Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Le résultat de chaque tâche Inference Recommender inclut InstanceType, InitialInstanceCount et EnvironmentParameters, qui sont des paramètres de variables d'environnement ajustés pour votre conteneur afin d'améliorer sa latence et son débit. Les résultats incluent également des métriques de performances et de coûts telles que MaxInvocations, ModelLatency, CostPerHour, CostPerInference, CpuUtilization et MemoryUtilization.
Dans le tableau ci-dessous, nous fournissons une description de ces métriques. Ces métriques peuvent vous aider à affiner votre recherche pour trouver la configuration de point de terminaison la mieux adaptée à votre cas d'utilisation. Par exemple, si votre motivation est la performance globale en termes de prix en mettant l'accent sur le débit, vous devez vous concentrer sur CostPerInference.
| Métrique | Description | Cas d’utilisation |
|---|---|---|
|
|
Intervalle de temps nécessaire à un modèle pour répondre tel qu'il est vu par l' SageMaker IA. Cet intervalle inclut le temps de communication local pris pour envoyer la requête et pour récupérer la réponse du conteneur d'un modèle et le temps nécessaire pour terminer l'inférence dans le conteneur. Unités : millisecondes |
Charges de travail sensibles à la latence, telles que la diffusion d'annonces et les diagnostics médicaux |
|
|
Le nombre maximum de demandes Unités : aucune |
Charges de travail axées sur le débit, telles que le traitement vidéo ou l'inférence par lots |
|
|
Le coût horaire estimé pour votre point de terminaison en temps réel. Unités : dollars américains |
Charges de travail sensibles aux coûts sans délais de latence |
|
|
Le coût horaire estimé par appel d'inférence pour votre point de terminaison en temps réel. Unités : dollars américains |
Optimiser le rapport prix-performance global en mettant l'accent sur le débit |
|
|
Utilisation prévue du processeur pour un nombre maximal d'appels par minute pour l'instance de point de terminaison. Unités : pourcentage |
Comprendre l'état de santé de l'instance lors de l'analyse comparative en ayant une visibilité sur l'utilisation du processeur principal de l'instance |
|
|
Utilisation prévue de la mémoire pour un nombre maximal d'appels par minute pour l'instance de point de terminaison. Unités : pourcentage |
Comprendre l'état de santé de l'instance lors de l'analyse comparative en ayant une visibilité sur l'utilisation de la mémoire principale de l'instance |
Dans certains cas, vous souhaiterez peut-être explorer d'autres métriques SageMaker AI Endpoint Invocation, telles queCPUUtilization. Les résultats de chaque tâche Inference Recommender incluent les noms des points de terminaison générés lors du test de charge. Vous pouvez l'utiliser CloudWatch pour consulter les journaux de ces points de terminaison même après leur suppression.
L'image suivante est un exemple de CloudWatch mesures et de graphiques que vous pouvez consulter pour un seul point de terminaison à partir du résultat de vos recommandations. Le résultat de cette recommandation provient d'une tâche par défaut. Pour interpréter les valeurs scalaires à partir des résultats des recommandations, elles sont basées sur le moment où le graphe Invocations commence à se stabiliser pour la première fois. Par exemple, la valeur ModelLatency signalée se trouve au début du plateau autour de 03:00:31.
