Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Une fois le traitement SageMaker Clarify terminé, vous pouvez télécharger les fichiers de sortie pour les inspecter, ou vous pouvez visualiser les résultats dans SageMaker Studio Classic. La rubrique suivante décrit les résultats d'analyse générés par SageMaker Clarify, tels que le schéma et le rapport générés par l'analyse des biais, l'analyse SHAP, l'analyse de l'explicabilité de la vision par ordinateur et l'analyse des diagrammes de dépendance partielle ()PDPs. Si l'analyse de configuration contient des paramètres permettant de calculer plusieurs analyses, les résultats sont agrégés dans une analyse et un fichier de rapport.
Le répertoire de sortie de la tâche de traitement SageMaker Clarify contient les fichiers suivants :
-
analysis.json: fichier contenant les métriques de biais et l'importance des fonctionnalités au format JSON. -
report.ipynb: bloc-notes statique qui contient du code pour vous aider à visualiser les métriques de biais et l'importance des fonctionnalités. -
explanations_shap/out.csv: répertoire qui est créé et qui contient les fichiers générés automatiquement en fonction de vos configurations d'analyse spécifiques. Par exemple, si vous activez le paramètresave_local_shap_values, les valeurs SHAP locales par instance seront enregistrées dans le répertoireexplanations_shap. Autre exemple, si votre paramètre de ligne de base SHAPanalysis configurationne contient aucune valeur, la tâche d'explicabilité SageMaker Clarify calcule une ligne de base en regroupant le jeu de données en entrée. Elle enregistre ensuite la base de référence générée dans le répertoire.
Pour des informations plus détaillées, consultez les sections suivantes.
Rubriques
Analyse des biais
Amazon SageMaker Clarify utilise la terminologie décrite dans le document Amazon SageMaker précise les termes relatifs à la partialité et à l'équité pour aborder les questions de partialité et d'équité.
Schéma du fichier d'analyse
Le fichier d'analyse est au format JSON et est organisé en deux sections : les métriques de biais de pré-entraînement et les métriques de biais de post-entraînement. Les paramètres des métriques de biais de pré-entraînement et de post-entraînement sont les suivants.
-
pre_training_bias_metrics : paramètres pour les métriques de biais de pré-entraînement. Pour plus d’informations, consultez Métriques de biais de pré-entraînement et Fichiers de configuration d'analyse.
-
label : nom de l'étiquette de vérité terrain défini par le paramètre
labelde la configuration d'analyse. -
label_value_or_threshold : chaîne contenant les valeurs d'étiquette ou l'intervalle défini par le paramètre
label_values_or_thresholdde la configuration d'analyse. Par exemple, si la valeur1est fournie pour un problème de classification binaire, la chaîne sera1. Si plusieurs valeurs[1,2]sont fournies pour un problème multiclasse, la chaîne sera1,2. Si un seuil40est fourni pour un problème de régression, la chaîne sera d'un type interne comme(40, 68]où68est la valeur maximale de l'étiquette dans le jeu de données en entrée. -
facets : la section contient plusieurs paires clé-valeur, la clé correspondant au nom de facette défini par le paramètre
name_or_indexde la configuration des facettes, et la valeur étant un tableau d'objets facettes. Chaque objet facette contient les membres suivants :-
value_or_threshold : chaîne contenant les valeurs de facette ou l'intervalle défini par le paramètre
value_or_thresholdde la configuration des facettes. -
metrics : la section contient un tableau d'éléments de métriques de biais, et chaque élément de métrique de biais possède les attributs suivants :
-
name : nom abrégé de la métrique de biais. Par exemple,
CI. -
description : nom complet de la métrique de biais. Par exemple,
Class Imbalance (CI). -
value : valeur de la métrique de biais, ou valeur null JSON si la métrique de biais n'est pas calculée pour une raison particulière. Les valeurs ±∞ sont représentées sous la forme des chaînes
∞et-∞respectivement. -
error : message d'erreur facultatif expliquant pourquoi la métrique de biais n'a pas été calculée.
