多信息,请参阅、和的 SageMaker Python 开发工具包文档MXNet
虽然您可以从 TensorFlow、 PyTorch和等预构建的框架映像中进行选择 MXNet 来托管您的训练模型,但您也可以构建自己的容器,以便在 SageMaker AI 端点上托管经过训练的模型。有关演练,请参阅 Jupyter 笔记本构建自己的算法容器
答: SageMaker AI 要求将模型工件压缩到.tar.gz文件或压缩包中。 SageMaker AI 会自动将此.tar.gz文件提取到容器中的/opt/ml/model/目录中。tarball 不应包含任何符号链接或不必要的文件。如果您使用的是其中一个框架容器,例如 TensorFlow PyTorch MXNet、或,则该容器希望您的 TAR 结构如下所示:
TensorFlow
model.tar.gz/
|--[model_version_number]/
|--variables
|--saved_model.pb
code/
|--inference.py
|--requirements.txtPyTorch
model.tar.gz/
|- model.pth
|- code/
|- inference.py
|- requirements.txt # only for versions 1.3.1 and higherMXNet
model.tar.gz/
|- model-symbol.json
|- model-shapes.json
|- model-0000.params
|- code/
|- inference.py
|- requirements.txt # only for versions 1.6.0 and higher答:ContentType 是请求正文中输入数据的 MIME 类型(您发送到端点的数据的 MIME 类型)。模型服务器使用 ContentType 来确定是否可以处理所提供的类型。
Accept 是推理响应的 MIME 类型(端点返回的数据的 MIME 类型)。模型服务器使用 Accept 类型来确定是否可以处理返回的类型。
常见的 MIME 类型包括 text/csv、application/json 和 application/jsonlines。
答: SageMaker AI 无需修改即可将任何请求传递到模型容器。容器必须包含反序列化请求的逻辑。有关为内置算法定义的格式的信息,请参阅用于推理的常用数据格式。如果您正在构建自己的容器或使用 A SageMaker I Framework 容器,则可以包含接受所选请求格式的逻辑。
同样, SageMaker AI 也会在不修改的情况下返回响应,然后客户端必须反序列化响应。对于内置算法,它们会以特定格式返回响应。如果您正在构建自己的容器或使用 A SageMaker I Framework 容器,则可以包含以您选择的格式返回响应的逻辑。
使用 Invoke Endpoint API 调用对您的端点进行推理。
将输入作为负载传递给 InvokeEndpoint API 时,您必须提供模型所需的正确输入数据类型。在 InvokeEndpoint API 调用中传递负载时,请求字节会直接转发到模型容器。例如,对于图像,您可以为 ContentType 使用 application/jpeg,并确保您的模型可以对此类数据进行推理。这适用于 JSON、CSV、视频或任何其他可能处理的输入类型。
另一个需要考虑的因素是负载大小限制。对于实时端点和无服务器端点,负载限制为 6 MB。您可以将视频拆分成多个帧,并为每个帧分别调用端点。或者,如果您的使用案例允许,您可以使用支持最多 1 GB 负载的异步端点,在负载中发送整个视频。
有关展示如何使用异步推理对大型视频运行计算机视觉推理的示例,请参阅此博客文章
实时推理
以下常见问题解答项回答了 SageMaker AI 实时推理的常见问题。
答:你可以通过 AWS支持的工具(例如 SageMaker Python SDK AWS SDKs、 AWS Management Console AWS CloudFormation、和)创建 SageMaker AI 端点。 AWS Cloud Development Kit (AWS CDK)
端点创建中有三个关键实体:A SageMaker I 模型、A SageMaker I 端点配置和 A SageMaker I 端点。A SageMaker I 模型指向您正在使用的模型数据和图像。端点配置定义您的生产变体,其中可以包括实例类型和实例数量。然后,你可以使用 create_endpoint
答:不,你可以使用各种 AWS SDKs (参见 Invoke/C reat e 了解可用信息 SDKs),甚至可以 APIs直接调用相应的网站。
答:多模型端点是 A SageMaker I 提供的实时推理选项。借助多模型端点,您可以在一个端点上托管数千个模型。多模型服务器
答: SageMaker AI 实时推理支持各种模型部署架构,例如多模型端点、多容器端点和串行推理管道。