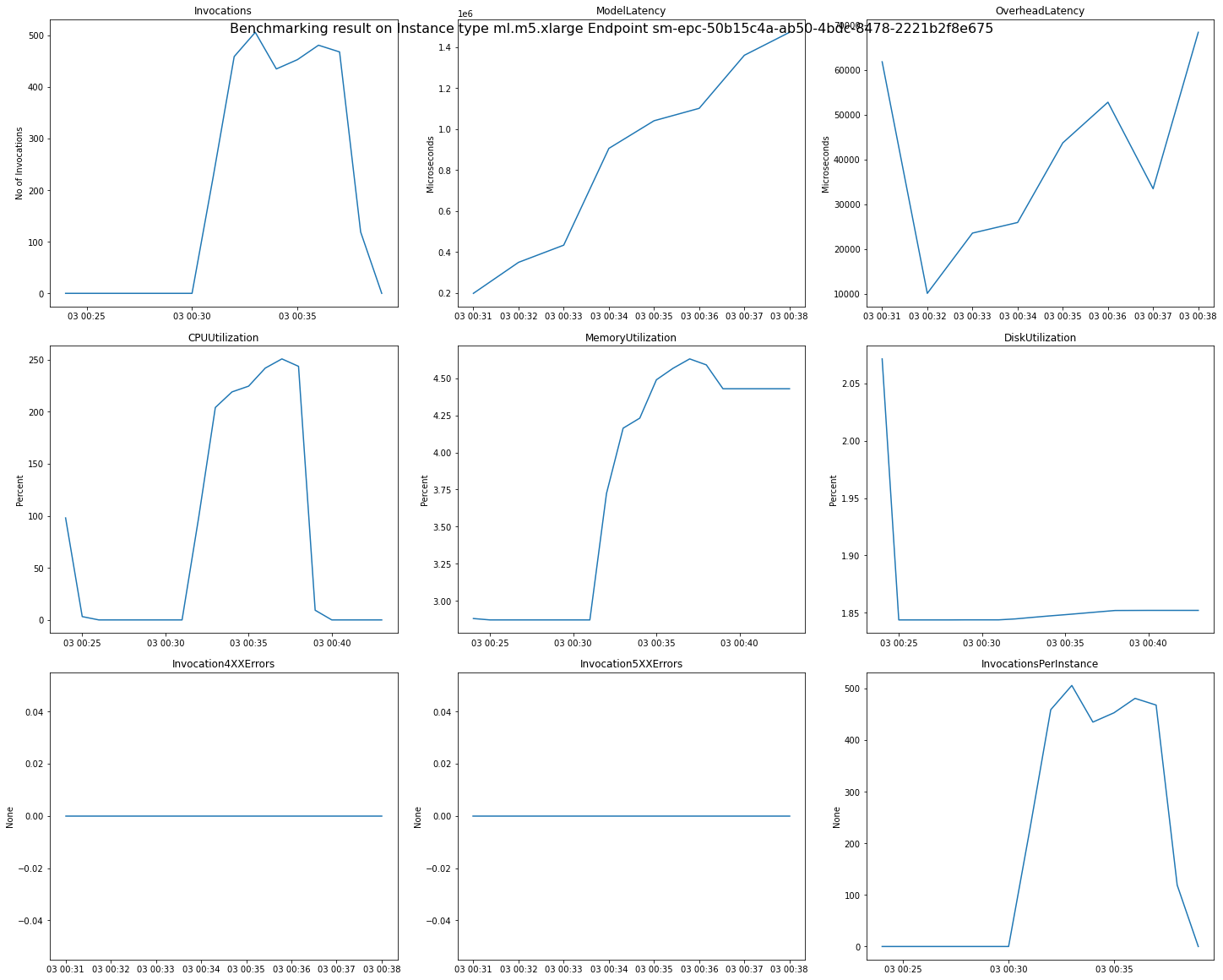
Pour une description complète des CloudWatch métriques utilisées dans les graphiques précédents, voir SageMaker AI Endpoint Invocation metrics.
Vous pouvez également consulter les métriques de performances telles que ClientInvocations et NumberOfUsers publiées par Inference Recommender dans l'espace de noms /aws/sagemaker/InferenceRecommendationsJobs. Pour obtenir la liste complète des métriques et des descriptions publiées par Inference Recommender, consultez SageMaker Indicateurs des tâches d'Inference Recommender.
Consultez le bloc-notes Amazon SageMaker Inference Recommender - CloudWatch Metrics