-
-
-
-
post_training_bias_metrics : la section contient les métriques de biais de post-entraînement et suit une disposition et une structure similaires à celles de la section de pré-entraînement. Pour de plus amples informations, veuillez consulter Données post-entraînement et mesures de biais du modèle.
L'exemple suivant est un exemple de configuration d'analyse qui calculera les métriques de biais de pré-entraînement et de post-entraînement.
{
"version": "1.0",
"pre_training_bias_metrics": {
"label": "Target",
"label_value_or_threshold": "1",
"facets": {
"Gender": [{
"value_or_threshold": "0",
"metrics": [
{
"name": "CDDL",
"description": "Conditional Demographic Disparity in Labels (CDDL)",
"value": -0.06
},
{
"name": "CI",
"description": "Class Imbalance (CI)",
"value": 0.6
},
...
]
}]
}
},
"post_training_bias_metrics": {
"label": "Target",
"label_value_or_threshold": "1",
"facets": {
"Gender": [{
"value_or_threshold": "0",
"metrics": [
{
"name": "AD",
"description": "Accuracy Difference (AD)",
"value": -0.13
},
{
"name": "CDDPL",
"description": "Conditional Demographic Disparity in Predicted Labels (CDDPL)",
"value": 0.04
},
...
]
}]
}
}
}Rapport d'analyse des biais
Le rapport d'analyse des biais comprend plusieurs tableaux et diagrammes qui contiennent des explications et des descriptions détaillées. Celles-ci comprennent, entre autres, la distribution des valeurs des étiquettes, la distribution des valeurs des facettes, le diagramme de performance de modèle de haut niveau, un tableau des métriques de biais et leurs descriptions. Pour plus d'informations sur les métriques de biais et sur leur interprétation, consultez le document Découvrez comment Amazon SageMaker Clarify aide à détecter les biais
Analyse SHAP
SageMaker Clarifier les tâches de traitement utilise l'algorithme Kernel SHAP pour calculer les attributions des fonctionnalités. La tâche de traitement SageMaker Clarify produit des valeurs SHAP locales et globales. Elles aident à déterminer la contribution de chaque fonctionnalité pour aboutir aux prédictions du modèle. Les valeurs SHAP locales représentent l'importance des fonctionnalités pour chaque instance individuelle, tandis que les valeurs SHAP globales regroupent les valeurs SHAP locales sur l'ensemble des instances dans le jeu de données. Pour plus d'informations sur les valeurs SHAP et la manière de les interpréter, consultez Attributions de fonctions utilisant des valeurs de Shapley.
Schéma du fichier d'analyse SHAP
Les résultats de l'analyse SHAP globale sont stockés dans la section des explications du fichier d'analyse, sous la méthode kernel_shap. Les différents paramètres du fichier d'analyse SHAP sont les suivants :
-
explanations : section du fichier d'analyse qui contient les résultats de l'analyse de l'importance des fonctionnalités.
-
kernal_shap : section du fichier d'analyse qui contient le résultat de l'analyse SHAP globale.
