本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
模型并行度库 SageMaker的核心功能之一是管道并行性,它决定了模型训练期间进行计算的顺序和跨设备处理数据的顺序。Pipelining 是一种通过在不同的数据样本上同时进行计算,从而在模型并行性中实现真正的并行化,并克服顺序 GPUs 计算导致的性能损失的技术。使用管道并行性时,训练作业以管道方式按照微批次执行,以最大限度地提高 GPU 使用率。
注意
管道并行度(也称为模型分区)可用于和。 PyTorch TensorFlow有关支持的框架版本,请参阅支持的框架和 AWS 区域。
管道执行计划
Pipelining 基于将迷你批次拆分为微批,这些微批量被输入到训练管道中, one-by-one并遵循库运行时定义的执行时间表。微批次是给定训练小批次的更小的子集。管道计划决定了每个时段由哪个设备执行哪个微批次。
例如,根据流水线计划和模型分区,GPU i 可能会在微批量上执行(向前或向后)计算,b而 GPU 则在微批处理上i+1执行计算b+1,从而使两者同时 GPUs 处于活动状态。在单次向前或向后传递期间,根据分区决策,单个微批次的执行流程可能会多次访问同一个设备。例如,位于模型开头的操作,与位于模型末尾的操作可能会放在同一设备上,而两者之间的操作位于不同的设备上,这意味着此设备被访问了两次。
该库提供两种不同的流水线计划,简单调度和交错排程,可以使用 Pyth SageMaker on SDK 中的pipeline参数进行配置。在大多数情况下,交错流水线可以通过 GPUs 更有效地利用流水线来实现更好的性能。
交错管道
在交错管道中,尽可能优先考虑向后执行微批次。这样可以更快地释放内存用于激活,从而更有效地使用内存。它还允许扩大微粒的数量,从而缩短微粒的闲置时间。 GPUs在稳态下,每个设备在向前传递和向后传递之间交替运行。这意味着一个微批次的向后传递可能会在另一个微批次的向前传递完成之前运行。

上图说明了超过 2 的交错管道的执行计划示例。 GPUs在图中,F0 表示微批次 0 的向前传递,B1 表示微批次 1 的向后传递。更新表示优化器对参数的更新。GPU0 始终尽可能优先考虑向后传递(例如,在 F2 之前执行 B0),这样可以清除在之前激活中使用的内存。
简单管道
相比之下,简单管道则为每个微批次运行向前传递,然后再开始向后传递。这意味着它仅对自身中的向前传递和向后传递阶段进行管道传输。下图说明了其工作原理的示例,超过 2 GPUs.

特定框架中的管道执行
使用以下章节来了解特定于框架的管道调度决策 SageMaker的模型并行度库对和的影响。 TensorFlow PyTorch
使用管道执行 TensorFlow
下图是使用自动模型拆分由模型并行度库划分的 TensorFlow 图形的示例。拆分图形时,生成的每个子图形都会被复制 B 次(变量除外),其中 B 是微批次的数量。在此图中,每个子图形被复制 2 次 (B=2)。在子图形的每个输入中插入一个 SMPInput 运算,在每个输出中插入一个 SMPOutput 运算。这些操作与库后端通信,以在彼此之间传输张量。

