本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
模型训练
整个机器学习 (ML) 生命周期的训练阶段,包括从访问训练数据集到生成最终模型并选择性能最佳的模型进行部署。以下各节概述了可用的 SageMaker 培训功能和资源,并提供了每种功能和资源的深入技术信息。
SageMaker 培训的基本架构
如果您是第一次使用 SageMaker 人工智能,并且想找到一种快速的机器学习解决方案来在您的数据集中训练模型,请考虑使用无代码或低代码解决方案,例如 SageMaker Studio Classic JumpStart 中的 SageMaker Canvas 或 SageMaker Autopilot。
要获得中级编程体验,可以考虑使用 SageMaker Studio Classic 笔记本或SageMaker 笔记本实例。要开始使用,请按照 SageMaker AI 入门指南中的说明进行操作。训练模型对于使用机器学习框架创建自己的模型和训练脚本的使用案例,我们建议这样做。
SageMaker AI 作业的核心是机器学习工作负载的容器化以及管理计算资源的能力。Training 平台负责为机器学习 SageMaker 培训工作负载设置和管理基础架构相关的繁重工作。借 SageMaker 助 Training,您可以专注于开发、训练和微调模型。
以下架构图显示了 SageMaker AI 如何代表 A SageMaker I 用户管理机器学习训练任务和配置 Amazon EC2 实例。作为 A SageMaker I 用户,您可以自带训练数据集,将其保存到 Amazon S3。您可以从可用的 SageMaker AI 内置算法中选择机器学习模型训练,也可以使用使用常用机器学习框架构建的模型自带训练脚本。
