Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Préparation d’un jeu de données
Dans cette étape, vous chargez le jeu de données de recensement des adultes
Pour exécuter l’exemple suivant, collez l’exemple de code dans une cellule de votre instance de bloc-notes.
Charger le jeu de données du recensement des adultes à l'aide de SHAP
À l'aide de la bibliothèque SHAP, importez le jeu de données du recensement des adultes comme indiqué ci-dessous :
import shap X, y = shap.datasets.adult() X_display, y_display = shap.datasets.adult(display=True) feature_names = list(X.columns) feature_names
Note
Si le noyau Jupyter actuel ne dispose pas de la bibliothèque SHAP, installez-la en exécutant la commande conda suivante :
%conda install -c conda-forge shap
Si vous l'utilisez JupyterLab, vous devez actualiser manuellement le noyau une fois l'installation et les mises à jour terminées. Exécutez le script IPython suivant pour arrêter le noyau (le noyau redémarrera automatiquement) :
import IPython IPython.Application.instance().kernel.do_shutdown(True)
L'objet de liste feature_names doit renvoyer la liste de fonctions suivante :
['Age', 'Workclass', 'Education-Num', 'Marital Status', 'Occupation', 'Relationship', 'Race', 'Sex', 'Capital Gain', 'Capital Loss', 'Hours per week', 'Country']
Astuce
Si vous commencez avec des données non étiquetées, vous pouvez utiliser Amazon SageMaker Ground Truth pour créer un flux de travail d'étiquetage des données en quelques minutes. Pour en savoir plus, consultez Étiqueter les données.
Présentation du jeu de données
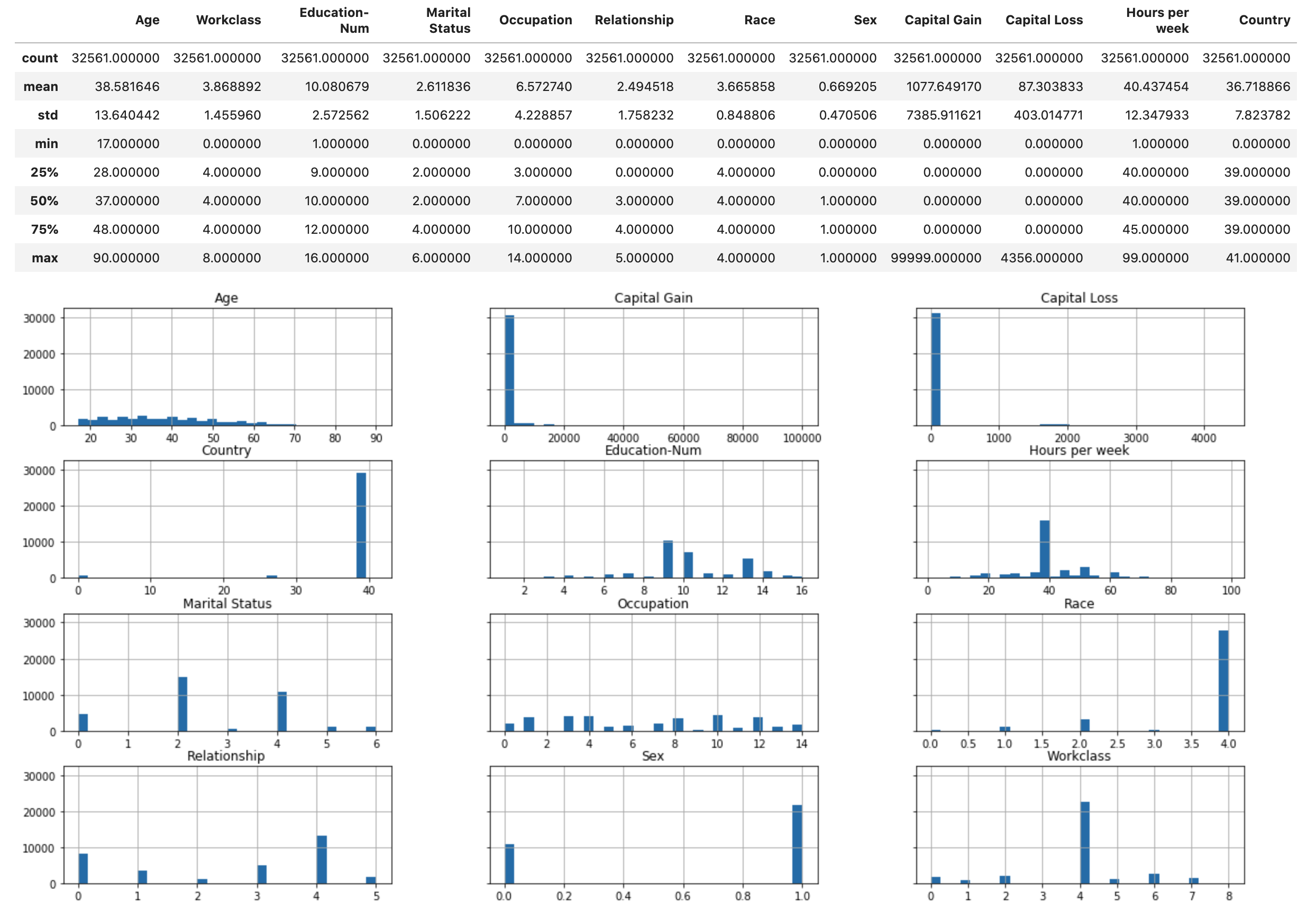
Exécutez le script suivant pour afficher la présentation statistique du jeu de données et des histogrammes des fonctions numériques.
