本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
Amazon SageMaker AI 模型品質報告 (也稱為效能報告) 為 AutoML 任務產生的最佳模型候選項目提供洞見和品質資訊。這包括任務詳細資訊、模型問題類型、目標函式,以及與問題類型相關的其他資訊。本指南說明如何以圖形方式檢視 Amazon SageMaker AI Autopilot 效能指標,或將指標做為 JSON 檔案中的原始資料檢視。
例如,在分類問題中,模型品質報告包括下列項目:
-
混淆矩陣
-
接收者操作特性曲線 (AUC) 下的區域
-
說明誤報和漏報的資訊
-
真陽性和誤報之間的權衡
-
精確度和召回率之間的權衡
Autopilot 還為所有候選模型提供效能指標。這些指標是利用所有訓練資料計算而得,並用來估算模型效能。根據預設值,主要工作區域包括這些指標。指標類型取決於要解決的問題類型。
如需 Autopilot 支援的可用指標清單,請參閱 Amazon SageMaker API 參考文件。
您可以使用相關指標對模型候選項進行排序,以幫助您選擇和部署滿足商業需求的模型。有關這些指標的定義,請參閱自動駕駛儀候選指標主題。
若要檢視 Autopilot 任務中的成效報告,請依照下列步驟執行:
-
從左側導覽窗格中選擇首頁圖示 (
 ),以檢視最上層的 Amazon SageMaker Studio Classic 導覽選單。
),以檢視最上層的 Amazon SageMaker Studio Classic 導覽選單。 -
從主要工作區域中,選取 AutoML 卡片。這會開啟新的 Autopilot 索引標籤。
-
在名稱欄位中,選取您想要檢閱詳細資訊的 Autopilot 任務。這將開啟新的 Autopilot 任務索引標籤。
