Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Vous pouvez tester le déploiement d'un modèle en invoquant le point de terminaison ou en effectuant des demandes de prédiction uniques via l'application Amazon SageMaker Canvas. Vous pouvez utiliser cette fonctionnalité pour vérifier que votre point de terminaison répond aux demandes avant de l'appeler par programmation dans un environnement de production.
Tester le déploiement d'un modèle personnalisé
Vous pouvez tester le déploiement d'un modèle personnalisé en y accédant via la page ML Ops et en effectuant un seul appel, qui renvoie une prédiction ainsi que la probabilité que la prédiction soit correcte.
Note
La durée d'exécution est une estimation du temps nécessaire pour invoquer et obtenir une réponse du point de terminaison dans Canvas. Pour des mesures de latence détaillées, consultez SageMaker AI Endpoint Invocation Metrics.
Pour tester votre point de terminaison via l'application Canvas, procédez comme suit :
-
Ouvrez l'application SageMaker Canvas.
-
Dans le panneau de navigation de gauche, choisissez ML Ops.
-
Choisissez l'onglet Déploiements.
-
Dans la liste des déploiements, choisissez celui avec le point de terminaison que vous souhaitez appeler.
-
Sur la page des détails du déploiement, choisissez l'onglet Tester le déploiement.
-
Sur la page de test de déploiement, vous pouvez modifier les champs de valeur pour spécifier un nouveau point de données. Pour les modèles de prévision de séries chronologiques, vous spécifiez l'ID d'article pour lequel vous souhaitez établir une prévision.
-
Après avoir modifié les valeurs, choisissez Mettre à jour pour obtenir le résultat de la prédiction.
La prédiction se charge, ainsi que les champs de résultat de l'invocation qui indiquent si l'appel a réussi ou non et combien de temps il a fallu pour traiter la demande.
La capture d'écran suivante montre une prédiction effectuée dans l'application Canvas sous l'onglet Test de déploiement.
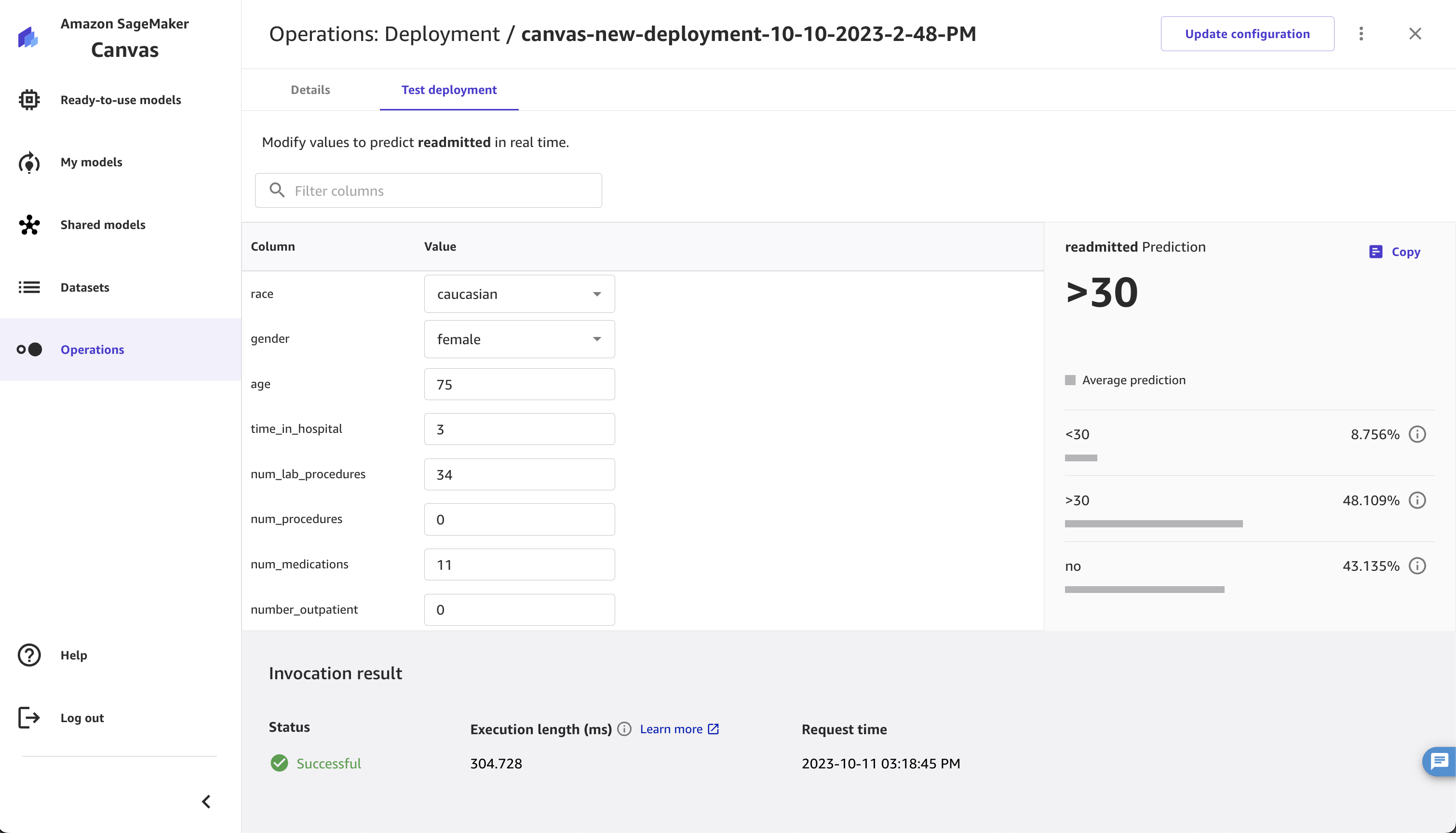