display(X.describe()) hist = X.hist(bins=30, sharey=True, figsize=(20, 10))
Astuce
Si vous souhaitez utiliser un ensemble de données qui doit être nettoyé et transformé, vous pouvez simplifier et rationaliser le prétraitement des données et l'ingénierie des fonctionnalités à l'aide d'Amazon SageMaker Data Wrangler. Pour en savoir plus, consultez Préparer les données ML avec Amazon SageMaker Data Wrangler.
Diviser le jeu de données en jeux de données d'entraînement, de validation et de test
Avec Sklearn, divisez le jeu de données en jeu d’entraînement et de test. L'ensemble d'entraînement est utilisé pour entraîner le modèle, tandis que l'ensemble de tests sert à évaluer les performances du modèle entraîné final. Le jeu de données est trié de façon aléatoire avec le nombre aléatoire : 80 % du jeu de données pour l'ensemble d'entraînement et 20 % pour un jeu de test.
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1) X_train_display = X_display.loc[X_train.index]
Divisez l'ensemble d'entraînement pour séparer un ensemble de validation. L'ensemble de validation est utilisé pour évaluer les performances du modèle entraîné tout en réglant les hyperparamètres du modèle. 75 % de l'ensemble d'entraînement devient l'ensemble d'entraînement final et le reste est l'ensemble de validation.
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.25, random_state=1) X_train_display = X_display.loc[X_train.index] X_val_display = X_display.loc[X_val.index]
À l’aide du package pandas, alignez explicitement chaque jeu de données en concaténant les fonctions numériques avec les étiquettes true.
import pandas as pd train = pd.concat([pd.Series(y_train, index=X_train.index, name='Income>50K', dtype=int), X_train], axis=1) validation = pd.concat([pd.Series(y_val, index=X_val.index, name='Income>50K', dtype=int), X_val], axis=1) test = pd.concat([pd.Series(y_test, index=X_test.index, name='Income>50K', dtype=int), X_test], axis=1)
Vérifiez si le jeu de données est divisé et structuré comme prévu :
train
validation
test
Conversion des jeux de données d’entraînement et de validation en fichiers CSV
Convertissez les objets de trame de données train et validation en fichiers CSV pour correspondre au format de fichier d'entrée pour l'algorithme XGBoost.
# Use 'csv' format to store the data # The first column is expected to be the output column train.to_csv('train.csv', index=False, header=False) validation.to_csv('validation.csv', index=False, header=False)
Télécharger les jeux de données dans Amazon S3
À l'aide de l' SageMaker IA et de Boto3, téléchargez les ensembles de données d'entraînement et de validation dans le compartiment Amazon S3 par défaut. Les ensembles de données du compartiment S3 seront utilisés par une SageMaker instance optimisée pour le calcul sur Amazon EC2 à des fins de formation.
Le code suivant définit l'URI du compartiment S3 par défaut pour votre session SageMaker AI en cours, crée un nouveau demo-sagemaker-xgboost-adult-income-prediction dossier et télécharge les ensembles de données de formation et de validation dans le data sous-dossier.
import sagemaker, boto3, os bucket = sagemaker.Session().default_bucket() prefix = "demo-sagemaker-xgboost-adult-income-prediction" boto3.Session().resource('s3').Bucket(bucket).Object( os.path.join(prefix, 'data/train.csv')).upload_file('train.csv') boto3.Session().resource('s3').Bucket(bucket).Object( os.path.join(prefix, 'data/validation.csv')).upload_file('validation.csv')
Exécutez ce qui suit AWS CLI pour vérifier si les fichiers CSV sont correctement chargés dans le compartiment S3.
! aws s3 ls {bucket}/{prefix}/data --recursive
La sortie suivante doit être renvoyée :