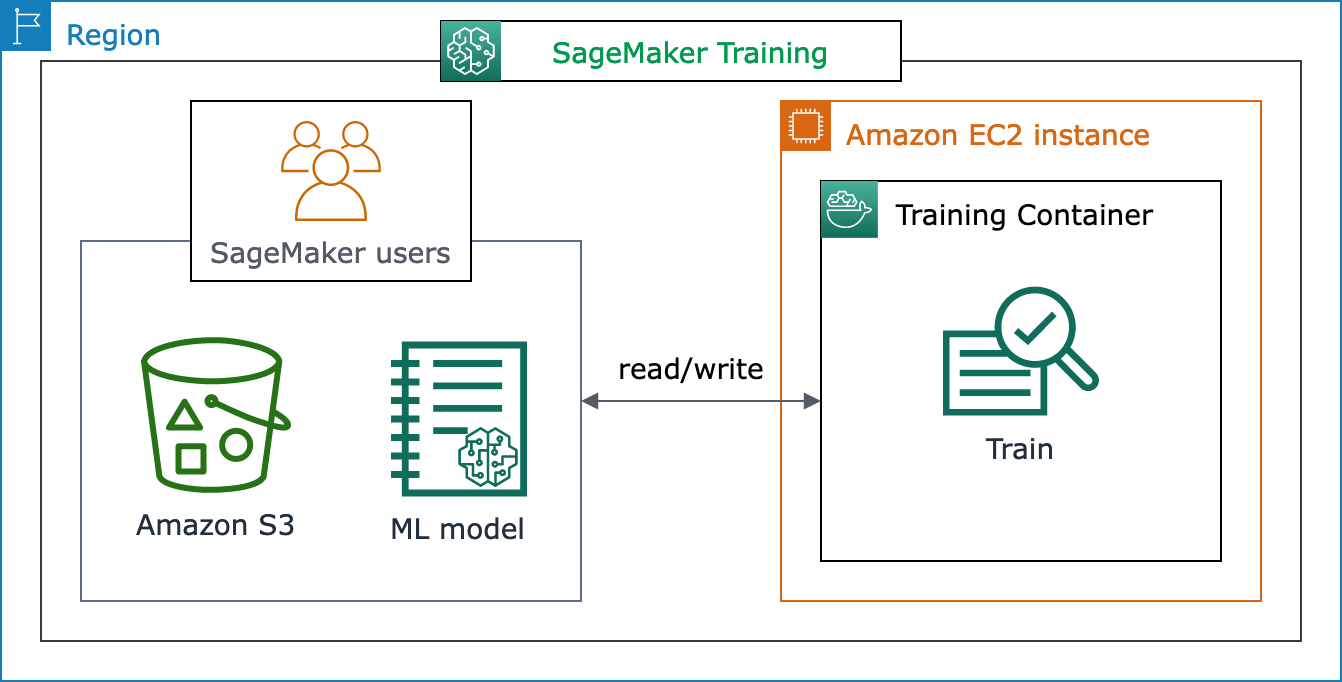
SageMaker 培训工作流程和功能的完整视图
机器学习训练的整个过程包括但不限于以下任务:将数据摄取至机器学习模型、在计算实例上训练模型,以及获取模型构件并输出。您需要评估训练前、训练期间和训练后的每个阶段,以确保模型经过良好训练,可达到预期的目标准确性。
以下流程图简要概述了您在机器学习生命周期的整个 SageMaker 训练阶段中的操作(用蓝色方框显示)和可用的培训功能(在浅蓝色方框中)。
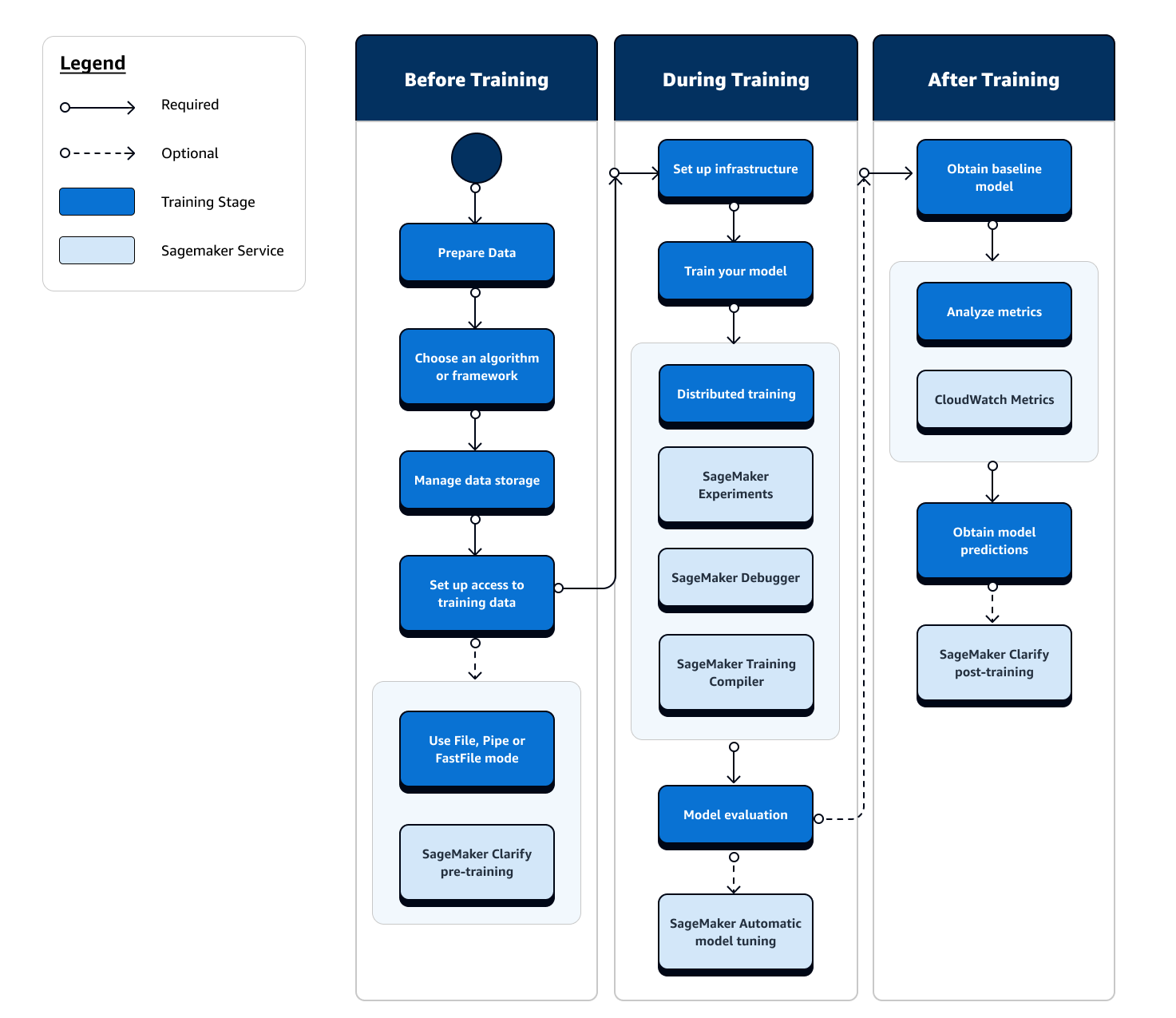
以下各节将引导您了解上一个流程图中描述的每个训练阶段,以及 SageMaker 人工智能在机器学习训练的三个子阶段中提供的有用功能。
训练前
在训练之前,您需要考虑多种设置数据资源和访问权限的场景。请参阅下图以及每个训练前阶段的详细信息,以了解您需要做出哪些决定。
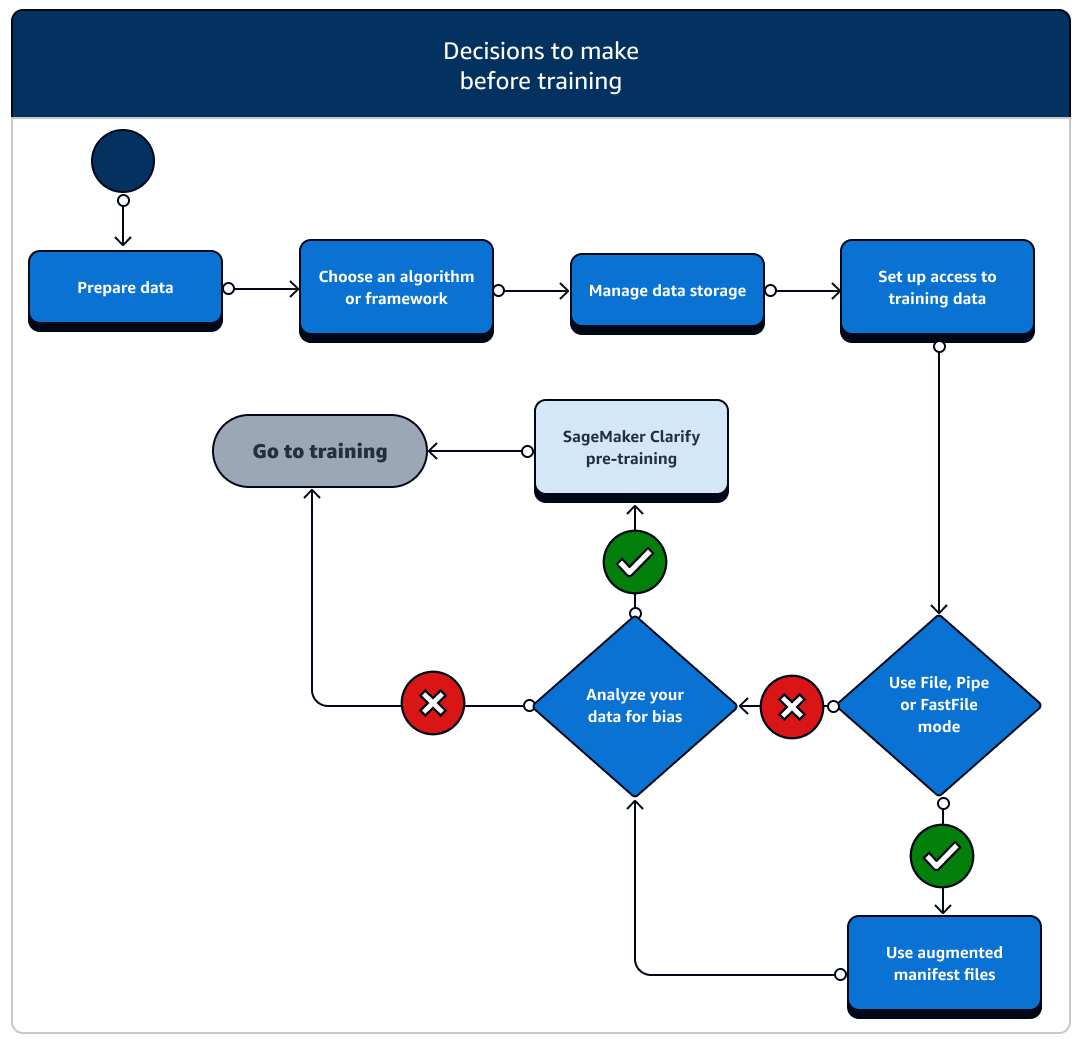
-
准备数据:在训练之前,您必须在数据准备阶段完成数据清理和特征工程。 SageMaker AI 有多种标签和功能工程工具可以帮助你。有关更多信息,请参阅标注数据、准备和分析数据集、处理数据以及创建、存储和共享特征。
-
选择算法或框架:根据您所需的自定义程度,有多种不同的算法和框架可供选择。
-
如果您更喜欢预建算法的低代码实现,请使用 AI 提供的 SageMaker 内置算法之一。有关更多信息,请参阅选择算法。
