本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
模型訓練
完整機器學習 (ML) 生命週期的訓練階段如下:存取訓練資料集、產生最終模型,以及選取效能最佳的部署模型。以下各節提供可用的 SageMaker 訓練功能和資源的概觀,同時深入探索每項功能的技術資訊。
SageMaker 訓練的基本架構
若您是首次使用 SageMaker AI,想尋找快速的機器學習 (ML) 解決方案在資料集上的訓練模型,不妨使用無程式碼或低程式碼的解決方案,例如 SageMaker Canvas、SageMaker Studio Classic 中的 JumpStart 或 SageMaker Autopilot。
若編碼經驗為中級,則可考慮使用 SageMaker Studio Classic 筆記本或 SageMaker 筆記本執行個體。若要開始使用,請依照 SageMaker AI 《入門》指南中訓練模型的指示操作。針對此使用案例,建議您採用機器學習 (ML) 架構建立自己的模型和訓練指令碼。
SageMaker AI 的工作核心是 ML 工作負載的容器化和管理運算資源。SageMaker Training 平台負責處理與設定和管理 ML 訓練工作負載基礎架構相關的繁重工作。透過 SageMaker 訓練,您可以專注於開發、訓練和微調模型。
下列架構圖顯示 SageMaker AI 如何代表 SageMaker AI 使用者管理機器學習 (ML) 訓練任務,以及佈建 Amazon EC2 執行個體。由於您是 SageMaker AI 使用者,因此可利用自己的訓練資料集,並將其儲存至 Amazon S3。您可以從可用的 SageMaker AI 內建演算法中選擇機器學習 (ML) 模型訓練,或透過由熱門機器學習架構所建立的模型,使用自己專屬的訓練指令碼。
