本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
以下几节介绍如何为每种主要类型的自定义模型构建模型。
-
要构建数值预测、2 类别预测或 3+ 类别预测模型,请参阅构建自定义的数值或分类预测模型。
-
要构建单标签图像预测模型,请参阅构建自定义图像预测模型。
-
要构建多元文本预测模型,请参阅构建自定义文本预测模型。
-
要构建时间序列预测模型,请参阅 建立时间序列预测模型。
注意
如果您在构建后分析期间遇到错误,提示您增加 ml.m5.2xlarge 实例限额,请参阅申请增加限额。
构建自定义的数值或分类预测模型
数值和分类预测模型同时支持快速构建和标准构建。
要构建数值或分类预测模型,请按以下步骤操作:
-
打开 SageMaker 画布应用程序。
-
在左侧导航窗格中,选择我的模型。
-
选择新建模型。
-
在创建新模型对话框中,执行以下操作:
-
在模型名称字段中输入名称。
-
选择预测分析问题类型。
-
选择创建。
-
-
对于选择数据集,从数据集列表中选择您的数据集。如果您尚未导入数据,请选择导入以指导您完成导入数据工作流。
-
如果您已准备好开始构建模型,请选定选择数据集。
-
在构建选项卡的目标列下拉列表中,为模型选择要预测的目标。
-
对于模型类型,Canvas 会自动为您检测问题类型。如果您要更改类型或配置高级模型设置,请选择配置模型。
当配置模型对话框打开时,执行以下操作:
对于模型类型,选择要构建的模型类型。
-
选择模型类型后,还有其他高级设置。有关各项高级设置的更多信息,请参阅 高级模型构建配置。要配置高级设置,执行以下操作:
(可选)在目标指标下拉菜单中,选择您希望 Canvas 在构建模型时优化的指标。如果您没有选择指标,Canvas 会默认为您选择一个指标。有关这些指标的说明,请参阅 指标参考。