-
如果您需要更大的灵活性来自定义模型,请在 SageMaker AI 中使用首选框架和工具包运行训练脚本。有关更多信息,请参阅机器学习框架和工具包。
-
要将预先构建的 SageMaker AI Docker 镜像扩展为你自己容器的基础镜像,请参阅使用 Pre-built SageMaker AI Docker 镜像。
-
要将你的自定义 Docker 容器引入 SageMaker AI,请参阅调整你自己的 Docker 容器以与 AI 配合使用 SageMaker 。您需要将 sagemaker-training-toolkit
安装到容器中。
-
-
管理数据存储:了解数据存储(例如 Amazon S3、Amazon EFS 或 Amazon FSx)与在 Amazon EC2 计算实例中运行的训练容器之间的映射。 SageMaker AI 有助于映射训练容器中的存储路径和本地路径。您也可以手动指定。映射完成后,考虑使用其中一种数据传输模式:文件、管道和 FastFile 模式。要了解 SageMaker AI 如何映射存储路径,请参阅训练存储文件夹。
-
设置对培训数据的访问权限:使用 Amazon SageMaker AI 域、域用户个人资料、IAM、Amazon VPC,并 AWS KMS 满足对安全性最敏感的组织的要求。
-
有关账户管理的信息,请参阅 Amazon SageMaker AI 域名。
-
有关 IAM 策略和安全的完整参考,请参阅 A mazon A SageMaker I 中的安全性。
-
-
