本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
準備資料集
在此步驟中,您可以使用 SHAP (SHapley Additive exPlanations) 程式庫將成人人口普查資料集
若要執行下列範例,請將範例程式碼貼到筆記本執行個體的儲存格中。
使用 SHAP 載入成人人口普查資料集
使用 SHAP 圖書館匯入成人人口普查資料集,如下所示:
import shap X, y = shap.datasets.adult() X_display, y_display = shap.datasets.adult(display=True) feature_names = list(X.columns) feature_names
注意
如果目前的 Jupyter 核心沒有 SHAP 程式庫,請執行下列命令進行安裝:conda
%conda install -c conda-forge shap
如果您使用 JupyterLab,則必須在安裝和更新完成後手動重新整理核心。執行以下 IPython 指令碼關閉核心 (核心將自動重新啟動):
import IPython IPython.Application.instance().kernel.do_shutdown(True)
feature_names 列出物件應傳回以下功能清單:
['Age', 'Workclass', 'Education-Num', 'Marital Status', 'Occupation', 'Relationship', 'Race', 'Sex', 'Capital Gain', 'Capital Loss', 'Hours per week', 'Country']
提示
如果您從未標籤的資料開始,可以使用 Amazon SageMaker Ground Truth 相在幾分鐘內建立資料標籤工作流程。要瞭解更多資料,請參閱標籤資料。
資料集概觀
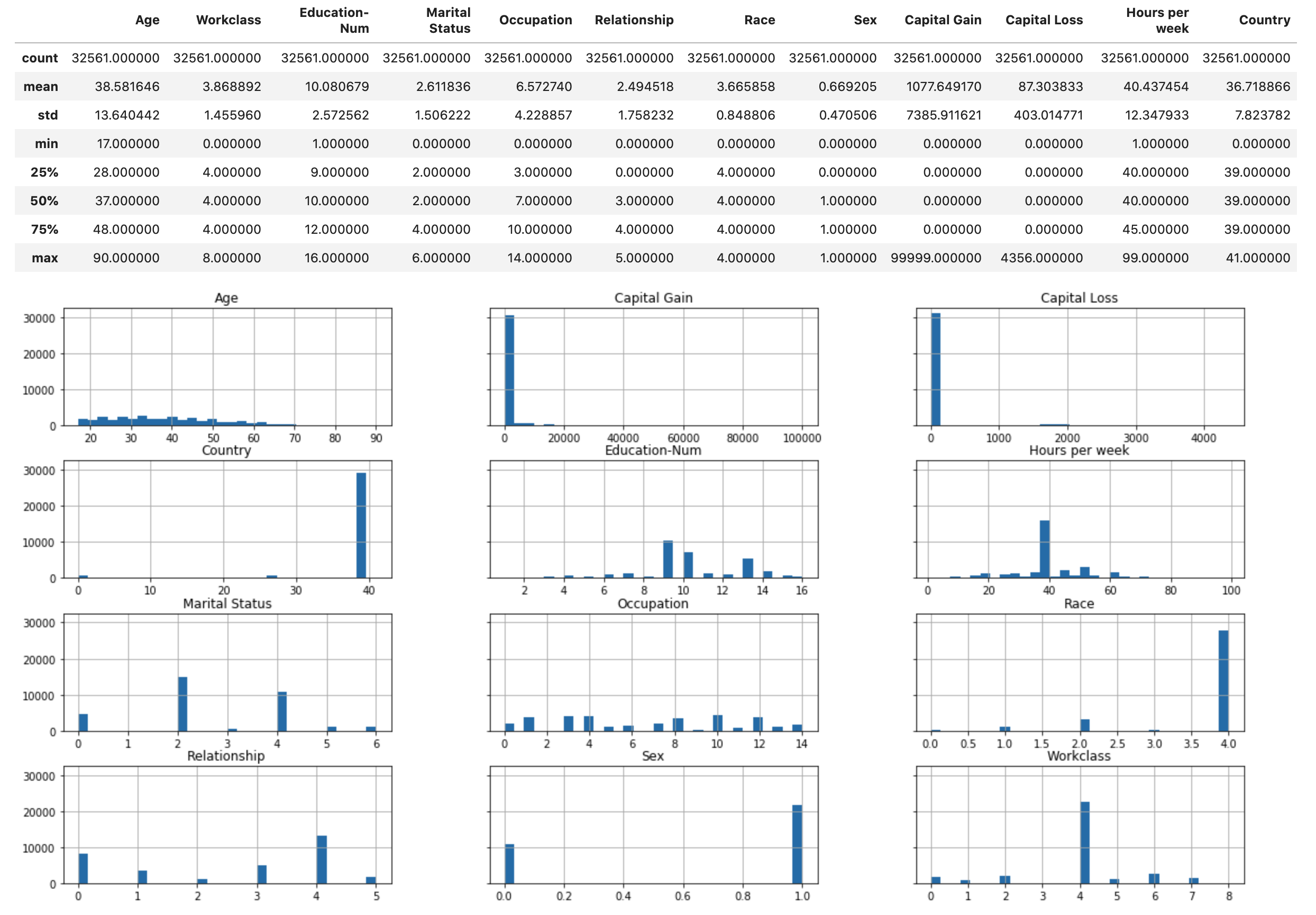
執行下列指令碼,以顯示數值圖徵之資料集和長條圖的統計概觀。
display(X.describe()) hist = X.hist(bins=30, sharey=True, figsize=(20, 10))
提示
如果您想要使用需要清理和轉換的資料集,可以使用 Amazon SageMaker Data Wrangler 簡化和簡化資料預處理和功能工程。要深入瞭解,請參閱使用 Amazon SageMaker Data Wrangler 準備機器學習 (ML) 資料。
將資料分割為訓練、測試和驗證資料集。
使用 Sklearn 將資料集拆分為訓練集和測試集。訓練集用於訓練模型,而測試集則用於評估最終訓練模型的效能。資料集會以固定隨機種子隨機排序:訓練集的 80% 資料集,而測試集則為 20%。
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1) X_train_display = X_display.loc[X_train.index]
拆分訓練集以分離出驗證集。驗證集用於評估訓練模型的效能,同時調整模型的超參數。75% 的訓練集成為最後的訓練集,其餘的則是驗證集。
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.25, random_state=1) X_train_display = X_display.loc[X_train.index] X_val_display = X_display.loc[X_val.index]