Pour tous les types de modèles, à l'exception des prévisions numériques et des prévisions de séries chronologiques, la prédiction renvoie les champs suivants :
-
predicted_label — la sortie prévue
-
probabilité : probabilité que l'étiquette prédite soit correcte
-
labels — la liste de tous les labels possibles
-
probabilités : les probabilités correspondant à chaque étiquette (l'ordre de cette liste correspond à l'ordre des étiquettes)
Pour les modèles de prédiction numériques, la prédiction contient uniquement le champ de score, qui est le résultat prévu du modèle, tel que le prix prévu d'une maison.
Pour les modèles de prévision par séries chronologiques, la prédiction est un graphique présentant les prévisions par quantile. Vous pouvez choisir la vue Schéma pour voir les valeurs numériques prévues pour chaque quantile.
Vous pouvez continuer à faire des prédictions uniques via la page de test de déploiement, ou vous pouvez consulter la section suivante Appelez votre point de terminaison pour savoir comment appeler votre point de terminaison par programmation à partir d'applications.
Tester le déploiement d'un modèle de JumpStart base
Vous pouvez discuter avec un modèle de JumpStart base déployé via l'application Canvas pour tester ses fonctionnalités avant de l'invoquer via le code.
Pour discuter avec un modèle de JumpStart base déployé, procédez comme suit :
-
Ouvrez l'application SageMaker Canvas.
-
Dans le panneau de navigation de gauche, choisissez ML Ops.
-
Choisissez l'onglet Déploiements.
-
Dans la liste des déploiements, recherchez celui que vous souhaitez invoquer et choisissez son icône Plus d'options (
 ).
). -
Dans le menu contextuel, choisissez Tester le déploiement.
-
Un nouveau chat de génération, d'extraction et de synthèse de contenu s'ouvre avec le modèle de JumpStart base, et vous pouvez commencer à taper des instructions. Notez que les instructions issues de ce chat sont envoyées sous forme de demandes à votre point de terminaison SageMaker AI Hosting.