-
global_shap_values : section du fichier d'analyse qui contient plusieurs paires clé-valeur. Chaque clé de la paire clé-valeur représente un nom de fonctionnalité issu du jeu de données en entrée. Chaque valeur de la paire clé-valeur correspond à la valeur SHAP globale de la fonctionnalité. La valeur SHAP globale est obtenue en agrégeant les valeurs SHAP par instance de la fonctionnalité à l'aide de la configuration
agg_method. Si la configurationuse_logitest activée, la valeur est calculée à l'aide des coefficients de régression logistique, qui peuvent être interprétés comme des ratios log-odds. -
expected_value : prédiction moyenne du jeu de données de référence. Si la configuration de
use_logitest activée, la valeur est calculée à l'aide des coefficients de régression logistique. -
global_top_shap_text — Utilisé pour l'analyse d'explicabilité du NLP. Section du fichier d'analyse qui inclut un ensemble de paires clé-valeur. SageMaker Clarifiez les tâches de traitement, agrégez les valeurs SHAP de chaque jeton, puis sélectionnez les meilleurs jetons en fonction de leurs valeurs SHAP globales. La configuration de
max_top_tokensdéfinit le nombre de jetons à sélectionner.Chacun des jetons principaux sélectionnés possède une paire clé-valeur. La clé de la paire clé-valeur correspond au nom de la fonctionnalité de texte d'un jeton principal. Chaque valeur de la paire clé-valeur correspond aux valeurs SHAP globales du jeton supérieur. Pour un exemple de paire
global_top_shap_textclé-valeur, consultez le résultat suivant.
-
-
L'exemple suivant montre le résultat de l'analyse SHAP d'un jeu de données tabulaire.
{
"version": "1.0",
"explanations": {
"kernel_shap": {
"Target": {
"global_shap_values": {
"Age": 0.022486410860333206,
"Gender": 0.007381025261958729,
"Income": 0.006843906804137847,
"Occupation": 0.006843906804137847,
...
},
"expected_value": 0.508233428001
}
}
}
}L'exemple suivant montre le résultat de l'analyse SHAP d'un jeu de données texte. La sortie correspondant à la colonne Comments est un exemple de sortie générée après l'analyse d'une fonctionnalité de texte.
{
"version": "1.0",
"explanations": {
"kernel_shap": {
"Target": {
"global_shap_values": {
"Rating": 0.022486410860333206,
"Comments": 0.058612104851485144,
...
},
"expected_value": 0.46700941970297033,
"global_top_shap_text": {
"charming": 0.04127962903247833,
"brilliant": 0.02450240786522321,
"enjoyable": 0.024093569652715457,
...
}
}
}
}
}Schéma du fichier de référence généré
Lorsqu'aucune configuration de ligne de base SHAP n'est fournie, la tâche de traitement SageMaker Clarify génère un ensemble de données de référence. SageMaker Clarify utilise un algorithme de clustering basé sur la distance pour générer un ensemble de données de référence à partir des clusters créés à partir du jeu de données en entrée. Le jeu de données de référence obtenu est enregistré dans un fichier CSV, explanations_shap/baseline.csv. Ce fichier de sortie contient une ligne d'en-têtes et plusieurs instances basées sur le paramètre num_clusters, spécifié dans la configuration d'analyse. Le jeu de données de référence se compose uniquement de colonnes de fonctionnalités. L'exemple suivant montre une ligne de base créée en regroupant le jeu de données en entrée.
Age,Gender,Income,Occupation
35,0,2883,1
40,1,6178,2
42,0,4621,0Schéma des valeurs SHAP locales issues de l'analyse d'explicabilité d'un jeu de données tabulaire
Pour les ensembles de données tabulaires, si une seule instance de calcul est utilisée, la tâche de traitement SageMaker Clarify enregistre les valeurs SHAP locales dans un fichier CSV nommé. explanations_shap/out.csv Si vous utilisez plusieurs instances de calcul, les valeurs SHAP locales sont enregistrées dans plusieurs fichiers CSV du répertoire explanations_shap.
Un fichier de sortie contenant des valeurs SHAP locales comporte une ligne contenant les valeurs SHAP locales pour chaque colonne définie par les en-têtes. Les en-têtes suivent la convention de dénomination de Feature_Label selon laquelle le nom de la fonctionnalité est suivi d'un trait de soulignement, puis du nom de votre variable cible.