使用 pandas 套件,透過將數字特徵與真實標籤串連,明確對齊每個資料集。
import pandas as pd train = pd.concat([pd.Series(y_train, index=X_train.index, name='Income>50K', dtype=int), X_train], axis=1) validation = pd.concat([pd.Series(y_val, index=X_val.index, name='Income>50K', dtype=int), X_val], axis=1) test = pd.concat([pd.Series(y_test, index=X_test.index, name='Income>50K', dtype=int), X_test], axis=1)
檢查資料集是否按預期拆分和結構:
train
validation
test
將訓練和驗證資料集轉換為 CSV 檔案
將 train 和 validation 資料框物件轉換為 CSV 檔案,以符合 XGBoost 演算法的輸入檔案格式。
# Use 'csv' format to store the data # The first column is expected to be the output column train.to_csv('train.csv', index=False, header=False) validation.to_csv('validation.csv', index=False, header=False)
將資料集上傳到 Amazon S3
使用 SageMaker AI 和 Boto3,將訓練和驗證資料集上傳到預設的 Amazon S3 儲存貯體。Amazon EC2 上的運算最佳化 SageMaker 執行個體將使用 S3 儲存貯體中的資料集進行訓練。
下列程式碼會為您目前的 SageMaker AI 工作階段設定預設 S3 儲存貯體 URI、建立新 demo-sagemaker-xgboost-adult-income-prediction 資料夾,然後將訓練和驗證資料集上傳至 data 子資料夾。
import sagemaker, boto3, os bucket = sagemaker.Session().default_bucket() prefix = "demo-sagemaker-xgboost-adult-income-prediction" boto3.Session().resource('s3').Bucket(bucket).Object( os.path.join(prefix, 'data/train.csv')).upload_file('train.csv') boto3.Session().resource('s3').Bucket(bucket).Object( os.path.join(prefix, 'data/validation.csv')).upload_file('validation.csv')
執行下列動作 AWS CLI ,檢查 CSV 檔案是否已成功上傳至 S3 儲存貯體。
! aws s3 ls {bucket}/{prefix}/data --recursive
輸出應該會傳回以下內容:

