Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Optimisation des performances des modèles avec SageMaker Neo
Neo est une fonctionnalité d'Amazon SageMaker AI qui permet aux modèles d'apprentissage automatique de s'entraîner une seule fois et de fonctionner n'importe où dans le cloud et à la périphérie.
Si vous utilisez SageMaker Neo pour la première fois, nous vous recommandons de consulter la section Getting Started with Edge Devices pour obtenir des instructions détaillées sur la façon de compiler et de déployer sur un périphérique Edge.
Qu'est-ce que SageMaker Neo ?
Généralement, il est difficile d’optimiser des modèles de machine learning pour l’inférence sur plusieurs plateformes, car vous devez régler manuellement ces modèles en fonction de la configuration matérielle et logicielle de chaque plateforme. Si vous voulez obtenir des performances optimales pour une charge de travail donnée, vous devez connaître certains facteurs comme l’architecture matérielle, l’ensemble d’instructions, les modèles d’accès à la mémoire et les formes de données d’entrée. Pour le développement logiciel traditionnel, des outils tels que des compilateurs et des profileurs simplifient le processus. Pour le machine learning, la plupart des outils sont propres au framework ou au matériel. Cela vous oblige à adopter un processus manuel tâtonnant aussi peu fiable qu’inutile.
Neo optimise automatiquement les modèles Gluon, Keras, MXnet,,, PyTorch TensorFlow TensorFlow-Lite, et ONNX pour l'inférence sur les machines Android, Linux et Windows basées sur des processeurs d'Ambarella, ARM, Intel, Nvidia, NXP, Qualcomm, Texas Instruments et Xilinx. Neo est testé avec des modèles de vision par ordinateur disponibles dans les zoos modèles de tous les frameworks. SageMaker Neo prend en charge la compilation et le déploiement pour deux plateformes principales : les instances cloud (y compris Inferentia) et les appareils périphériques.
Pour plus d’informations sur les cadres pris en charge et les types d’instances cloud dans lesquels vous pouvez déployer, consultez Cadres et types d’instance pris en charge pour les instances cloud.
Pour plus d'informations sur les frameworks pris en charge, les appareils Edge, les systèmes d'exploitation, les architectures de puces et les modèles d'apprentissage automatique courants testés par SageMaker AI Neo pour les appareils Edge, voir Cadres, périphériques, systèmes et architectures pris en charge pour les appareils Edge.
Fonctionnement
Neo est composé d’un compilateur et d’un environnement d’exécution. D’abord, l’API de compilateur Neo lit les modèles exportés depuis diverses infrastructures. Il convertit les fonctions et opérations spécifiques au cadre en une représentation intermédiaire agnostique de cadre. Ensuite, il effectue une série d’optimisations. Ensuite, il génère le code binaire pour les opérations optimisées, les écrit dans une bibliothèque d’objets partagés, et enregistre la définitions et les paramètres du modèle dans des fichiers séparés. Neo fournit également un environnement d’exécution pour chaque plateforme cible qui charge et exécute le modèle compilé.
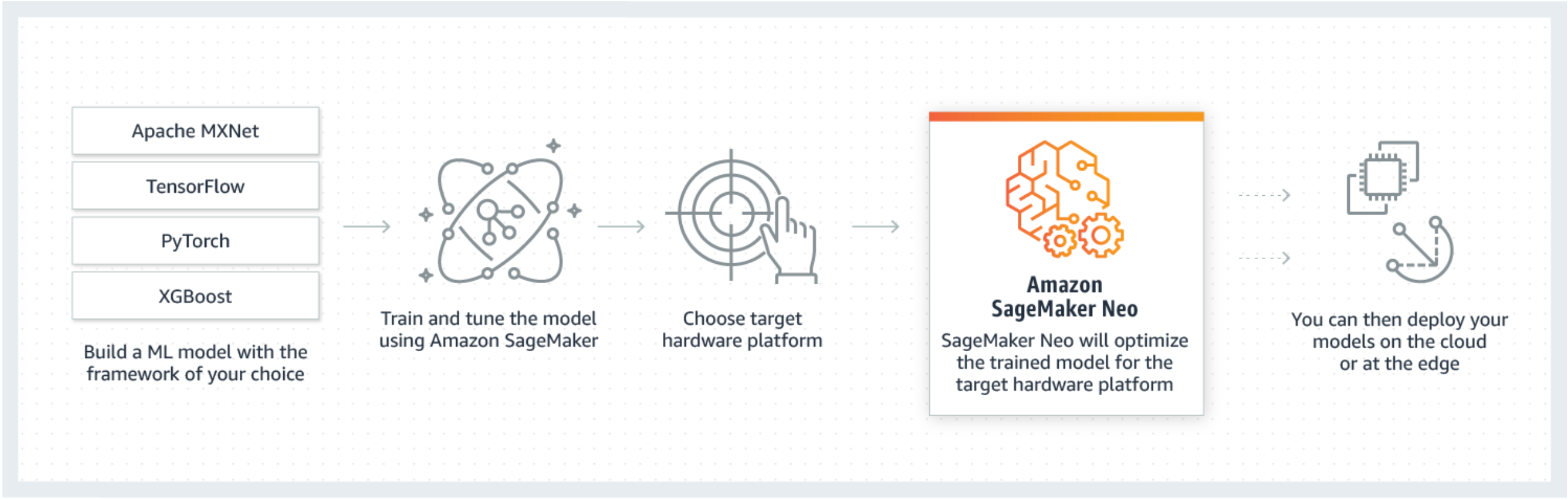
Vous pouvez créer une tâche de compilation Neo à partir de la console SageMaker AI, du AWS Command Line Interface (AWS CLI), d'un bloc-notes Python ou des SDK.For informations de l' SageMaker IA sur la façon de compiler un modèle, voirCompilation de modèles avec Neo. Avec quelques commandes CLI, une invocation d’API ou quelques clics, vous pouvez convertir un modèle pour la plateforme de votre choix. Vous pouvez déployer rapidement le modèle sur un point de terminaison d' SageMaker IA ou sur un AWS IoT Greengrass appareil.
Neo peut optimiser les modèles avec des paramètres en FP32 ou quantifiés à une largeur binaire INT8 ou FP16.