对于训练方法,选择自动、集合或超参数优化 (HPO) 模式。
对于算法,选择要包含的用于构建候选模型的算法。
对于数据拆分,请按百分比指定如何在训练集和验证集之间如何拆分数据。训练集用于构建模型,而验证集用于测试候选模型的准确性。
-
对于最大候选数和运行时,执行以下操作:
设置最大候选数值或 Canvas 可以生成的候选模型的最大数量。请注意,最大候选值仅在 HPO 模式下可用。
为最大作业运行时设置小时和分钟值,或者 Canvas 可以用于构建模型的最长时间。超过最长时间后,Canvas 会停止构建,并选择最佳候选模型。
配置完高级设置后,选择保存。
-
选择或取消选择数据中的列,以便在构建时包含或删除这些列。
注意
如果您在构建模型后使用模型进行批量预测,Canvas 会将删除的列添加到您的预测结果中。但是,Canvas 不会将删除的列添加到时间序列模型的批量预测中。
-
(可选)使用 Canvas 提供的可视化和分析工具将数据可视化,并确定您可能希望在模型中包含哪些特征。有关更多信息,请参阅探索和分析数据。
-
(可选)使用数据转换功能来清理、转换和准备用于构建模型的数据。有关更多信息,请参阅使用高级转换准备数据。您可以通过选择模型配方打开模型配方侧面板来查看和移除转换。
-
(可选)有关其他功能,如预览模型的准确性、验证数据集以及更改 Canvas 从数据集中抽取的随机样本的大小,请参阅预览模型。
-
查看数据并对数据集进行任何更改后,选择快速构建或标准构建,开始构建模型。以下屏幕截图显示了构建页面以及快速构建和标准构建选项。
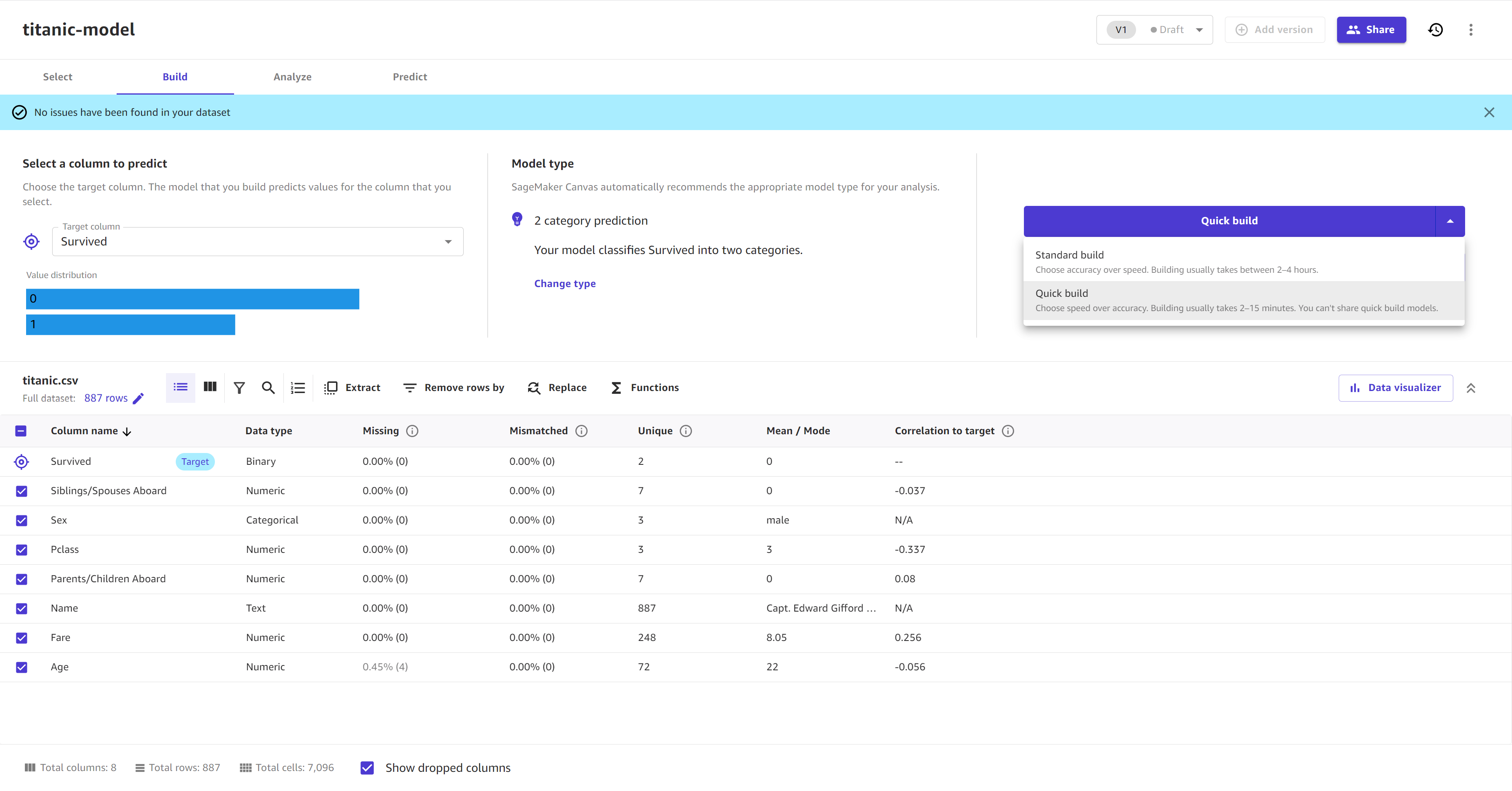
模型开始构建后,您可以离开此页面。当模型在我的模型页面上显示为就绪时,即可进行分析和预测。
构建自定义图像预测模型
单标签图像预测模型同时支持快速构建和标准构建。