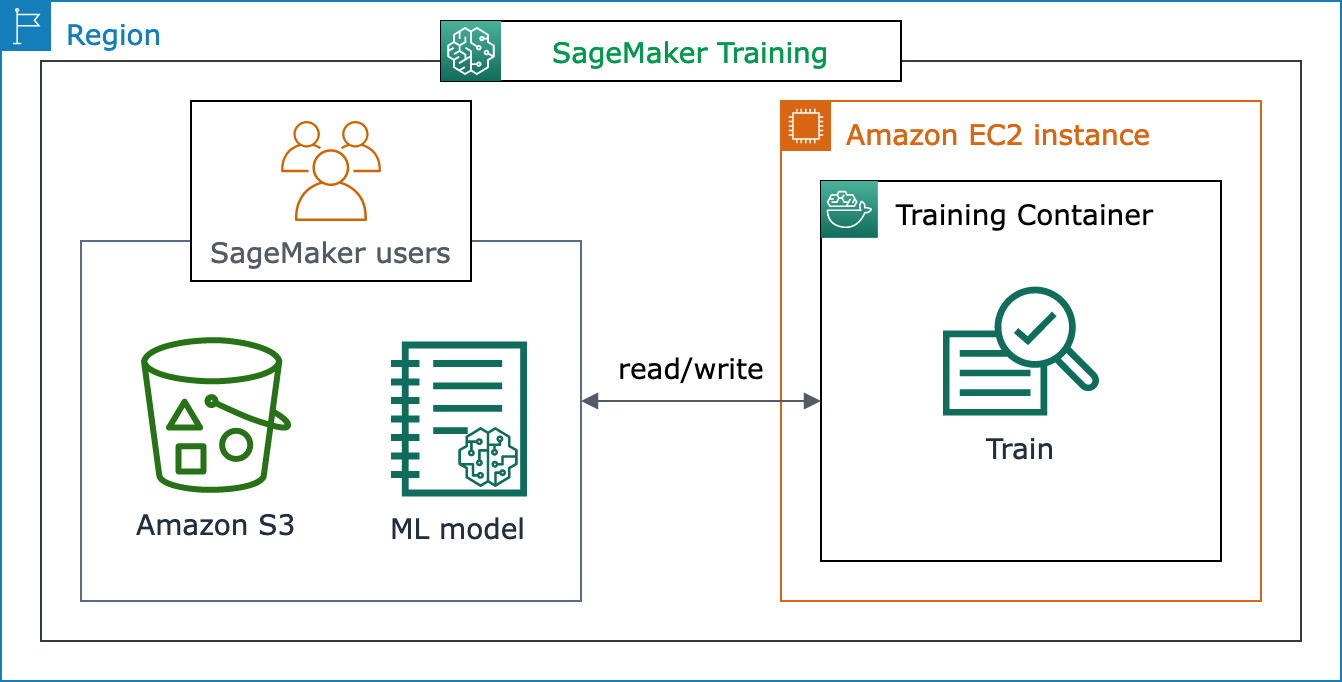
完整檢視 SageMaker 訓練流程和功能
整趟機器學習 (ML) 訓練旅程涵蓋範圍極廣,不只侷限於資料擷取至 ML 模型、運算執行個體上的訓練模型,以及取得模型成品和輸出。請務必評估訓練前、中、後的各個階段,以確保您的模型受到良好的訓練,才能符合理想的目標準確度。
下列流程圖概述您在機器學習 (ML) 生命週期訓練階段中的動作 (以藍色方塊顯示),以及可用的 SageMaker 訓練功能 (以淺藍色方塊顯示)。
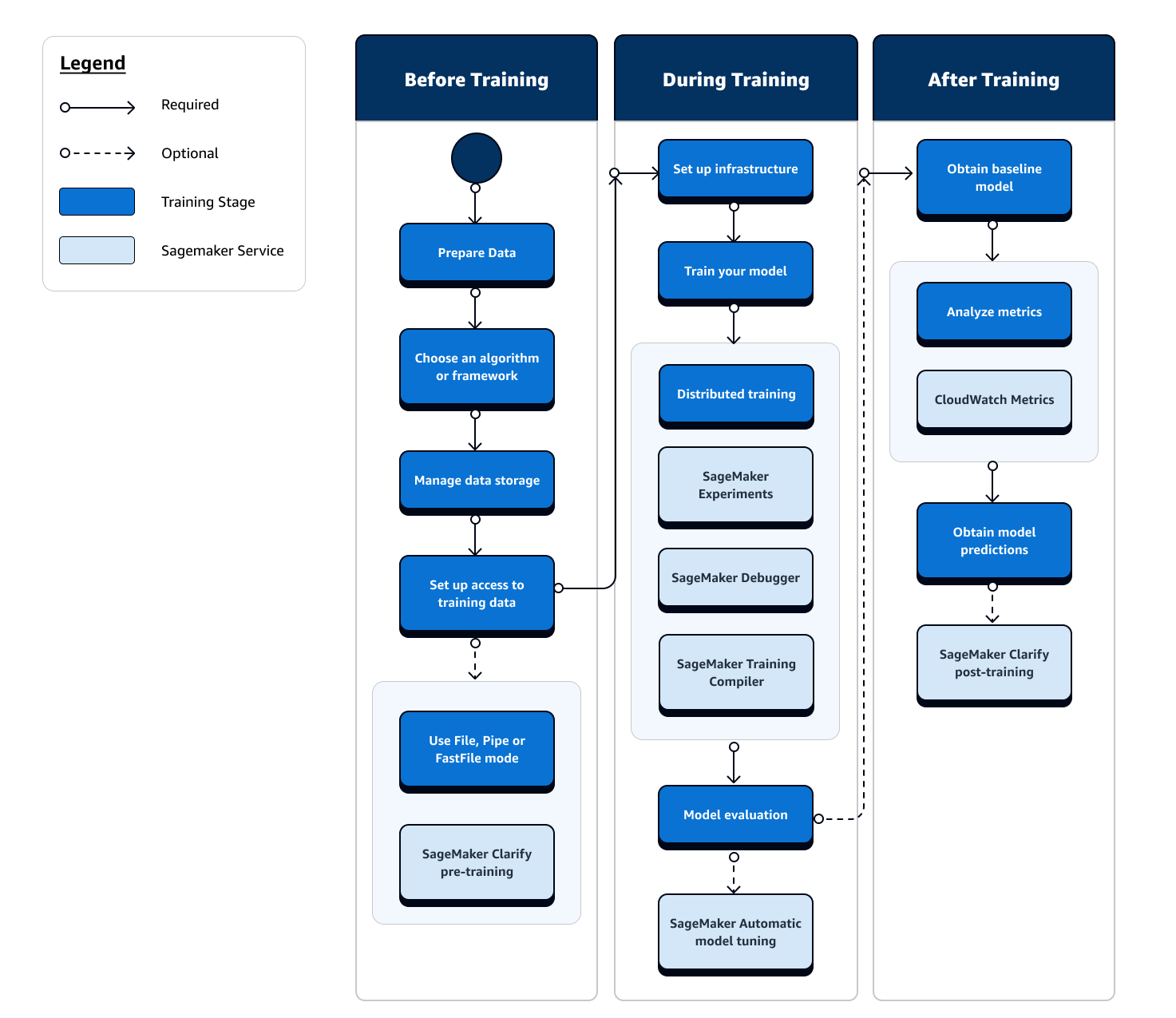
以下幾節將向您介紹先前流程圖中所述的每個訓練階段,以及 SageMaker AI 在機器學習 (ML) 訓練的三個子階段中所提供的實用功能。
訓練之前
展開訓練之前,建議您多多思考幾個設定資料資源和存取權的情況。請參閱以下圖表和每個訓練前階段的詳細資訊,以釐清您需要做出哪些決定。
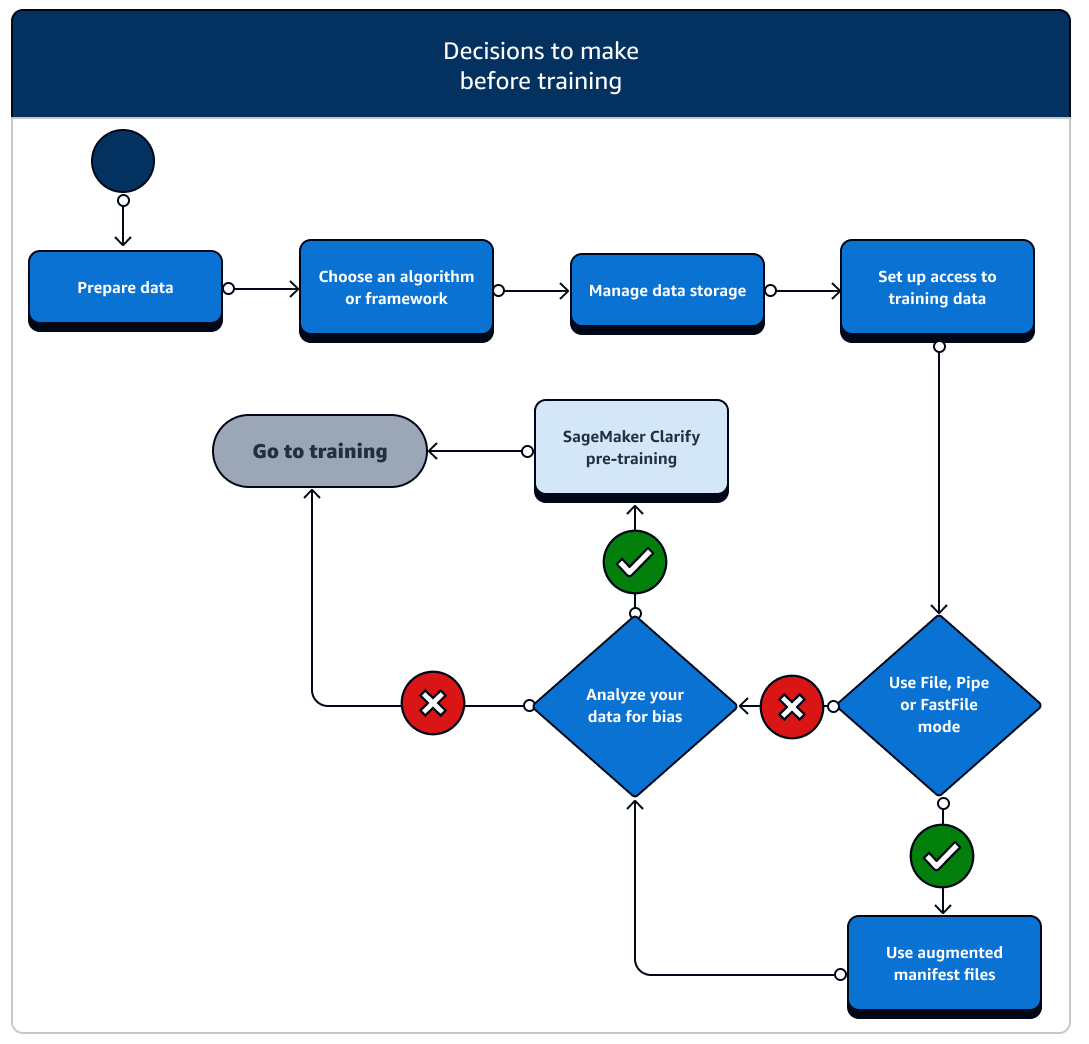
-
備妥資料:在訓練之前,您必須在資料準備階段完成資料清理和特徵工程。SageMaker AI 有多種標籤和特徵工程工具可派上用場。請參閱標示資料、準備和分析資料集、處理資料以及建立、儲存和共用功能,以了解詳情。
-
選擇演算法或架構:根據您所需的自訂程度,我們提供了不同的演算法和架構選項。
-
如果您偏好預先建置演算法的低程式碼實作,請使用 SageMaker AI 提供的其中一種內建演算法。如需更多資訊,請參閱選擇演算法。
