本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
使用特征存放区创建、存储和共享功能
机器学习 (ML) 开发流程包括提取原始数据,将其转化为功能(ML 模型的有意义输入)。然后,这些功能会以可用于数据探索、ML 训练和 ML 推断的方式存储起来。Amazon F SageMaker eature Store 简化了您创建、存储、共享和管理功能的方式。具体做法是提供特征存放区选项,减少重复的数据处理和整理作业。
除其他功能外,您还可以使用特征存放区:
-
简化特征处理、存储、检索和共享功能,以便跨账户或在组织内进行 ML 开发。
-
跟踪特征处理代码的开发,将特征处理器应用于原始数据,并以一致的方式将功能输入特征存放区。这就减少了训练-服务偏差,这是 ML 中的一个常见问题,即训练和服务期间的性能差异会影响 ML 模型的准确性。
-
将功能和相关元数据存储在特征组中,这样就可以轻松发现和重复使用功能。特征组是可变的,在创建后可以演化其模式。
-
创建特征组,可将其配置为包括在线或离线存储,或两者兼而有之,以管理您的功能,并自动处理如何为您的 ML 任务存储功能。
-
在线存储只保留最新的功能记录。这主要是为了支持需要低毫秒级延迟读取和高吞吐量写入的实时预测。
-
离线存储将您的所有功能记录保存为历史数据库。主要用于数据探索、模型训练和批量预测。
-
下图显示了如何将特征存放区用作 ML 管道的一部分。读入原始数据后,可以使用特征存放区将原始数据转换为功能,并将其输入特征组。这些功能可以通过流式或批量方式摄取到特征组的在线和离线存储中。然后,这些功能可用于数据探索、模型训练以及实时或批量推理。
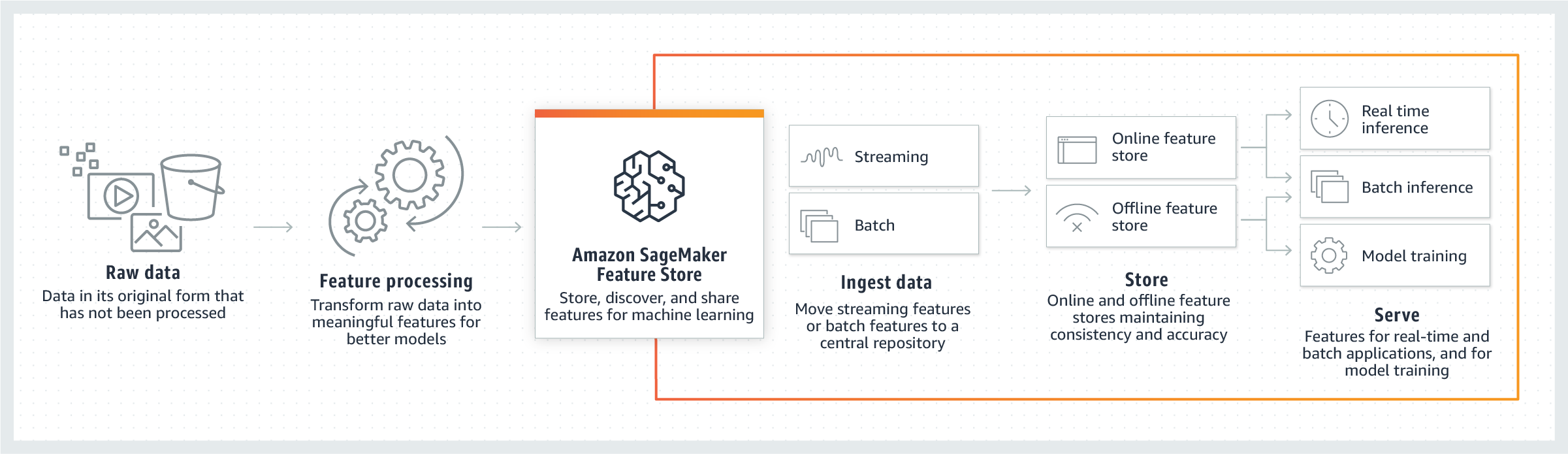
Feature Store 工作原理
在 Feature Store 中,特征存储在名为特征组 的集合中。您可以将特征组可视化为表格,其中每列都是一个特征,每行都有唯一标识符。原则上,特征组由特征和每个特征的特定值组成。Record 是与唯一 RecordIdentifier 对应的特征的值集合。总而言之,FeatureGroup 是 FeatureStore 中定义的用来描述 Record 的一组特征。
您可以在以下模式下使用 Feature Store:
-
在线 - 在在线模式下,以低延迟(毫秒)读取特征并用于高吞吐量预测。此模式要求将特征组存储到在线存储中。
-
离线 - 在离线模式下,大量数据流被馈送到离线存储,可用于训练和批量推理。此模式要求将特征组存储到离线存储中。离线存储使用您的 S3 存储桶进行存储,也可以使用 Athena 查询来获取数据。
-
在线和离线 - 这包括在线和离线两种模式。
您可以通过两种方式将数据摄取到 Feature Store 中的特征组:流式传输或批量处理。通过流式传输摄取数据时,通过调用同步 PutRecord API 调用,将一组记录推送到 Feature Store。利用此 API,您可以在 Feature Store 中维护最新的特征值,并在检测到更新后立即推送新的特征值。
或者,Feature Store 可以批量处理和摄取数据。例如,您可以使用 Amazon SageMaker Data Wrangler 创作功能,也可以从 Data Wrangler 中导出笔记本。笔记本可以是一项 SageMaker 处理作业,它将功能批量摄取到功能商店功能组。此模式允许批量摄取到离线存储。如果将特征组配置为可供在线和离线使用,则它还支持将数据摄取到在线存储。
创建特征组