要构建单标签图像预测模型,请按以下步骤操作:
-
打开 SageMaker 画布应用程序。
-
在左侧导航窗格中,选择我的模型。
-
选择新建模型。
-
在创建新模型对话框中,执行以下操作:
-
在模型名称字段中输入名称。
-
选择图像分析问题类型。
-
选择创建。
-
-
对于选择数据集,从数据集列表中选择您的数据集。如果您尚未导入数据,请选择导入以指导您完成导入数据工作流。
-
如果您已准备好开始构建模型,请选定选择数据集。
-
在构建选项卡上,您可以看到数据集中图像的标签分布。模型类型设置为单标签图像预测。
-
在此页面上,您可以预览图像并编辑数据集。如果您有任何未标注的图像,请选择编辑数据集和向未标注的图像分配标签。您还可以在编辑图像数据集时执行其他任务,例如重命名标签和向数据集添加图像。
-
查看数据并对数据集进行任何更改后,选择快速构建或标准构建,开始构建模型。以下屏幕截图显示了准备构建的图像预测模型的构建页面。
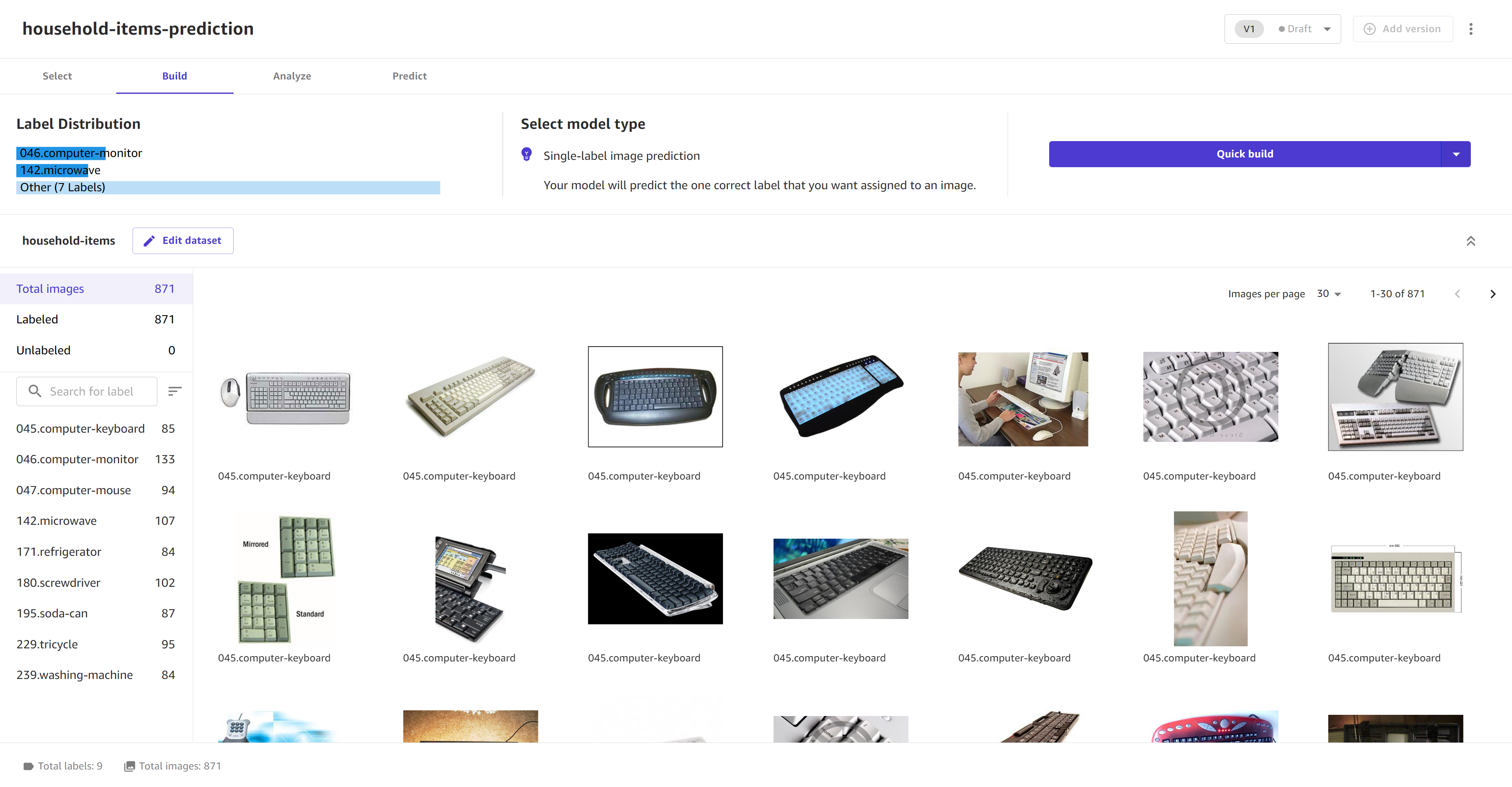
模型开始构建后,您可以离开此页面。当模型在我的模型页面上显示为就绪时,即可进行分析和预测。
构建自定义文本预测模型
多元文本预测模型同时支持快速构建和标准构建。
要构建文本预测模型,请按以下步骤操作:
-
打开 SageMaker 画布应用程序。
-
在左侧导航窗格中,选择我的模型。
-
选择新建模型。
-
在创建新模型对话框中,执行以下操作:
-
在模型名称字段中输入名称。
-
选择文本分析问题类型。
-
选择创建。
-
-
对于选择数据集,从数据集列表中选择您的数据集。如果您尚未导入数据,请选择导入以指导您完成导入数据工作流。
-
如果您已准备好开始构建模型,请选定选择数据集。
-
在构建选项卡的目标列下拉列表中,为模型选择要预测的目标。目标列必须具有二进制或分类数据类型,并且目标列中的每个唯一标签必须至少有 25 个条目(或数据行)。