-
若需更多彈性來自訂模型,請使用 SageMaker AI 中您所偏好的架構和工具組,以執行訓練指令碼。如需更多資訊,請參閱機器學習 (ML) 架構與工具組。
-
若要將預先建置的 SageMaker AI Docker 映像檔延伸為您專屬容器的基本映像,請參閱使用預先建置 SageMaker AI Docker 映像檔的說明。
-
若想將您的自訂 Docker 容器帶入 SageMaker AI,請參閱調整自有的 Docker 容器以搭配 SageMaker AI 使用。您必須將 sagemaker-training-toolkit
安裝至容器中。
-
-
管理資料儲存:了解資料儲存 (例如 Amazon S3、Amazon EFS 或 Amazon FSx) 與在 Amazon EC2 運算執行個體中執行的訓練容器之間的映射方式。SageMaker AI 可協助映射訓練容器中的儲存路徑和本機路徑。您也可以手動指定路徑。完成映射後,可考慮使用其中一種資料傳輸模式:文件、管道或 FastFile 模式。如要了解 SageMaker AI 如何映射儲存路徑,請參閱訓練儲存資料夾。
-
設定訓練資料的存取權:使用 Amazon SageMaker AI 網域、網域使用者設定檔、IAM、Amazon VPC 和 AWS KMS ,以滿足最安全敏感組織的需求。
-
如需帳戶管理的說明,請參閱 Amazon SageMaker AI 網域。
-
如需 IAM 政策和安全性的完整參考資料,請參閱 Amazon SageMaker AI 中的安全性。
-
-