要将特征摄取到 Feature Store 中,必须先定义特征组以及属于该特征组的所有特征的特征定义(特征名称和数据类型)。创建后的特征组是可变的,可使其架构发生演变。要素组名称在 AWS 区域 和中是唯一的 AWS 账户。创建特征组时,还可以创建特征组的元数据。元数据可包含简短描述、存储配置、用于识别每条记录的功能以及事件时间。此外,元数据还可以包含标签,用于存储作者、数据来源、版本等信息。
重要
FeatureGroup 名称或相关元数据(例如描述或标签)不应包含任何个人身份信息 (PII) 或机密信息。
查找、发现和共享特征
在 Feature Store 中创建特征组后,Feature Store 的其他授权用户可以共享和发现该特征组。用户可以浏览 Feature Store 中所有特征组的列表,也可以通过按特征组名称、描述、记录标识符名称、创建日期和标签进行搜索来发现现有的特征组。
Real-time 对存储在在线商店中的功能进行推断
借助 Feature Store,您可以使用来自流式传输源的数据(来自其他应用程序的干净流数据)实时丰富存储到在线存储中的特征,并以低毫秒延迟提供这些特征以进行实时推理。
您还可以通过查询客户端应用程序中的两个不同 FeatureGroups,跨不同 FeatureGroups 执行联接,以进行实时推理。
用于模型训练和批量推理的离线存储
Feature Store 为 S3 存储桶中的特征值提供离线存储。您的数据使用基于事件时间的前缀方案存储在 S3 存储桶中。离线存储是一种仅附加存储,使 Feature Store 能够维护所有特征值的历史记录。数据以 Parquet 格式存储在离线存储中,以优化存储和查询访问。
您可以从管理控制台使用 Data Wrangler 查询、探索和可视化功能。 Feature Store 支持合并数据以生成、训练、验证和测试数据集,并允许您提取不同时间点的数据。
特征数据摄取
可以创建特征生成管道来处理大批量(100 万行或更多)或小批量数据,并将特征数据写入离线或在线存储。诸如 Amazon Managed Streaming for Apache Kafka 或 Amazon Kinesis 之类的流式传输源也可用作数据源,可以从中提取特征并直接馈送到在线存储以进行训练、推理或特征创建。
您可以通过调用同步 PutRecord API 调用,将记录推送到 Feature Store。由于这是同步 API 调用,因此可以在一次 API 调用中推送小批量更新。这样就能保持特征值的高新鲜度,并在检测到更新时立即发布值。这些也称为流式处理特征。
摄取和更新特征数据后,Feature Store 会将所有特征的历史数据存储到离线存储中。对于批量摄取,您可以从 S3 存储桶中提取特征值或使用 Athena 进行查询。您还可以使用 Data Wrangler 来处理和设计新特征,然后将这些特征导出到选定 S3 存储桶,以供 Feature Store 访问。对于批量摄取,您可以配置处理作业以将数据批量摄取到 Feature Store,也可以使用 Athena 从 S3 存储桶中提取特征值。
要从在线存储中删除 Record,请使用 DeleteRecord API 调用。这也会将已删除的记录添加到离线存储。
Feature Store 中的故障恢复能力
Feature Store 分布在多个可用区 (AZ) 上。AZ 是 AWS 区域中的隔离位置。如果某些 AZ 出现故障,Feature Store 可以使用其他 AZ。有关 AZ 的更多信息,请参阅 亚马逊 A SageMaker I 的弹性。