Pour des problèmes multi-classes, les noms des fonctionnalités dans l'en-tête varient d'abord, puis les étiquettes. Par exemple, deux fonctionnalités F1, F2 et deux classes L1 et L2, dans les en-têtes sont F1_L1, F2_L1, F1_L2 et F2_L2. Si la configuration d'analyse contient une valeur pour le paramètre joinsource_name_or_index, la colonne clé utilisée dans la jointure est ajoutée à la fin du nom de l'en-tête. Cela permet de mapper les valeurs SHAP locales aux instances du jeu de données en entrée. Voici un exemple de fichier de sortie contenant des valeurs SHAP.
Age_Target,Gender_Target,Income_Target,Occupation_Target 0.003937908,0.001388849,0.00242389,0.00274234 -0.0052784,0.017144491,0.004480645,-0.017144491 ...
Schéma des valeurs SHAP locales issues de l'analyse d'explicabilité du NLP
Pour l'analyse d'explicabilité du NLP, si une seule instance de calcul est utilisée, la tâche de traitement SageMaker Clarify enregistre les valeurs SHAP locales dans un fichier JSON Lines nommé. explanations_shap/out.jsonl Si vous utilisez plusieurs instances de calcul, les valeurs SHAP locales sont enregistrées dans plusieurs fichiers JSON Lines du répertoire explanations_shap.
Chaque fichier contenant des valeurs SHAP locales possède plusieurs lignes de données, et chaque ligne est un objet JSON valide. L'objet JSON possède les attributs suivants :
-
explanations : section du fichier d'analyse qui contient un tableau d'explications de Kernel SHAP pour une seule instance. Chaque élément du tableau contient les membres suivants :
-
feature_name : nom d'en-tête des fonctionnalités fournies par la configuration des en-têtes.
-
data_type — Type de fonctionnalité déduit par la tâche de traitement SageMaker Clarify. Les valeurs valides pour les fonctionnalités de texte incluent
numerical,categoricaletfree_text(pour les fonctionnalités de texte). -
attributions : tableau d'objets d'attribution spécifique à une fonctionnalité. Une fonctionnalité de texte peut avoir plusieurs objets d'attribution, chacun pour une unité définie par la configuration
granularity. L'objet d'attribution contient les membres suivants :-
attribution : tableau de valeurs de probabilité spécifique à une classe.
-
description : (pour les fonctionnalités de texte) description des unités de texte.
-
partial_text — Partie du texte expliquée par la tâche de traitement SageMaker Clarify.
-
start_idx : index basé sur zéro permettant d'identifier l'emplacement dans le tableau indiquant le début du fragment de texte partiel.
-
-
-
Voici un exemple d'une seule ligne d'un fichier de valeurs SHAP local, embellie pour améliorer sa lisibilité.
{
"explanations": [
{
"feature_name": "Rating",
"data_type": "categorical",
"attributions": [
{
"attribution": [0.00342270632248735]
}
]
},
{
"feature_name": "Comments",
"data_type": "free_text",
"attributions": [
{
"attribution": [0.005260534499999983],
"description": {
"partial_text": "It's",
"start_idx": 0
}
},
{
"attribution": [0.00424190349999996],
"description": {
"partial_text": "a",
"start_idx": 5
}
},
{
"attribution": [0.010247314500000014],
"description": {
"partial_text": "good",
"start_idx": 6
}
},
{
"attribution": [0.006148907500000005],
"description": {
"partial_text": "product",
"start_idx": 10
}
}
]
}
]
}Rapport d'analyse SHAP
Le rapport d'analyse SHAP fournit un graphique à barres d'un maximum de 10 principales valeurs SHAP globales. L'exemple de graphique suivant montre les valeurs SHAP pour les 4 fonctionnalités principales.