-
在 Autopilot 任務面板中,每個模型旁的模型名稱下都會列出該模型的指標值,包括目標指標。最佳模型會列在模型名稱下的清單頂端,並在模型索引標籤中強調顯示。
-
若要檢閱模型詳細資訊,請選取您感興趣的模型,然後選取在模型詳細資訊中檢閱。這會開啟新的模型詳細資訊索引標籤。
-
-
選擇解釋和成品索引標籤之間的效能索引標籤。
-
在索引標籤的右上方區段中,選取下載效能報告按鈕上的向下箭頭。
-
向下箭頭提供兩個選項來檢閱 Autopilot 效能指標:
-
您可以下載效能報告的 PDF,以圖形方式檢視指標。
-
您可以以原始資料檢視指標,並將其下載為 JSON 檔案。
-
-
如需如何在 SageMaker Studio Classic 中建立和執行 AutoML 任務的說明,請參閱 使用 AutoML API 為表格式資料建立迴歸或分類任務。
效能報告包含兩個區段。第一節包含產生該模型的 Autopilot 任務詳細資訊。第二節包含模型品質報告。
Autopilot 任務詳細資訊
報告的第一節提供有關產生該模型的 Autopilot 任務之部分一般資訊。這些任務詳細資訊包含下列資訊:
-
Autopilot 候選項名稱
-
Autopilot 任務名稱
-
問題類型
-
目標指標
-
最佳化方向
模型品質報告
模型品質資訊是由 Autopilot 模型深入解析所產生。產生的報告內容取決於所處理的問題類型:迴歸、二元分類或多類別分類。此報告會指定評估資料集中包含的資料列數量,以及進行評估的時間。
指標資料表
模型品質報告的第一部份包含指標資料表。這些適用於模型所解決的問題類型。
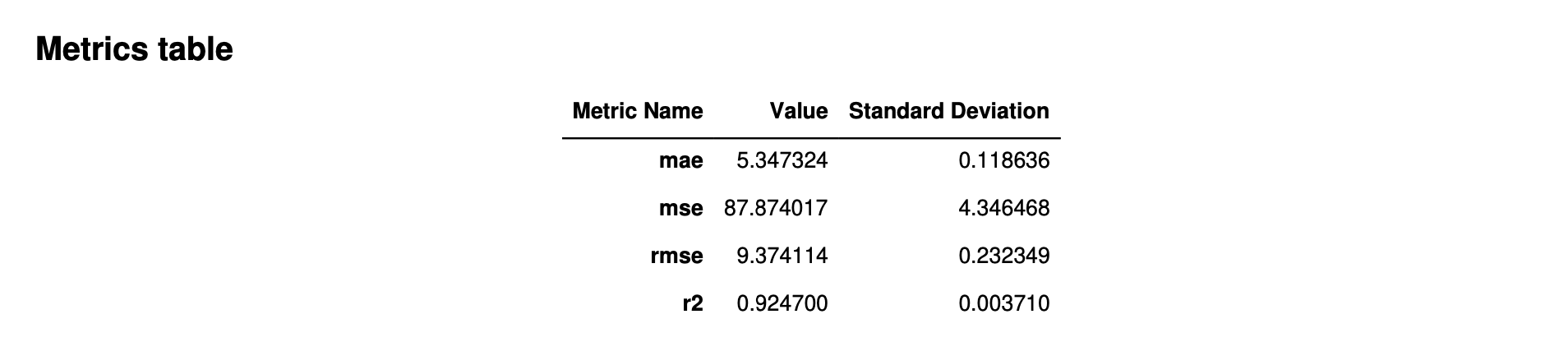
下列影像是 Autopilot 針對迴歸問題所產生的指標資料表範例。其顯示指標名稱,值和標準差。