多模型端点 (MME) – 通过 MME,客户能够以经济高效的方式部署上千种超个性化模型。所有模型都部署在共享资源的实例集上。当模型的大小和延迟相似且属于同一个 ML 框架时,MME 效果最好。当您不需要始终调用相同的模型时,这些端点是理想的选择。您可以将相应的模型动态加载到 SageMaker AI 端点以满足您的请求。
多容器端点 (MCE) — MCE 允许客户部署 15 个不同的容器,这些容器具有不同的机器学习框架和功能,无需冷启动,而只使用一个端点。 SageMaker 您可以直接调用这些容器。MCE 最适合需要将所有模型保存在内存中的情况。
串行推理管道 (SIP) – 您可以使用 SIP 将 2-15 个容器串连在一个端点上。SIP 最适合将预处理和模型推理结合在一个端点中,也适用于低延迟操作。
无服务器推理
以下常见问题解答回答了 Amazon SageMaker 无服务器推理的常见问题。
答:使用 Amazon SageMaker 无服务器推理部署模型是专用的无服务器模型服务选项,可用于轻松部署和扩展 ML 模型。无服务器推理端点会自动启动计算资源,并根据流量横向扩展和缩减,而无需选择实例类型、运行预置容量或管理扩展。您也可以选择为无服务器端点指定内存要求。您只需为推理代码的运行时间和处理的数据量付费,无需为空闲时间付费。
答:无服务器推理无需预先预置容量和管理扩展策略,从而简化了开发人员的体验。根据使用模式,无服务器推理可以在几秒钟内立即从数十个扩展到数千个推理,这使其非常适合间歇性或不可预测流量的 ML 应用程序。例如,薪资处理公司使用的聊天机器人服务在月底的查询量会增加,而在月中其余时间的流量是间歇性的。在这种情况下,为整个月预置实例并不划算,因为这样就需要为空闲时间付费。
无服务器推理为您提供开箱即用的自动快速横向扩展,无需您预先预测流量或管理扩展策略,即可满足这些类型使用案例的需求。此外,您只需为运行推理代码的计算时间和数据处理量付费,因此这非常适合间歇性流量的工作负载。
答:您的无服务器端点的最小 RAM 大小为 1024 MB (1 GB),您可以选择的最大 RAM 大小为 6144 MB (6 GB)。您可以选择的内存大小为 1024 MB、2048 MB、3072 MB、4096 MB、5120 MB 或 6144 MB。无服务器推理会自动分配与所选内存成比例的计算资源。如果您选择更大的内存大小,则您的容器可以访问更多的 v CPUs。
根据模型大小选择端点内存大小。一般来说,内存大小至少应与模型大小相同。您可能需要进行基准测试,以便根据延迟为模型选择正确的内存选择 SLAs。内存大小增量具有不同的定价;有关更多信息,请参阅 Amazon SageMaker 定价页面
批量转换
以下常见问题解答项回答了 SageMaker AI Batch Transform 的常见问题。
答:对于特定的文件格式,例如 CSV、Recordio 和 TFRecord, SageMaker AI 可以将您的数据拆分为单记录或多条记录的迷你批处理,然后将其作为有效载荷发送到您的模型容器。当值BatchStrategy为时MultiRecord, SageMaker AI 将在每个请求中发送的最大记录数,但不MaxPayloadInMB超过限制。当的值BatchStrategy为时SingleRecord, SageMaker AI 会在每个请求中发送单独的记录。
答:批量转换的最大超时时间为 3600 秒。记录(每个小批次)的最大负载大小为 100 MB。
答:如果您使用 CreateTransformJob API,您可以使用最佳的参数值(例如 MaxPayloadInMB、MaxConcurrentTransforms 或 BatchStrategy)来减少完成批量转换作业所需的时间。MaxConcurrentTransforms 的理想值等于批量转换作业中的计算工作线程数。如果您使用的是 SageMaker AI 控制台,则可以在 Batc h 转换作业配置页面的其他配置部分中指定这些最佳参数值。 SageMaker AI 会自动为内置算法找到最佳参数设置。对于自定义算法,通过 execution-parameters 端点提供这些值。
答:批量转换支持 CSV 和 JSON。
异步推理
以下常见问题解答项回答了 SageMaker AI 异步推理的常见一般问题。
答:异步推理队列对传入的请求进行排队并异步处理。此选项非常适合具有较大负载的请求,或者处理时间较长且需要在收到时进行处理的请求。或者,您可以配置自动扩缩设置,以便在没有主动处理请求时将实例个数缩减为零。
答:Amazon SageMaker AI 支持自动扩展(自动扩展)您的异步终端节点。自动扩缩动态调整为模型预置的实例数,以响应工作负载的变化。与 SageMaker AI 支持的其他托管模型不同,通过异步推理,您还可以将异步终端节点实例缩减到零。在实例数为零个时收到的请求将排队等待,直到端点纵向扩展后再处理这些请求。有关更多信息,请参阅自动扩缩异步端点。
Amazon SageMaker 无服务器推理还会自动缩小到零。您不会看到这一点,因为 SageMaker AI 可以管理扩展您的无服务器端点,但是如果您没有遇到任何流量,则使用相同的基础架构。