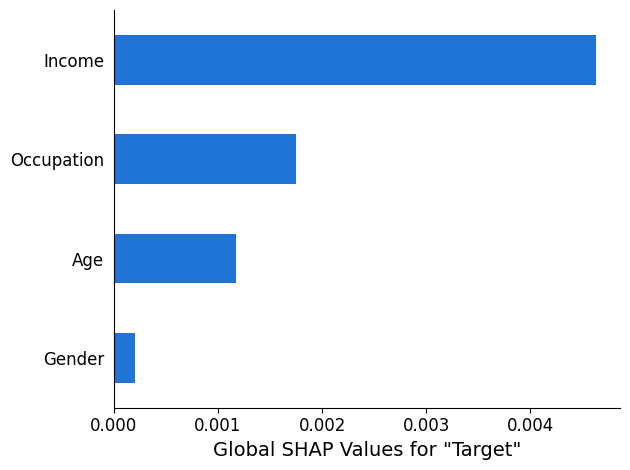
Analyse de l'explicabilité de la vision par ordinateur
SageMaker Clarifier l'explicabilité de la vision par ordinateur prend un ensemble de données composé d'images et traite chaque image comme une collection de super pixels. Après analyse, la tâche de traitement SageMaker Clarify produit un jeu de données d'images dans lequel chaque image montre la carte thermique des superpixels.
L'exemple suivant montre un panneau de limitation de vitesse en entrée sur la gauche et une carte thermique montre l'amplitude des valeurs SHAP sur la droite. Ces valeurs SHAP ont été calculées par un modèle de reconnaissance d'image Resnet-18 entraîné à reconnaître les panneaux de signalisation allemands

Pour plus d'informations, consultez les exemples de carnets expliquant la classification des images avec SageMaker Clarify
Tracés de dépendance partielle (PDPs) Analyse
Les graphiques de dépendance partielle montrent la dépendance de la réponse cible prédite par rapport à un ensemble de fonctionnalités d'entrée intéressantes. Elles sont marginalisées par rapport aux valeurs de toutes les autres fonctions d'entrée et sont désignées sous le nom de fonctions de complément. Intuitivement, vous pouvez interpréter la dépendance partielle comme la réponse cible, qui est attendue comme une fonction de chaque fonction d'entrée intéressante.
Schéma du fichier d'analyse
Les valeurs PDP sont stockées dans la section explanations du fichier d'analyse sous la méthode pdp. Les paramètres pour explanations sont les suivants :
-
explanations : section des fichiers d'analyse qui contient les résultats de l'analyse de l'importance des fonctionnalités.
-
pdp : section du fichier d'analyse qui contient un tableau d'explications de graphiques PDP pour une seule instance. Chaque élément du tableau contient les membres suivants :
-
feature_name : nom d'en-tête des fonctionnalités fourni par la configuration de
headers. -
data_type — Type de fonctionnalité déduit par la tâche de traitement SageMaker Clarify. Les valeurs valides pour
data_typeincluent les valeurs numériques et catégorielles. -
feature_values : contient les valeurs présentes dans la fonctionnalité. Si la valeur
data_typedéduite par SageMaker Clarify est catégorique, ellefeature_valuescontient toutes les valeurs uniques que pourrait être la fonctionnalité. Si la valeurdata_typedéduite par SageMaker Clarify est numérique,feature_valuescontient une liste de la valeur centrale des buckets générés. Le paramètregrid_resolutiondétermine le nombre de compartiments utilisés pour regrouper les valeurs des colonnes de fonctionnalités. -
data_distribution : tableau de pourcentages, où chaque valeur est le pourcentage d'instances que contient un compartiment. Le paramètre
grid_resolutiondétermine le nombre de compartiments. Les valeurs des colonnes de fonctionnalités sont regroupées dans ces compartiments. -
model_predictions : tableau de prédictions de modèle, où chaque élément du tableau est un tableau de prédictions correspondant à une seule classe dans la sortie du modèle.
label_headers : en-têtes d'étiquettes fournis par la configuration de
label_headers. -
error : message d'erreur généré si les valeurs des graphiques PDP ne sont pas calculées pour une raison particulière. Ce message d'erreur remplace le contenu des champs
feature_values,data_distributionsetmodel_predictions.
-
-
Voici un exemple de sortie d'un fichier d'analyse contenant un résultat d'analyse de PDP.