串流您的輸入資料:SageMaker AI 提供三種資料輸入模式:檔案、管道和 FastFile。預設的輸入模式為檔案模式,本身會在初始化訓練任務期間載入整個資料集。若要了解將資料從資料儲存串流至訓練容器的一般最佳實務,請參閱存取訓練資料。
在管道模式中,您也可以考慮使用擴增的資訊清單檔案,直接從 Amazon Simple Storage Service (Amazon S3) 串流資料並訓練您的模型。使用管道模式可減少磁碟空間,因為 Amazon Elastic Block Store 只需儲存最終模型成品,無須儲存完整的訓練資料集。如需更多資訊,請參閱向具有擴增資訊清單檔案的訓練任務提供資料集中繼資料。
-
分析資料是否存有偏差:在訓練之前,您可以分析資料集和模型是否對不受歡迎的群組存有偏差,以便利用 SageMaker Clarify 確認模型可妥善學習中立的資料集。
-
選擇要使用的 SageMaker SDK:有兩種方式可在 SageMaker AI 中啟動訓練任務:使用高階 SageMaker AI Python SDK,或者使用適用於 Python 的 SDK (Boto3) 或 AWS CLI適用的低階 SageMaker API。SageMaker Python SDK 會抽象化低階的 SageMaker API,以提供方便使用的工具。如同SageMaker 訓練的基本架構所述,您也可以採用無程式碼或極少程式碼的選項,方法就是透過 SageMaker Canvas、SageMaker Studio Classic 中的 JumpStart 或 SageMaker AI Autopilot。
訓練期間
在訓練期間,您需要持續改善訓練的穩定性、訓練速度、訓練效率,並擴展運算資源、成本最佳化,同時還有最重要的模型效能。請繼續閱讀,了解訓練期間的階段和相關 SageMaker 訓練功能的詳細說明。