流式传输您的输入数据: SageMaker AI 提供三种数据输入模式:文件、管道和FastFile。默认输入模式为 File 模式,此模式在训练作业初始化期间加载整个数据集。要了解将数据从数据存储流式传输到训练容器的一般最佳实践,请参阅访问训练数据。
在 Pipe 模式下,您也可以考虑使用增强清单文件,直接从 Amazon Simple Storage Service (Amazon S3) 流式传输数据并训练模型。使用 Pipe 模式可以减少磁盘空间,因为 Amazon Elastic Block Store 只需要存储最终模型构件,而无需存储完整的训练数据集。有关更多信息,请参阅通过增强清单文件将数据集元数据提供给训练作业。
-
分析数据是否存在偏差:在训练之前,您可以分析您的数据集和模型中是否存在针对弱势群体的偏差,以便您可以使用 Clarify 检查模型是否学习了无偏的数据集。SageMaker
-
选择要使用的 SageMaker SDK:有两种方法可以在 SageMaker AI 中启动训练作业:使用高级 A SageMaker I Python SDK,或者使用适用于 Python SDK (Boto3) 的低级 SageMaker API 或。 AWS CLI SageMaker Python 软件开发工具包抽象了低级 SageMaker API 以提供便捷的工具。如前所述SageMaker 培训的基本架构,你还可以使用 Canvas、 SageMaker Studio Cl SageMaker as sic 或 AI Autopilot 使用无代码或SageMaker 最少代码选项。JumpStart
训练期间