{
"version": "1.0",
"explanations": {
"pdp": [
{
"feature_name": "Income",
"data_type": "numerical",
"feature_values": [1046.9, 2454.7, 3862.5, 5270.2, 6678.0, 8085.9, 9493.6, 10901.5, 12309.3, 13717.1],
"data_distribution": [0.32, 0.27, 0.17, 0.1, 0.045, 0.05, 0.01, 0.015, 0.01, 0.01],
"model_predictions": [[0.69, 0.82, 0.82, 0.77, 0.77, 0.46, 0.46, 0.45, 0.41, 0.41]],
"label_headers": ["Target"]
},
...
]
}
}Rapport d'analyse de PDP
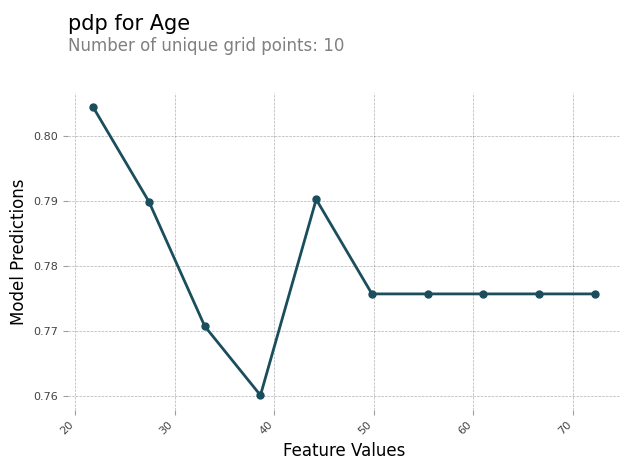
Vous pouvez générer un rapport d'analyse contenant un graphique PDP pour chaque fonctionnalité. Le graphique PDP place feature_values le long de l'axe X et model_predictions le long de l'axe Y. Pour les modèles multiclasses, model_predictions est un tableau, et chaque élément de ce tableau correspond à l'une des classes de prédiction du modèle.
Voici un exemple de graphique PDP pour la fonctionnalité Age. Dans cet exemple de sortie, le graphique PDP indique le nombre de valeurs de fonctionnalité regroupées dans des compartiments. Le nombre de compartiments est déterminé par grid_resolution. Les compartiments de valeurs de fonctionnalité sont tracés par rapport aux prédictions du modèle. Dans cet exemple, les valeurs de fonctionnalité les plus élevées ont les mêmes valeurs de prédiction du modèle.
Valeurs de Shapley asymétriques
SageMaker Clarifier les tâches de traitement : utilisez l'algorithme de valeur asymétrique de Shapley pour calculer les attributions explicatives du modèle de prévision des séries chronologiques. Cet algorithme détermine la contribution des entités en entrée à chaque pas dans le temps vers les prévisions prévisionnelles.
Schéma du fichier d'analyse des valeurs asymétriques de Shapley
Les résultats des valeurs asymétriques de Shapley sont stockés dans un compartiment Amazon S3. Vous trouverez l'emplacement de ce compartiment dans les explications du fichier d'analyse. Cette section contient les résultats de l'analyse de l'importance des fonctionnalités. Les paramètres suivants sont inclus dans le fichier d'analyse des valeurs asymétriques de Shapley.
asymmetric_shapley_value — Section du fichier d'analyse qui contient les métadonnées relatives aux résultats de la tâche d'explication, notamment les suivantes :
explanation_results_path — L'emplacement Amazon S3 avec les résultats de l'explication
direction — Configuration fournie par l'utilisateur pour la valeur de configuration de
directiongranularité — Configuration fournie par l'utilisateur pour la valeur de configuration de
granularity
L'extrait suivant montre les paramètres mentionnés précédemment dans un exemple de fichier d'analyse :
{
"version": "1.0",
"explanations": {
"asymmetric_shapley_value": {
"explanation_results_path": EXPLANATION_RESULTS_S3_URI,
"direction": "chronological",
"granularity": "timewise",
}
}
}Les sections suivantes décrivent comment la structure des résultats de l'explication dépend de la valeur de granularity dans la configuration.