-
对于模型类型,确认模型类型自动设置为多元文本预测。
-
对于训练列,选择文本数据的源列。这应该是包含要分析的文本的列。
-
选择快速构建或标准构建,开始构建模型。以下屏幕截图显示了准备构建的文本预测模型的构建页面。
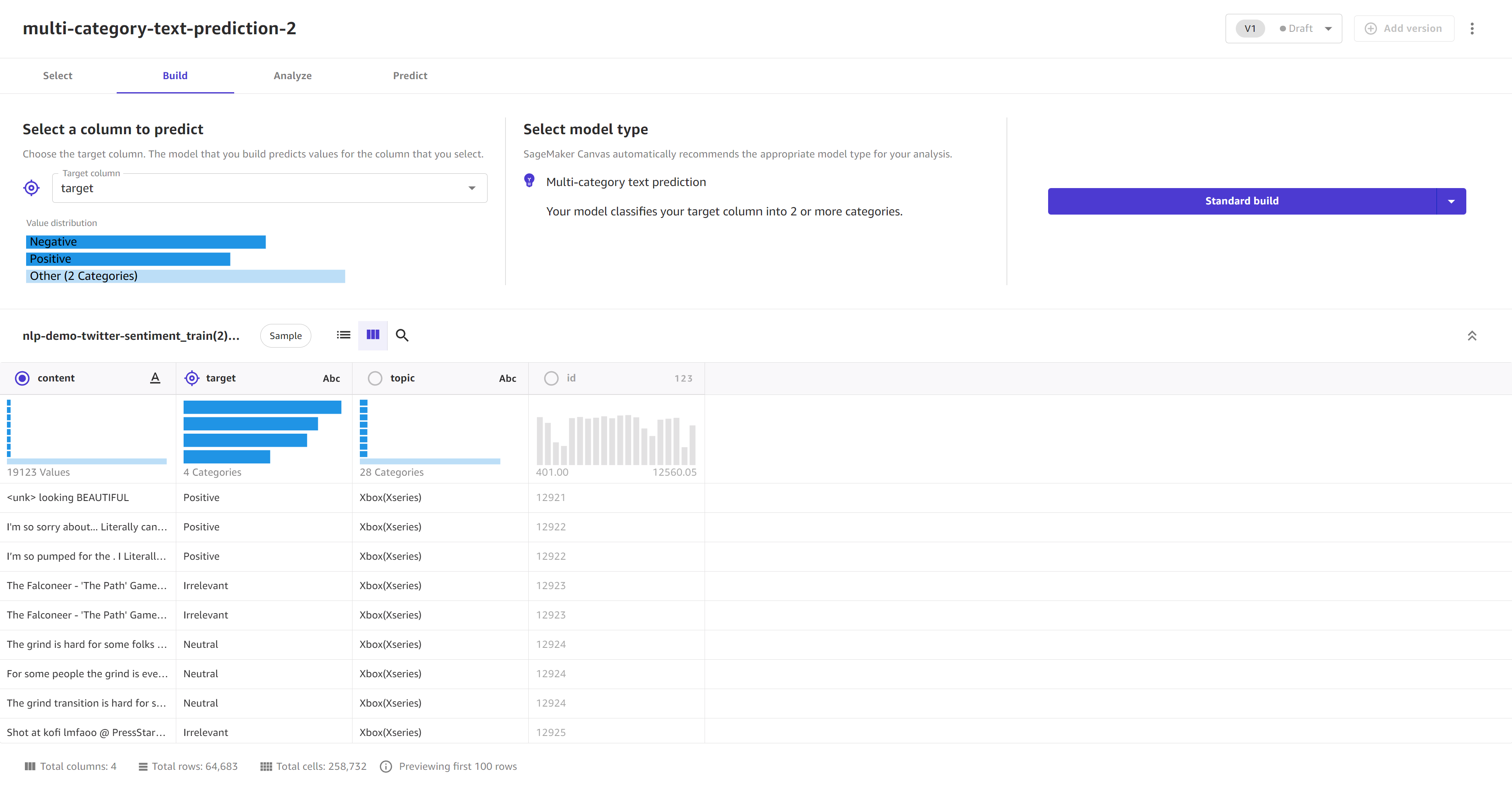
模型开始构建后,您可以离开此页面。当模型在我的模型页面上显示为就绪时,即可进行分析和预测。
建立时间序列预测模型
时间序列预测模型支持快速构建和标准构建。
要建立时间序列预测模型,请按照以下步骤操作:
-
打开 SageMaker 画布应用程序。
-
在左侧导航窗格中,选择我的模型。
-
选择新建模型。
-
在创建新模型对话框中,执行以下操作:
-
在模型名称字段中输入名称。
-
选择时间序列预测问题类型。
-
选择创建。
-
-
对于选择数据集,从数据集列表中选择您的数据集。如果您尚未导入数据,请选择导入以指导您完成导入数据工作流。
-
如果您已准备好开始构建模型,请选定选择数据集。
-
在构建选项卡的目标列下拉列表中,为模型选择要预测的目标。
在模型类型部分,选择配置模型。
-
此时将打开配置模型框。在时间序列配置部分,填写以下字段:
在项目 ID 列中,选择数据集中唯一标识每一行的列。
(可选)在分组列中,选择一个或多个用于对预测值进行分组的分类列。
对于时间戳列,选择带有时间戳(采用日期时间格式)的列。有关可接受的日期时间格式的更多信息,请参阅 Amazon C SageMaker anvas 中的时间序列预测。
在预测长度字段中,输入您想要预测值的时间段。Canvas 会自动检测数据中的时间单位。
(可选)打开使用假期时间表开关,选择不同国家/区域的假期时间表,使您的假期数据预测更加准确。
-