在训练期间,您需要不断提高训练稳定性、训练速度和训练效率,同时扩展计算资源、优化成本,最重要的是提高模型性能。请继续阅读以获取有关训练阶段和相关 SageMaker 训练功能的更多信息。
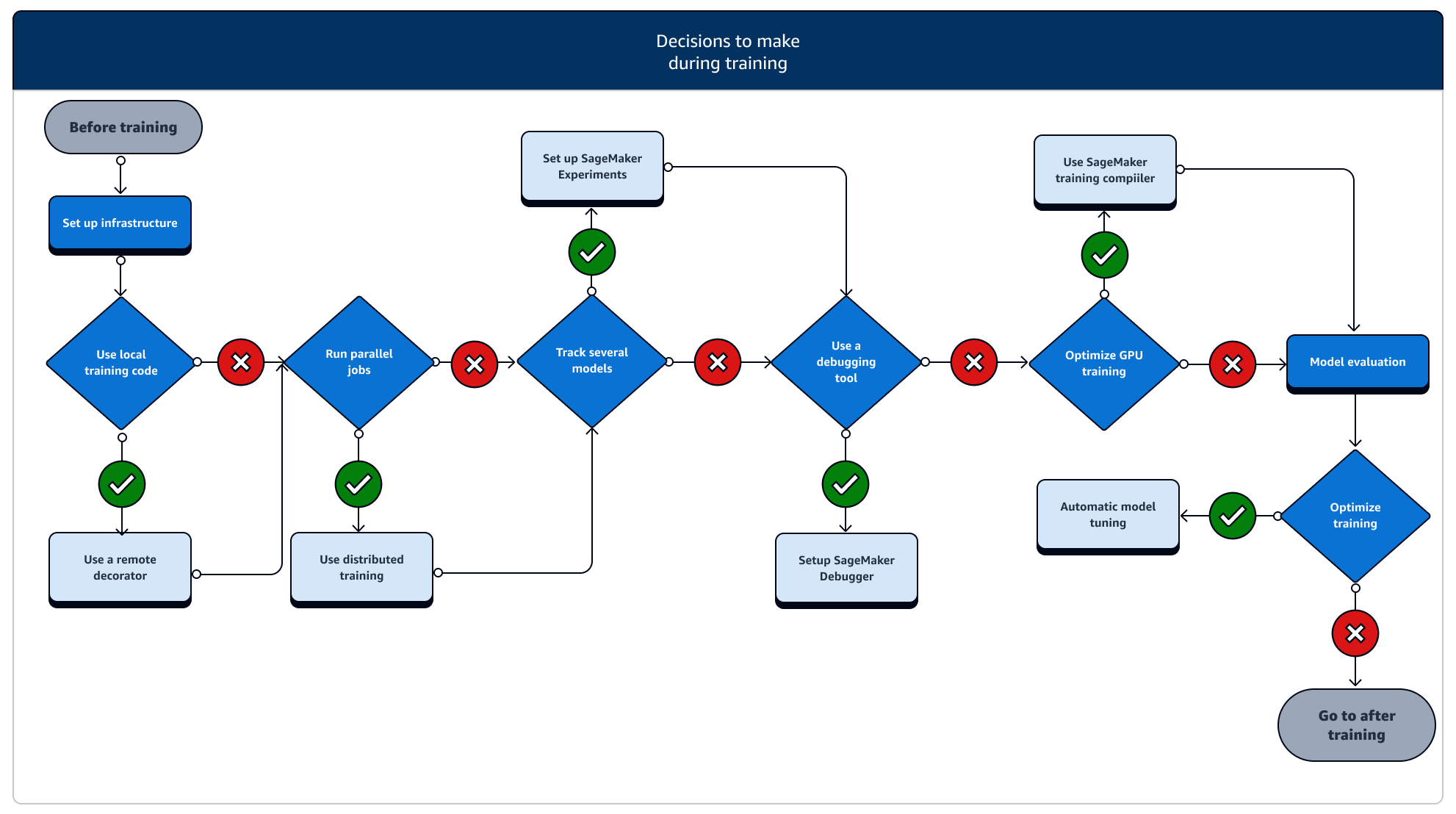
-
设置基础设施:为使用案例选择正确的实例类型和基础设施管理工具。可以从小实例开始,然后根据工作负载纵向扩展。如果在表格数据集中训练模型,可从 C4 或 C5 实例系列中最小 CPU 实例开始。如果是训练计算机视觉或自然语言处理的大型模型,可从 P2、P3、G4dn 或 G5 实例系列中最小 GPU 实例开始。您还可以在集群中混合不同的实例类型,或者使用 SageMaker AI 提供的以下实例管理工具将实例保留在温池中。您还可以使用持久缓存来减少迭代训练作业的延迟和计费时间,而不是仅通过暖池减少延迟。要了解更多信息,请参阅以下主题。
必须有足够的限额才能运行训练作业。如果在限额不足的实例上运行训练作业,则会收到
ResourceLimitExceeded错误。要查看您账户中当前可用的限额,可使用服务限额控制台。要了解如何请求增加限额,请参阅支持的区域和限额。此外,要根据查找定价信息和可用实例类型 AWS 区域,请查看 Amazon SageMaker Pricing 页面中的表格。 -
使用本地代码@@ 运行训练作业:您可以使用远程装饰器对本地代码进行注释,以便在 Amazon SageMaker Studio Classic、Amazon SageMaker 笔记本或本地集成开发环境中将代码作为 SageMaker 训练作业运行。有关更多信息,请参阅 将你的本地代码当作 SageMaker 训练作业来运行。
-
跟踪训练作业:使用 SageMaker 实验、 SageMaker 调试器或 Amazon CloudWatch 监控和跟踪您的训练作业。您可以观察模型在准确性和收敛性方面的性能,并使用 SageMaker AI Experiments 对多个训练作业之间的指标进行比较分析。您可以使用 D SageMaker ebugger 的分析工具或 Amazon CloudWatch 来查看计算资源利用率。要了解更多信息,请参阅以下主题。
此外,对于深度学习任务,可以使用 Amazon SageMaker Debugger 模型调试工具和内置规则来识别模型收敛和权重更新过程中更复杂的问题。
-
分布式训练:如果训练作业进入稳定阶段,不会因训练基础设施配置错误或内存不足问题而中断,您可能希望找到更多选项以扩展作业,并在数天甚至数月的较长时间内运行作业。当你准备好扩大规模时,可以考虑分布式训练。 SageMaker AI 为分布式计算提供了各种选项,从轻型 ML 工作负载到繁重的深度学习工作负载。
对于涉及在非常大的数据集上训练超大型模型的深度学习任务,可以考虑使用 SageMaker AI 分布式训练策略之一来扩大规模,实现数据并行性、模型并行性或两者的组合。您还可以使用SageMaker 训练编译器在 GPU 实例上编译和优化 GPU 实例上的模型图。这些 SageMaker AI 功能支持深度学习框架 PyTorch,例如 TensorFlow、和 Hugging Face Transformers。
-
模型超参数调整:使用带有 SageMaker AI 的自动模型调整来调整模型超参数。 SageMaker AI 提供网格搜索和贝叶斯搜索等超参数调整方法,启动具有提前停止功能的并行超参数调整作业,用于未改进的超参数调整作业。
-
竞价型实例的检查点功能及成本节约:如果训练时间不是大问题,那么可以考虑使用托管的竞价型实例,优化模型训练成本。请注意,必须激活竞价型训练的检查点功能,才能继续从因竞价型实例替换而导致的间歇性作业暂停中恢复。您还可以使用检查点功能备份模型,以防训练作业意外终止。要了解更多信息,请参阅以下主题。
训练后
训练结束后,您将获得最终的模型构件,以用于模型部署和推理。训练后阶段还涉及其他操作,如下图所示。
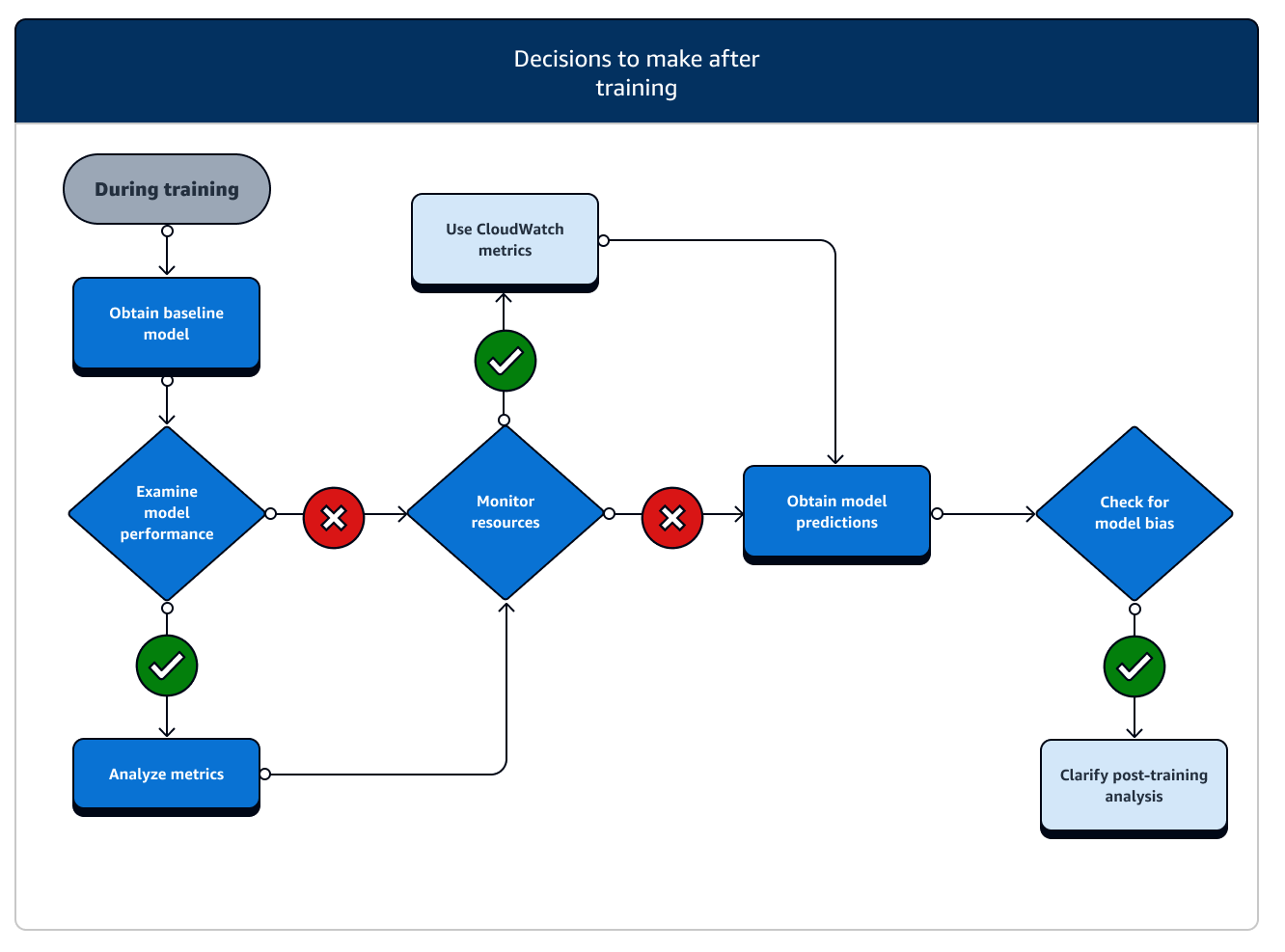
-
获取基线模型:获得模型构件后,您可以将其设置为基线模型。在将模型部署到生产环境之前,请考虑以下训练后操作和使用 SageMaker AI 功能。
-
检查模型性能并检查是否存在偏差:使用 Amazon M CloudWatch etrics 和 SageMaker Clarify 查找训练后的偏差,以检测传入数据中的任何偏差,并根据基线进行建模。您需要定期或实时评估新的数据,并根据新数据评估模型预测。通过使用这些功能,您可以收到有关数据和模型中任何剧烈变化或异常,以及逐渐变化或漂移的警报。
-
您还可以使用 SageMaker AI 的增量训练功能,使用扩展的数据集加载和更新模型(或微调)。
-
您可以将模型训练注册为 SageMaker AI Pip eline 中的一个步骤或 A SageMaker I 提供的其他工作流程功能的一部分,以便协调整个 ML 生命周期。