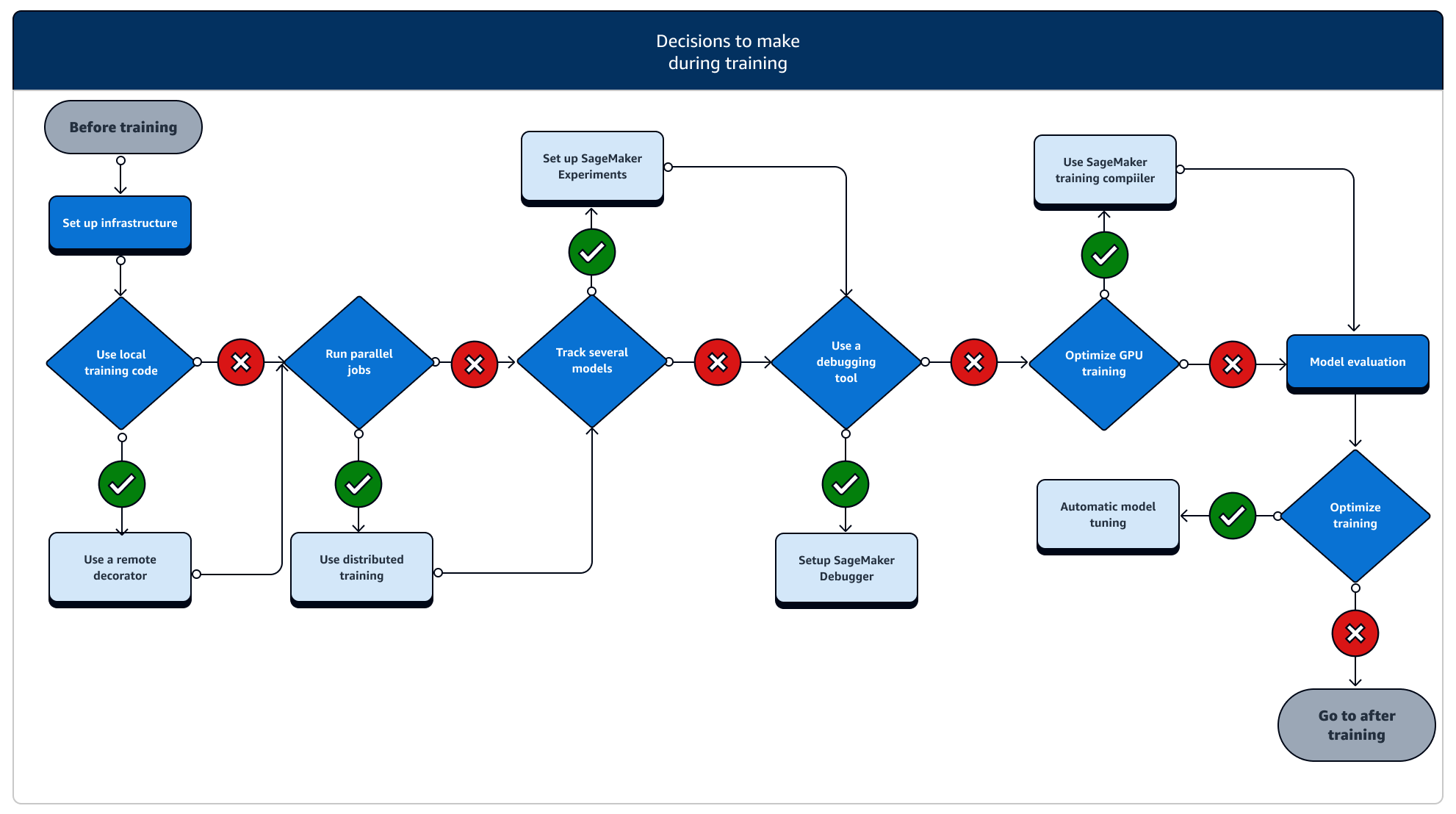
-
設定基礎設施:為您的使用案例選擇合適的執行個體類型和基礎設施管理工具。不妨從小型執行個體開始,再根據工作負載縱向擴展。如要在表格式資料集上訓練模型,請從 C4 或 C5 執行個體系列中最小的 CPU 執行個體著手。若要訓練大型模型以進行電腦視覺或自然語言處理,請從 P2、P3、G4dn 或 G5 執行個體系列中最小的 GPU 執行個體開始。您也可以在叢集中混用不同的執行個體類型,或使用下列 SageMaker AI 提供的執行個體管理工具將執行個體保留在暖集區。或者也能使用持久性快取來減少反覆訓練任務的延遲和應計費時間,只需透過暖集區減少延遲即可。如需進一步了解,請參閱下列主題。
您必須有足夠的配額才能執行訓練任務。如果在配額不足的執行個體上執行訓練任務,就會收到
ResourceLimitExceeded的錯誤訊息。若要查看您帳戶中目前可用的配額,請使用 Service Quotas 主控台。想了解如何請求提高配額,請參閱支援的區域與配額。此外,若要根據 尋找定價資訊和可用的執行個體類型 AWS 區域,請在 Amazon SageMaker 定價 頁面中查詢資料表。 -
透過本機程式碼執行訓練任務:您可以使用遠端裝飾器為本機程式碼新增註釋,以便從 Amazon SageMaker Studio Classic、Amazon SageMaker 筆記本或本機整合式開發環境中以 Amazon SageMaker 訓練任務的形式執行程式碼。如需詳細資訊,請參閱以 SageMaker 訓練工作方式執行本機代碼。