在配置模型框中,高级部分还有其他设置。有关各项高级设置的更多信息,请参阅 高级模型构建配置。要配置高级设置,执行以下操作:
在目标指标下拉菜单中,选择您希望 Canvas 在构建模型时优化的指标。如果您没有选择指标,Canvas 会默认为您选择一个指标。有关这些指标的说明,请参阅 指标参考。
-
如果您运行的是标准构建,则您会看到算法部分。本部分用于选择您要用于构建模型的时间序列预测算法。您可以从可用算法中选择一个子集,如果您不确定要尝试哪些算法,也可以选择所有算法。
当您运行标准构建时,Canvas 会构建一个集合模型,将所有算法结合在一起,以优化预测准确性。
注意
如果您正在运行快速构建,Canvas 会使用一种基于树的学习算法来训练您的模型,您无需选择任何算法。
对于预测分位数,最多输入 5 个以逗号分隔的分位数,以指定预测的上下限。
配置完高级设置后,选择保存。
-
选择或取消选择数据中的列,以便在构建时包含或删除这些列。
注意
如果您在构建模型后使用模型进行批量预测,Canvas 会将删除的列添加到您的预测结果中。但是,Canvas 不会将删除的列添加到时间序列模型的批量预测中。
-
(可选)使用 Canvas 提供的可视化和分析工具将数据可视化,并确定您可能希望在模型中包含哪些特征。有关更多信息,请参阅探索和分析数据。
-
(可选)使用数据转换功能来清理、转换和准备用于构建模型的数据。有关更多信息,请参阅使用高级转换准备数据。您可以通过选择模型配方打开模型配方侧面板来查看和移除转换。
-
(可选)有关其他功能,如预览模型的准确性、验证数据集以及更改 Canvas 从数据集中抽取的随机样本的大小,请参阅预览模型。
-
查看数据并对数据集进行任何更改后,选择快速构建或标准构建,开始构建模型。
模型开始构建后,您可以离开此页面。当模型在我的模型页面上显示为就绪时,即可进行分析和预测。