下图是 2 个子图形的示例,以 B=2 进行拆分,并添加了梯度运算。SMPInput 运算的梯度是 SMPOutput 运算,反之亦然。这使梯度能够在反向传播期间向后流动。
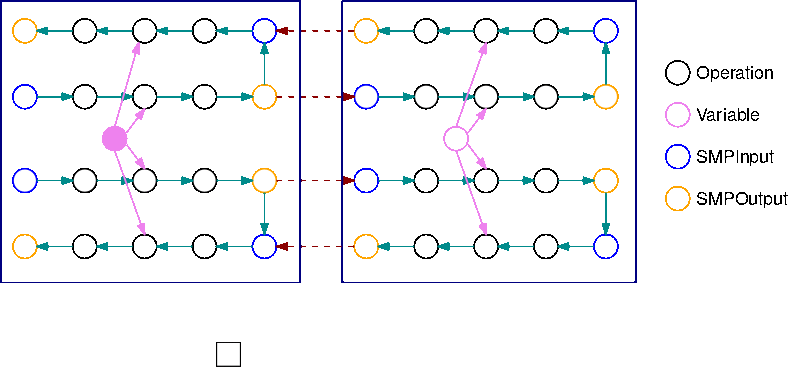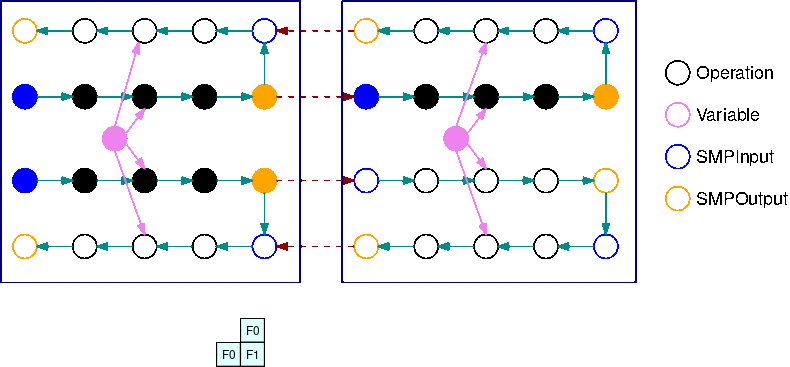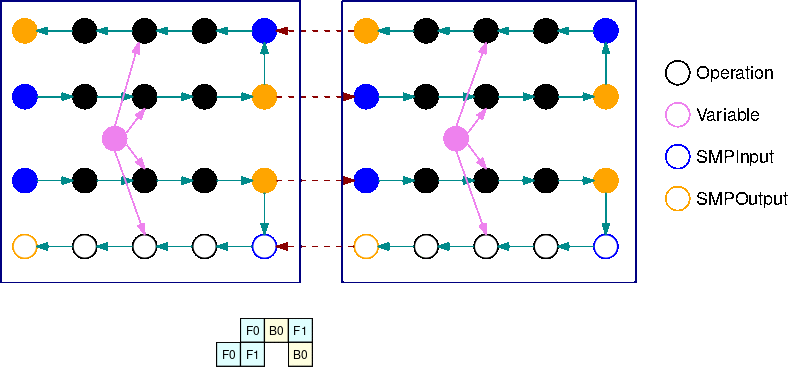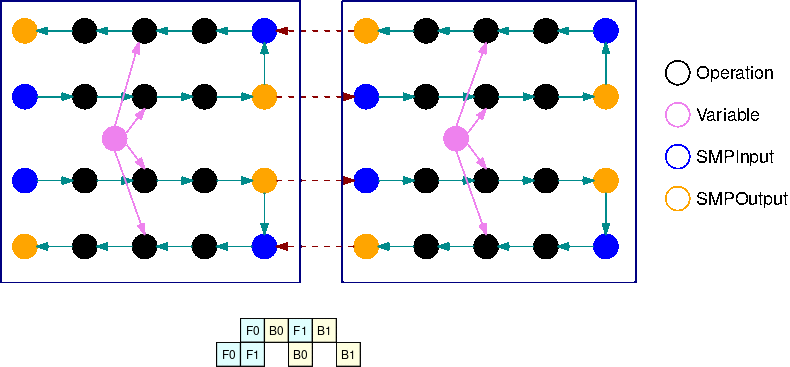
此 GIF 演示了一个示例交错管道执行计划,其中 B=2 个微批次和 2 个子图形。每个设备按顺序执行其中一个子图形副本,以提高 GPU 利用率。随着 B 增大,空闲时段的比例趋近于零。每当需要对特定的子图形副本执行(向前或向后)计算时,管道层都会向相应的蓝色 SMPInput 运算发出信号以开始执行。
计算出单个小批次中所有微批次的梯度后,该库就会合并各个库的梯度,然后将其应用于参数。
使用管道执行 PyTorch
从概念上讲,流水线也遵循类似的想法。 PyTorch但是,由于 PyTorch 不涉及静态图,因此模型并行度库的 PyTorch 功能使用了更动态的流水线模式。
例如 TensorFlow,每个批次都被分成多个微粒,这些微批次在每个设备上一次执行一个。但是,执行计划由在每个设备上启动的执行服务器来处理。只要当前设备需要放置在另一台设备上的子模块的输出,就会向远程设备的执行服务器发送执行请求,同时将输入张量发送到该子模块。然后,服务器使用给定的输入执行此模块,并将响应返回给当前设备。
由于当前设备在远程子模块执行期间处于空闲状态,当前微批处理的本地执行暂停,库运行时系统会将执行切换到当前设备可以主动处理的另一个微批次。微批次的优先级由所选的管道计划决定。对于交错管道计划,只要有可能,就会优先考虑处于计算后退阶段的微批次。