-
追蹤訓練任務:使用 SageMaker Experiments、SageMaker Debugger 或 Amazon CloudWatch 監控並追蹤訓練任務。您可以透過 SageMaker AI Experiments 來查看模型效能,並針對多個訓練任務之間的指標執行比較式分析。您可以使用 SageMaker Debugger 的分析工具或 Amazon CloudWatch 來查看運算資源使用率。如需進一步了解,請參閱下列主題。
此外,針對深度學習任務,請使用 Amazon SageMaker Debugger 模型偵錯工具和內建規則,以識別模型收斂和權重更新程序中較複雜的問題。
-
分散式訓練:如果您的訓練任務邁入穩定的階段,而不會因為訓練基礎設施配置錯誤或記憶體不足等問題而中斷,則您或許可找尋更多選項來擴展任務,並在幾天甚或幾個月的一段時間內加以執行。當您準備好縱向擴展時,可考慮分散式訓練。SageMaker AI 提供各種分散式運算選項,從輕度機器學習 (ML) 工作負載到繁重的深度學習工作負載應有盡有。
若涉及在超大型資料集上訓練超大模型的深度學習任務,請考慮使用其中一種 SageMaker AI 分散式訓練策略,以縱向擴展並實現資料平行化、模型平行化或兼具兩者的組合。您也可以使用 SageMaker Training Compiler 來編譯和最佳化 GPU 執行個體上的模型圖表。這些 SageMaker AI 功能可支援深度學習架構,例如 PyTorch、TensorFlow 和 Hugging Face Transformers。
-