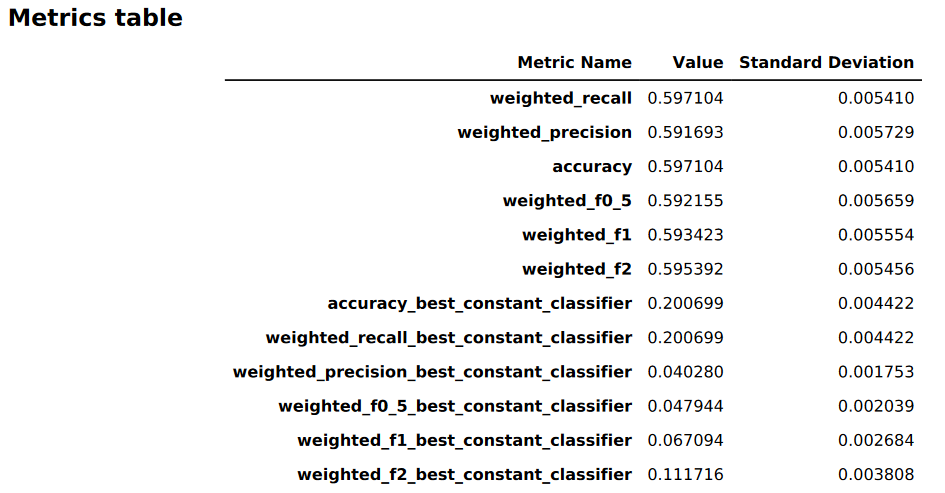
下列影像是 Autopilot 針對多類別分類問題所產生的指標表格範例。其顯示指標名稱,值和標準差。
圖形化模型效能資訊
模型品質報告的第二部分包含圖形資訊,可協助您評估模型效能。本節的內容取決於建模中使用的問題類型。
接收者操作特性曲線下的區域
接收者操作特性曲線下的區域,代表真陽性和假陽性率之間的權衡。它是用於二元分類模型的業界標準準確性指標。AUC (曲線下方區域) 會測量模型在預測較高分數之正確範例與錯誤範例上的能力,並將兩者相比較。AUC 指標會針對所有可能的分類臨界值,提供模型效能的彙總測量。
AUC 指標會傳回介於 0 至 1 的小數值。接近 1 的 AUC 值代表機器學習模型準確性很高。值接近 0.5 表示模型與隨機猜測差不多。接近 0 的 AUC 值表示模型已經學會了正確的模式,但正在進行盡可能不準確的預測。接近零的值可能表示資料有問題。如需 AUC 指標的更多相關資訊,請參閱 Wikipedia 上的接收者操作特性
以下是接收者操作特性曲線圖下的區域範例,用於評估二元分類模型所做的預測。細虛線代表接收者操作特性曲線下的區域,該區域將不優於隨機猜測進行分類的模型進行評分,AUC 得分為 0.5。更精確的分類模型的曲線位於此隨機基準線之上,其中真陽性的比率超過假陽性率。接收者操作特性曲線下方,代表二元分類模型效能的區域是較粗的實線。
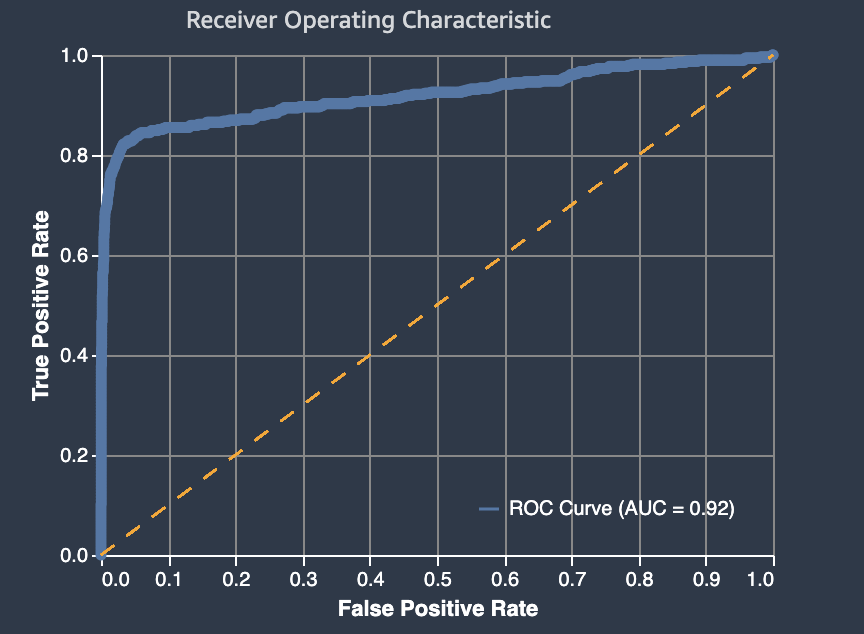
假陽性率 (FPR) 和真陽性率 (TPR) 圖形元件的摘要定義如下。
-
正確預測
-
真陽性 (TP):預測值為 1,而真值為 1。
-
True negative (TN):預測值為 0,而 true 值為 0。
-
-
錯誤預測
-