Granularité temporelle
Lorsque la granularité est atteintetimewise, le résultat est représenté dans la structure suivante. La scores valeur représente l'attribution pour chaque horodatage. La offset valeur représente la prédiction du modèle sur les données de référence et décrit le comportement du modèle lorsqu'il ne reçoit pas de données.
L'extrait suivant montre un exemple de sortie pour un modèle qui fait des prédictions pour deux étapes temporelles. Par conséquent, toutes les attributions sont des listes de deux éléments dont la première entrée fait référence au premier pas temporel prévu.
{
"item_id": "item1",
"offset": [1.0, 1.2],
"explanations": [
{"timestamp": "2019-09-11 00:00:00", "scores": [0.11, 0.1]},
{"timestamp": "2019-09-12 00:00:00", "scores": [0.34, 0.2]},
{"timestamp": "2019-09-13 00:00:00", "scores": [0.45, 0.3]},
]
}
{
"item_id": "item2",
"offset": [1.0, 1.2],
"explanations": [
{"timestamp": "2019-09-11 00:00:00", "scores": [0.51, 0.35]},
{"timestamp": "2019-09-12 00:00:00", "scores": [0.14, 0.22]},
{"timestamp": "2019-09-13 00:00:00", "scores": [0.46, 0.31]},
]
}Granularité fine
L'exemple suivant illustre les résultats d'attribution lorsque la granularité est fine_grained définie. La offset valeur a la même signification que celle décrite dans la section précédente. Les attributions sont calculées pour chaque entité en entrée à chaque horodatage d'une série chronologique cible et des séries chronologiques associées, si elles sont disponibles, et pour chaque covariable statique, si disponible.
{
"item_id": "item1",
"offset": [1.0, 1.2],
"explanations": [
{"feature_name": "tts_feature_name_1", "timestamp": "2019-09-11 00:00:00", "scores": [0.11, 0.11]},
{"feature_name": "tts_feature_name_1", "timestamp": "2019-09-12 00:00:00", "scores": [0.34, 0.43]},
{"feature_name": "tts_feature_name_2", "timestamp": "2019-09-11 00:00:00", "scores": [0.15, 0.51]},
{"feature_name": "tts_feature_name_2", "timestamp": "2019-09-12 00:00:00", "scores": [0.81, 0.18]},
{"feature_name": "rts_feature_name_1", "timestamp": "2019-09-11 00:00:00", "scores": [0.01, 0.10]},
{"feature_name": "rts_feature_name_1", "timestamp": "2019-09-12 00:00:00", "scores": [0.14, 0.41]},
{"feature_name": "rts_feature_name_1", "timestamp": "2019-09-13 00:00:00", "scores": [0.95, 0.59]},
{"feature_name": "rts_feature_name_1", "timestamp": "2019-09-14 00:00:00", "scores": [0.95, 0.59]},
{"feature_name": "rts_feature_name_2", "timestamp": "2019-09-11 00:00:00", "scores": [0.65, 0.56]},
{"feature_name": "rts_feature_name_2", "timestamp": "2019-09-12 00:00:00", "scores": [0.43, 0.34]},
{"feature_name": "rts_feature_name_2", "timestamp": "2019-09-13 00:00:00", "scores": [0.16, 0.61]},
{"feature_name": "rts_feature_name_2", "timestamp": "2019-09-14 00:00:00", "scores": [0.95, 0.59]},
{"feature_name": "static_covariate_1", "scores": [0.6, 0.1]},
{"feature_name": "static_covariate_2", "scores": [0.1, 0.3]},
]
}Dans timewise les deux cas fine-grained d'utilisation, les résultats sont stockés au format JSON Lines (.jsonl).