模型超參數調校:參閱使用 SageMaker AI 自動模型調整來調整模型超參數。SageMaker AI 提供超參數調校方法,例如網格搜尋和貝葉斯搜尋,能啟動具有提前停止功能的平行超參數調校任務,以用於非改善型超參數調校任務。
-
使用 Spot 執行個體設定檢查點和節省成本:如果訓練時間不是個大問題,則可考慮使用受管 Spot 執行個體來最佳化模型訓練成本。請注意,您必須啟用 Spot 訓練的檢查點,才能繼續從因為取代 Spot 執行個體而間歇性發生的工作暫停中復原。在非預期的訓練任務終止時,您也可以使用檢查點功能來備份模型。如需進一步了解,請參閱下列主題。
訓練之後
訓練後,您會取得最終的模型成品,以用於模型部署和推論。另有參與訓練後階段的其他動作,如下圖所示。
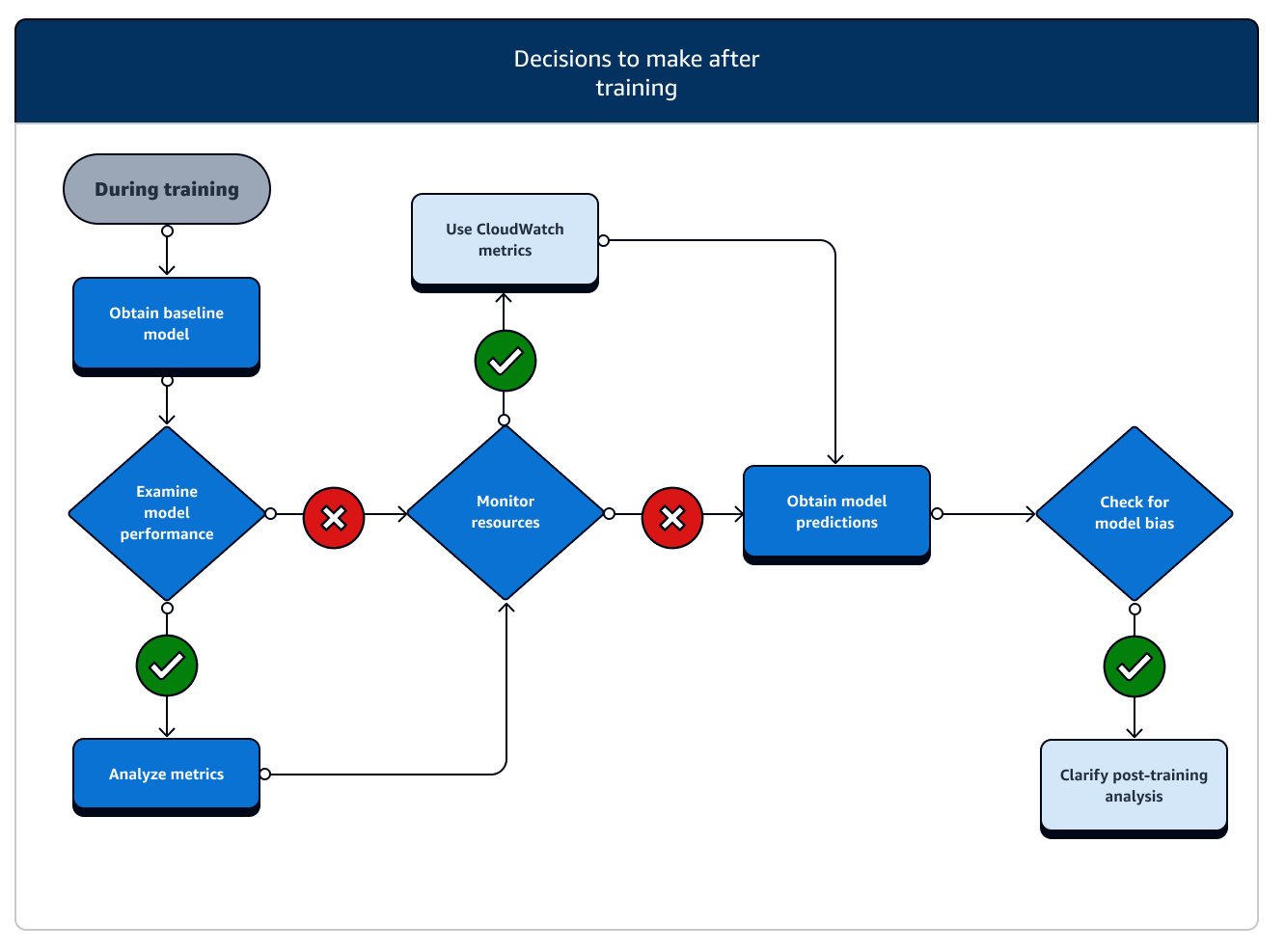
-
取得基準模型:取得模型成品後,可將其設定為基準模型。在繼續進行模型部署到生產環境之前,請考慮下列訓練後的操作並使用 SageMaker AI 功能。
-
查看模型效能並確認是否有偏差:使用 Amazon CloudWatch 指標和 SageMaker Clarify 來檢測訓練後是否有偏差,以根據基準偵測傳入資料和模型隨著時間推移下的任何偏差狀況。您必須定期或即時評估新資料,並針對新資料進行模型預測。使用這些功能,即可接收有關任何急性變更或異常,以及資料和模型中逐漸出現的變更或漂移之警示。
-
您也可以使用 SageMaker AI 的累加式訓練功能,以擴充的資料集載入及更新模型 (或從中微調)。
-
您可以將模型訓練註冊為 SageMaker AI 管道 中的一個步驟,或註冊為 SageMaker 提供的其他工作流程功能的一個環節,以協調執行完整的機器學習 (ML) 生命週期。