False positive (FP):預測值為 1,但真實值為 0。
-
False negative (FN):預測值為 0,但真實值為 1。
-
假陽性率 (FPR) 將 FP 和 TN 加總,測量被錯誤地預測為陽性 (FP) 的真陰性 (TN) 部分。範圍介於 0 至 1 之間。值愈小表示預測正確性愈佳。
-
FPR = FP/(FP+TN)
真陽性率 (TPR) 將 TP 和假陰性 (FN) 加總,測量被正確地預測為陽性 (TP) 的真陽性 (TN) 部分。範圍介於 0 至 1 之間。值越大,表示預測準確性越高。
-
TPR = TP/(TP+FN)
混淆矩陣
混淆矩陣提供了一種方法,將二元和多類分類不同問題的模型所做的預測準確度視覺化。模型品質報告中的混淆矩陣包含下列項目。
-
實際標籤的正確和不正確預測的數量和百分比
-
從左上角到右下角的對角線上,準確預測的數量和百分比
-
從右上角到左下角的對角線上,不準確預測的數量和百分比
混淆矩陣上的不正確預測是混淆值。
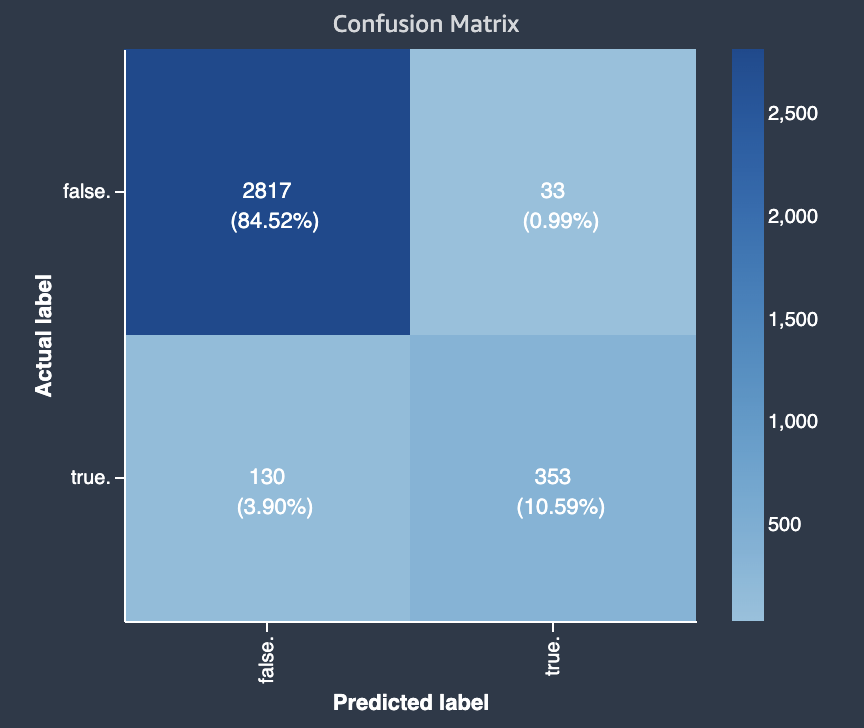
下圖示範二元分類問題的混淆矩陣。其中包含下列資訊:
-
垂直軸分為兩行,包含真與假的實際標籤。
-
水平軸分為兩列,包含由模型預測真與假的標籤。
-
色彩條會將較深的色調指定給較大數量的樣本,以視覺化方式指出在每個類別中分類值的數量。
在此範例中,模型正確預測了 2817 個實際假值,以及 353 個實際真值。該模型錯誤地將 130 個實際為真的預測為假,將 33 個實際假值預測為真。色調的差異表示資料集不平衡。不平衡是因為實際的假標籤數量比實際的真標籤數量更多。
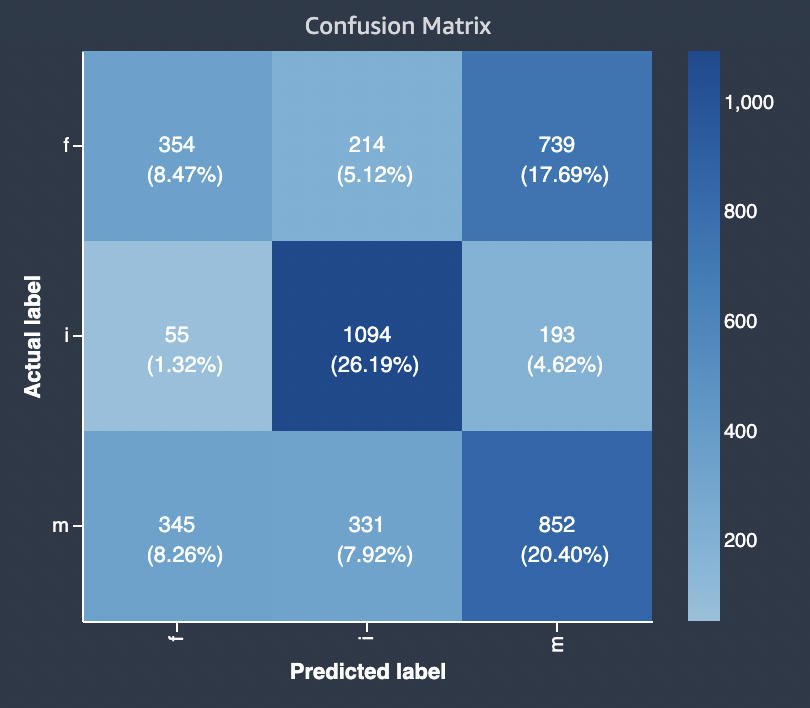
下圖示範多類別分類問題的混淆矩陣。模型品質報告中的混淆矩陣包含下列項目。
-
垂直軸分為三行,其中包含三個不同的實際標籤。
-
水平軸分為三列,其中包含由模型預測的標籤。
-
色彩列會將較深的色調指定給較大數量的樣本,以視覺方式指出在每個品類中分類的值數量。
在以下範例中,模型正確地預測了標籤 f 的實際 354 個值,標籤 i 為 1094 值,標籤 m 為 852 值。色調的差異表示資料集不平衡,因為值 i 比 f 或 m 有更多的標籤。
所提供的模型品質報告中的混淆矩陣,最多可容納 15 個多類別分類問題類型的標籤。如果與標籤對應的列顯示Nan值,則表示用於檢查模型預測的驗證資料集不包含具有該標籤的資料。
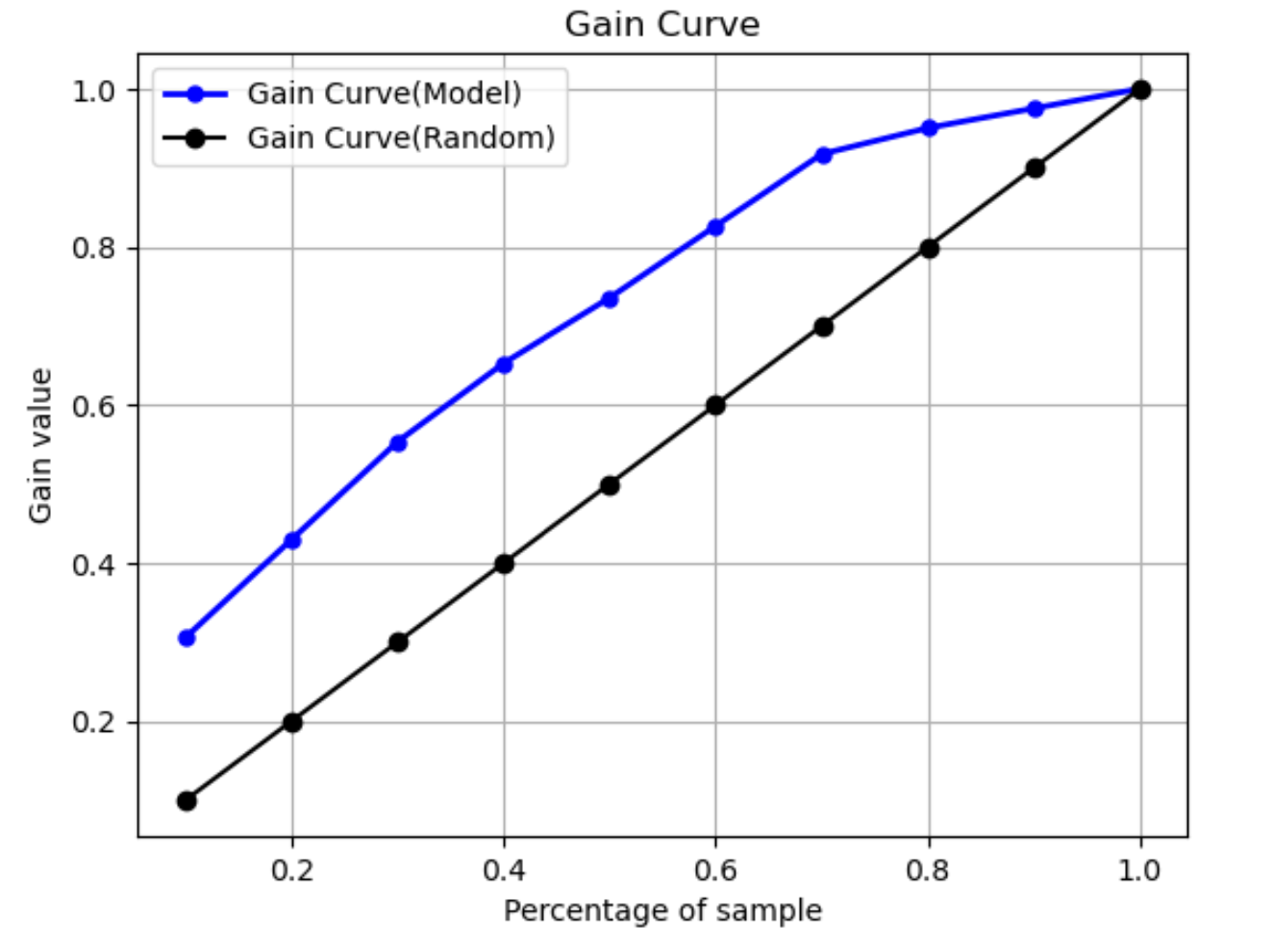
增益曲線
在二元分類中,增益曲線預測使用資料集的一定百分比來找到正面標籤的累積效益。增益值是在訓練過程中計算的,方法是在每個十分位數處,將累積的正面觀察數除以資料中正面觀察的總數。如果在訓練期間建立的分類模型代表看不見的資料,您可以使用增益曲線來預測必須定位的資料百分比,才能取得正面標籤的百分比。使用的資料集百分比越大,找到的正面標籤百分比就越高。
在下面的範例圖表中,增益曲線是具有斜率變化的線。直線是透過隨機從資料集中選擇資料的百分比,來找到正面標籤的百分比。如果目標是 20% 的資料集,可預期找到超過 40% 的正面標籤。舉個例子,您可以考慮使用增益曲線來判定您在行銷活動中的付出。使用我們的增益曲線範例,如果一個社區有 83% 的人購買餅乾,您可以向社區約 60% 的人發送廣告。
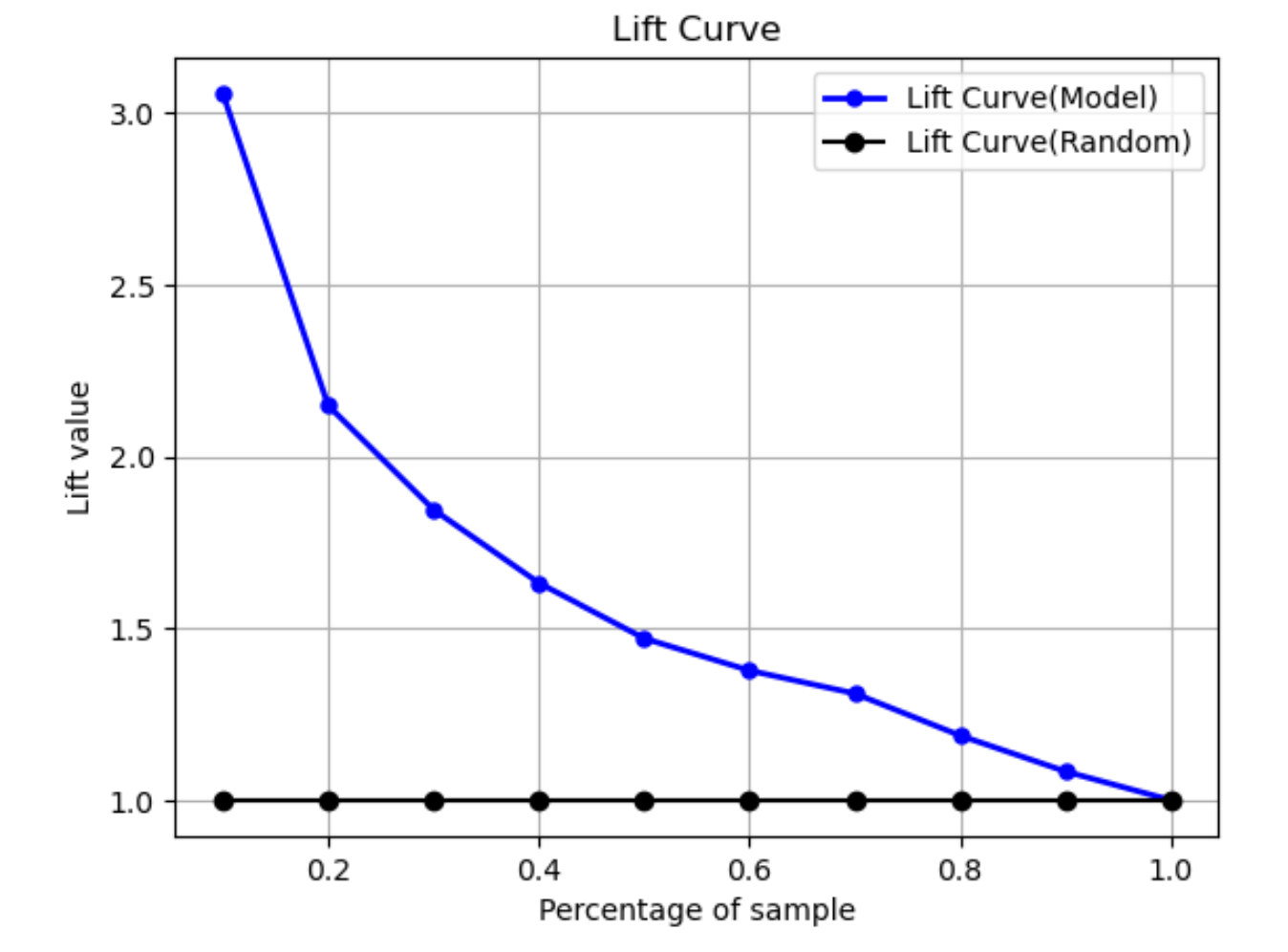
提升曲線
在二元分類中,提升曲線展示相較於隨機猜測,使用訓練過的模型來預測正面標籤的可能性提高。提升值是在訓練期間計算的,使用每個十分位數處的百分比增益與正面標籤比例的比率來計算。如果訓練期間建立的模型能夠反映出那些還沒見過的資料,可運用提升曲線來估算用這模型相較於隨便猜測的優勢。
在下面的範例圖表中,提升曲線是具有斜率變化的線。直線是與從資料集中隨機選擇對應百分比相關聯的提升曲線。當您的模型的分類標籤目標為資料集的 40%,可預期找到的正面標籤數量,將是隨機選擇未見資料 40% 所能找到的約 1.7 倍。
精確召回曲線
精確召回曲線代表在二元分類問題中,精確率與召回率之間的權衡。
精確度是在所有正面預測中 (TP 和假陽性),被預測為正面 (TP) 的實際正面比例。範圍介於 0 至 1 之間。值越大,表示預測準確性越高。
-
精確度 = TP/(TP+FP)
召回會測量在所有實際陽性預測 (TP 和偽陰性) 中預測為陽性 (TP) 的實際陽性部分。這也稱為敏感度或真陽性率。範圍介於 0 至 1 之間。較大的值表示檢測樣本中的正面值時,能獲得更好的效果。
-
召回率 = TP/ (TP+FN)
分類問題的目標是盡可能正確地標籤盡可能多的元素。具有較高召回率但精確度低的系統,會傳回高比例的誤報。
下圖描述了將每封電子郵件標記為垃圾郵件的垃圾郵件篩選器。它具有很高的召回率,但精確度低,因為召回率不會衡量誤報。
如果假陽性值對您問題的影響較輕微,但對於缺少真陽性結果較嚴重,請給予更多的權重以超過精確度。例如,偵測自動駕駛車輛中即將發生的碰撞情況。
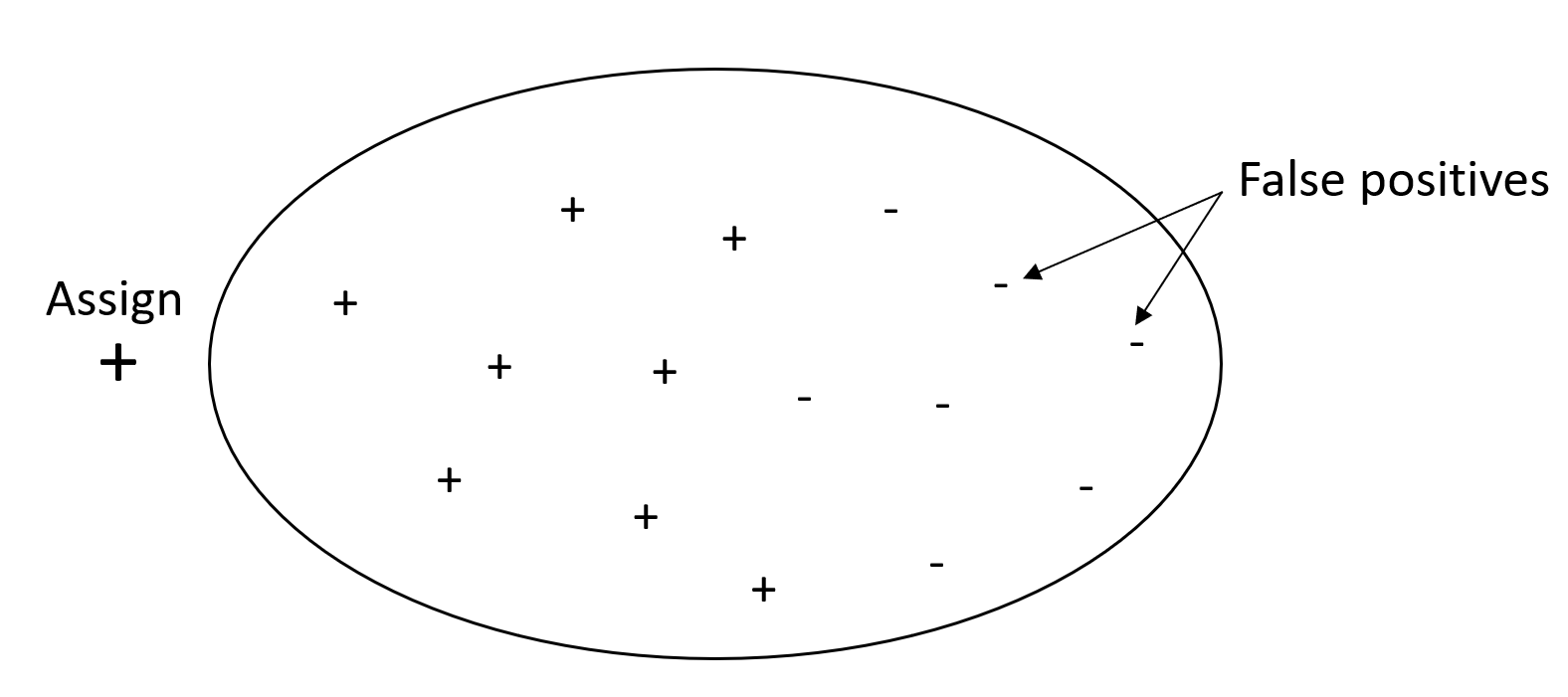
而相反地,具有高精確度但召回率低的系統,會傳回高比例的假陰性。將每封電子郵件標記為需要 (非垃圾郵件) 的垃圾郵件過濾器,其具有很高的精確度但召回率低,因為精確度不會計入誤報的情況。
如果您的問題受假陰性影響程度低,但是對缺少真陰性的影響程度高,請賦予精確度超過召回率更高的權重。例如,標記可疑過濾器以進行稅務稽核。
下圖描述了具有高精確度但召回率低的垃圾郵件篩選器,因為精確度不會計入誤報。
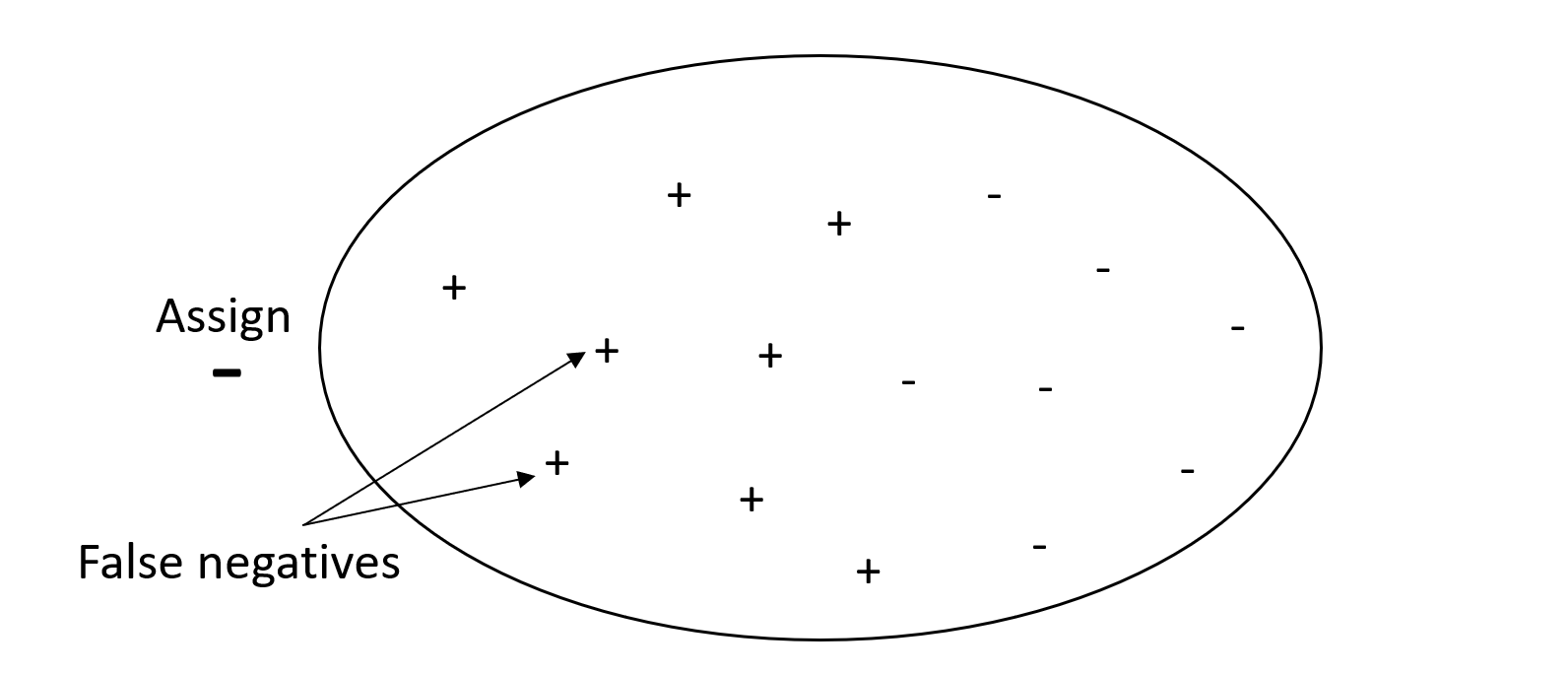
同時具有高精確度和高回收率進行預測的模型,會產生大量正確標籤的結果。如需更多資訊,請參閱 Wikipedia 中的 精確度和召回率
精確召回曲線下的區域 (AUPRC)
針對二元分類問題,Amazon SageMaker Autopilot 會包含精確回收曲線 (AUPRC) 下的區域圖表。AUPRC 指標會針對所有可能的分類閾值及精確度與召回率的使用,提供模型效能的彙總測量。AUPRC 不計入真陰性狀況的數量。因此,在資料中存在大量真陰性的情況下,評估模型效能會很有用。舉例來說,在要建構一個基因模型,且其包含的變異很少的情況下。
下圖是 AUPRC 圖形的範例。其最高值的精確度為 1,召回為 0。在圖表的右下角,召回是它的最高值 (1) 和精確度為 0。在這兩點之間,AUPRC 曲線說明了精確度和召回在不同閾值之間的權衡。
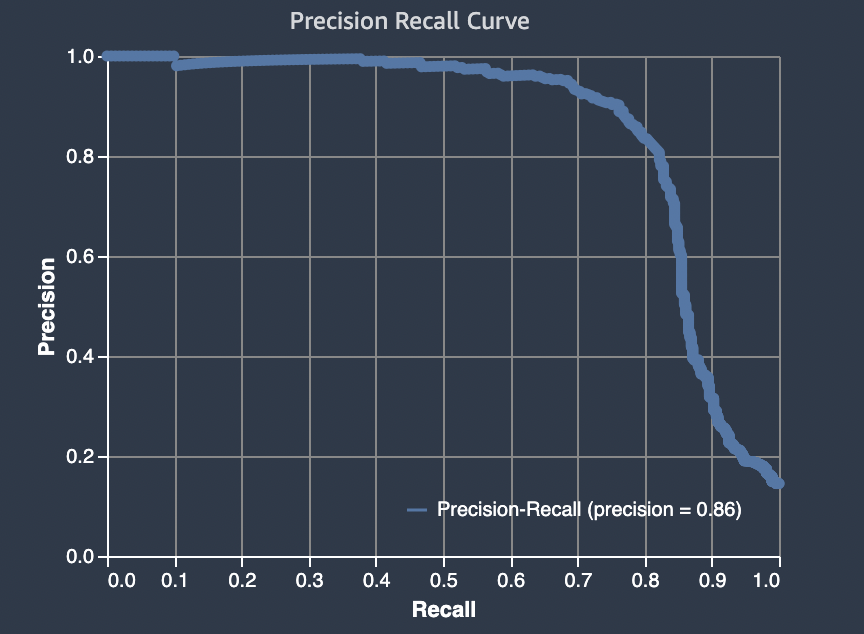
實際對照預測圖
實際對照預測圖,展示實際和預測模型值之間的差異。在下列例圖中,實線是最佳擬合的線性線。如果模型為 100% 精確,則每個預測點將等於其對應的實際點,並位於此最佳擬合線上。距離最佳擬合線的距離是模型錯誤的視覺指示。與最佳擬合線之間的距離越大,模型誤差就越高。
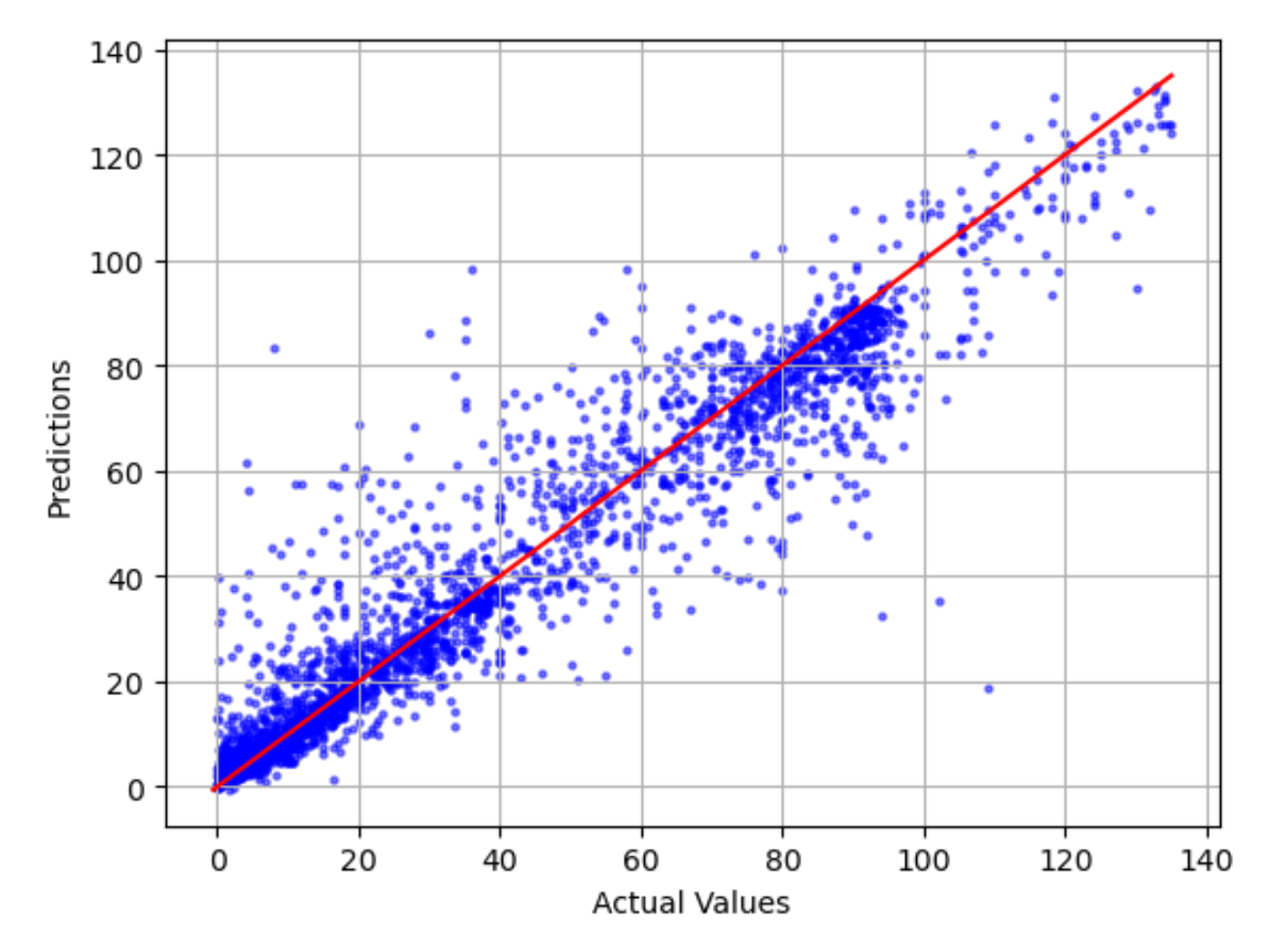
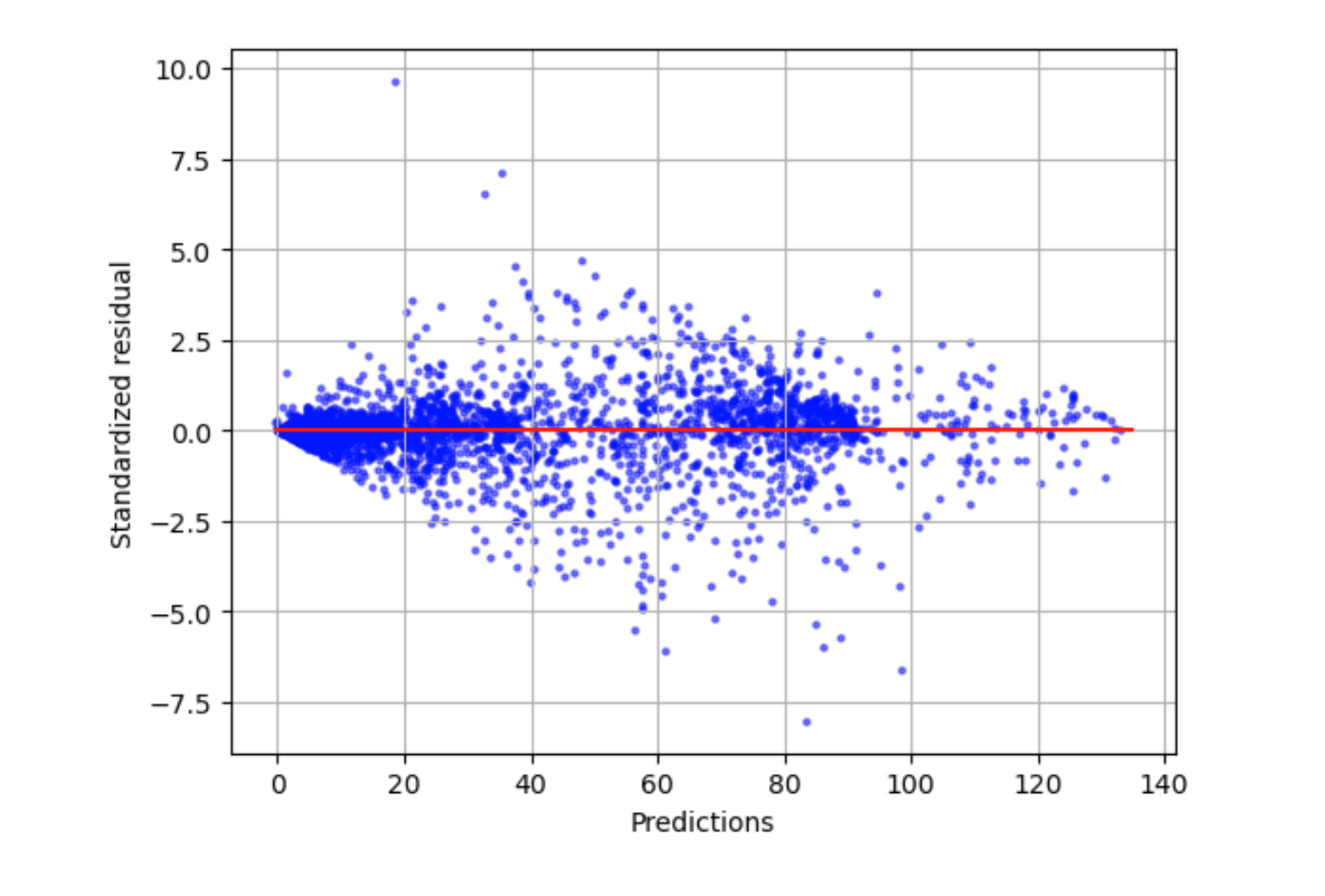
標準化殘差圖
標準化的殘差圖包含以下統計術語:
residual-
(原始) 殘差展示模型預測的實際值和值之間的差異。差異越大,剩餘值越大。
standard deviation-
標準差是衡量值與平均值的變化方式。較高的標準差表示許多值與它們的平均值有很大的不同。較低的標準差表示許多值與它們的平均值差異不大。
standardized residual-
標準化殘差會將原始殘差除以其標準差。標準化殘差具有標準差單位,對於識別資料中的極端值非常有用,不考慮原始殘差的比例差異。如果標準化殘差比其他標準化殘差小得多或大得多,則表示模型不適合這些觀測值。
標準化的殘差圖可測量觀測值與預期值之間差異的強度。實際預測值會顯示在 x 軸上。值大於絕對值 3 的點通常被視為極端值。
下面的範例圖顯示了大量的標準化殘差聚集在水平軸上的 0 周圍。接近零的值表示模型與這些資料點契合。靠近圖頂部和底部的資料點,是模型較難預測的位置。
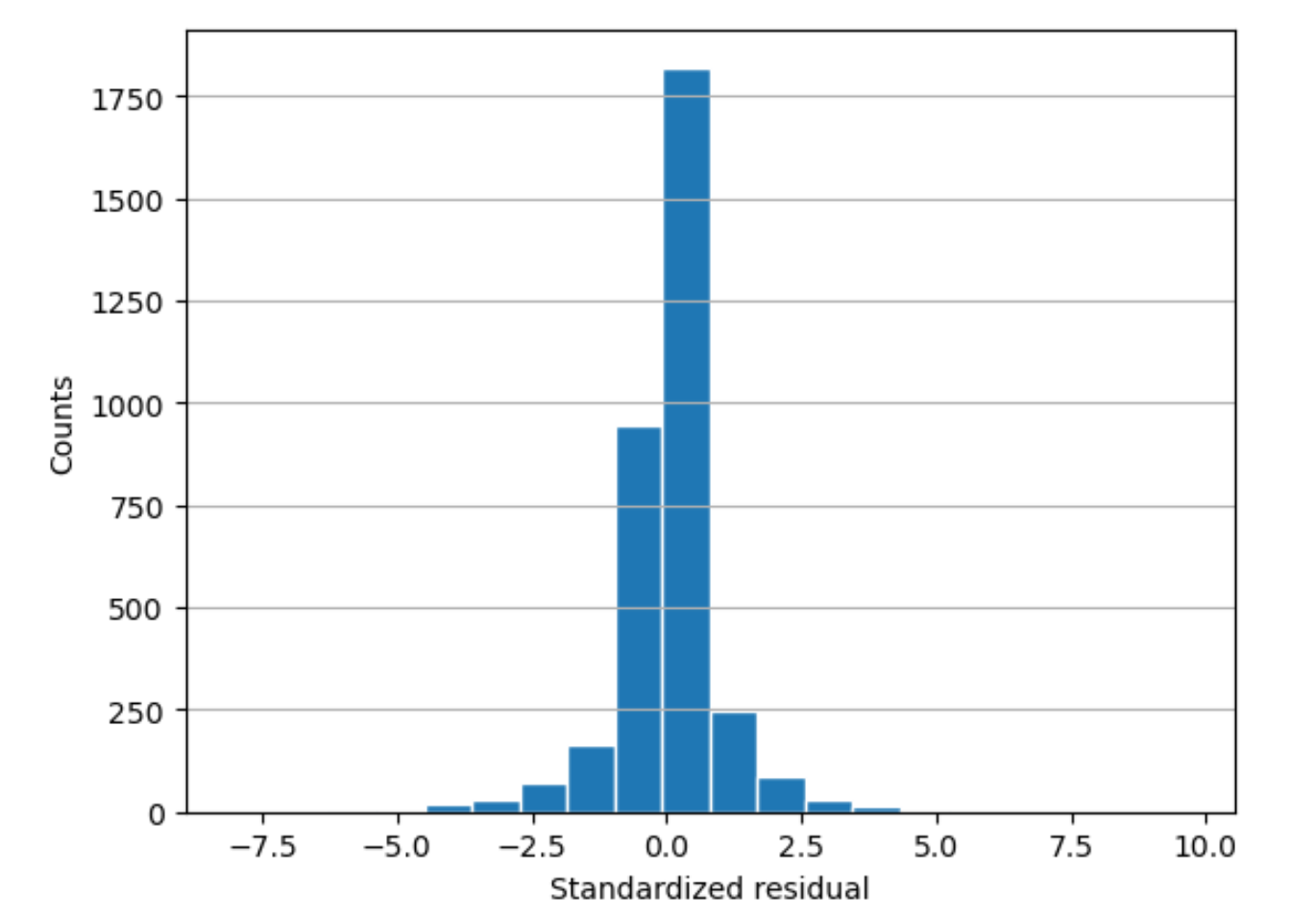
殘差長條圖
殘差長條圖包含以下統計術語:
residual-
(原始) 殘差展示模型預測的實際值和值之間的差異。差異越大,剩餘值越大。
standard deviation-
標準差是衡量值與平均值變化幅度的方式。較高的標準差表示許多值與它們的平均值有很大的不同。較低的標準差表示許多值與它們的平均值差異不大。
standardized residual-
標準化殘差會將原始殘差除以其標準差。標準化殘差具有標準差單位。這對於識別資料中的極端值非常有用,不考慮原始殘差的比例差異。如果標準化殘差比其他標準化殘差小得多或大得多,則表示模型不適合這些觀測值。
histogram-
長條圖是一個圖表,顯示一個值發生的頻率。
殘差長條圖顯示標準化殘差值的分佈。一個呈鐘形分佈並集中於零的長條圖,代表模型並未系統性地過度預測或低估任何特定範圍的目標值。
在下圖中,標準化的殘差值表示模型適合資料。如果圖表顯示遠離中心值的值,則表示這些值不適合模型。