Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Démarrer avec Data Wrangler
Amazon SageMaker Data Wrangler est une fonctionnalité d'Amazon SageMaker Studio Classic. Cette section vous montre comment accéder à Data Wrangler et commencer à l’utiliser. Procédez comme suit :
-
Effectuez chaque étape dans Conditions préalables.
-
Suivez la procédure décrite dans Accéder à Data Wrangler pour commencer à utiliser Data Wrangler.
Conditions préalables
Pour utiliser Data Wrangler, vous devez satisfaire aux prérequis suivants.
-
Pour utiliser Data Wrangler, vous devez accéder à une instance Amazon Elastic Compute Cloud (Amazon EC2). Pour plus d'informations sur les instances Amazon EC2 que vous pouvez utiliser, consultez instances. Pour savoir comment consulter vos quotas et, le cas échéant, demander leur augmentation, consultez Quotas de service AWS.
-
Configurez les autorisations requises décrites dans Sécurité et autorisations.
-
Si votre entreprise utilise un pare-feu qui bloque le trafic Internet, vous devez avoir accès aux URL suivantes :
-
https://ui.prod-1.data-wrangler.sagemaker.aws/ -
https://ui.prod-2.data-wrangler.sagemaker.aws/ -
https://ui.prod-3.data-wrangler.sagemaker.aws/ -
https://ui.prod-4.data-wrangler.sagemaker.aws/
-
Pour utiliser Data Wrangler, vous avez besoin d’une instance Studio Classic active. Pour en savoir plus sur le lancement d’une nouvelle instance, consultez Présentation du domaine Amazon SageMaker AI. Lorsque votre instance Studio Classic est Prête, utilisez les instructions fournies dans Accéder à Data Wrangler.
Accéder à Data Wrangler
La procédure suivante suppose que vous avez terminé l’étape Conditions préalables.
Pour accéder à Data Wrangler dans Studio Classic, procédez comme suit.
-
Connectez-vous à Studio Classic. Pour de plus amples informations, veuillez consulter Présentation du domaine Amazon SageMaker AI.
-
Choisissez Studio.
-
Choisissez Lancer l’application.
-
Dans la liste déroulante, sélectionnez Studio.
-
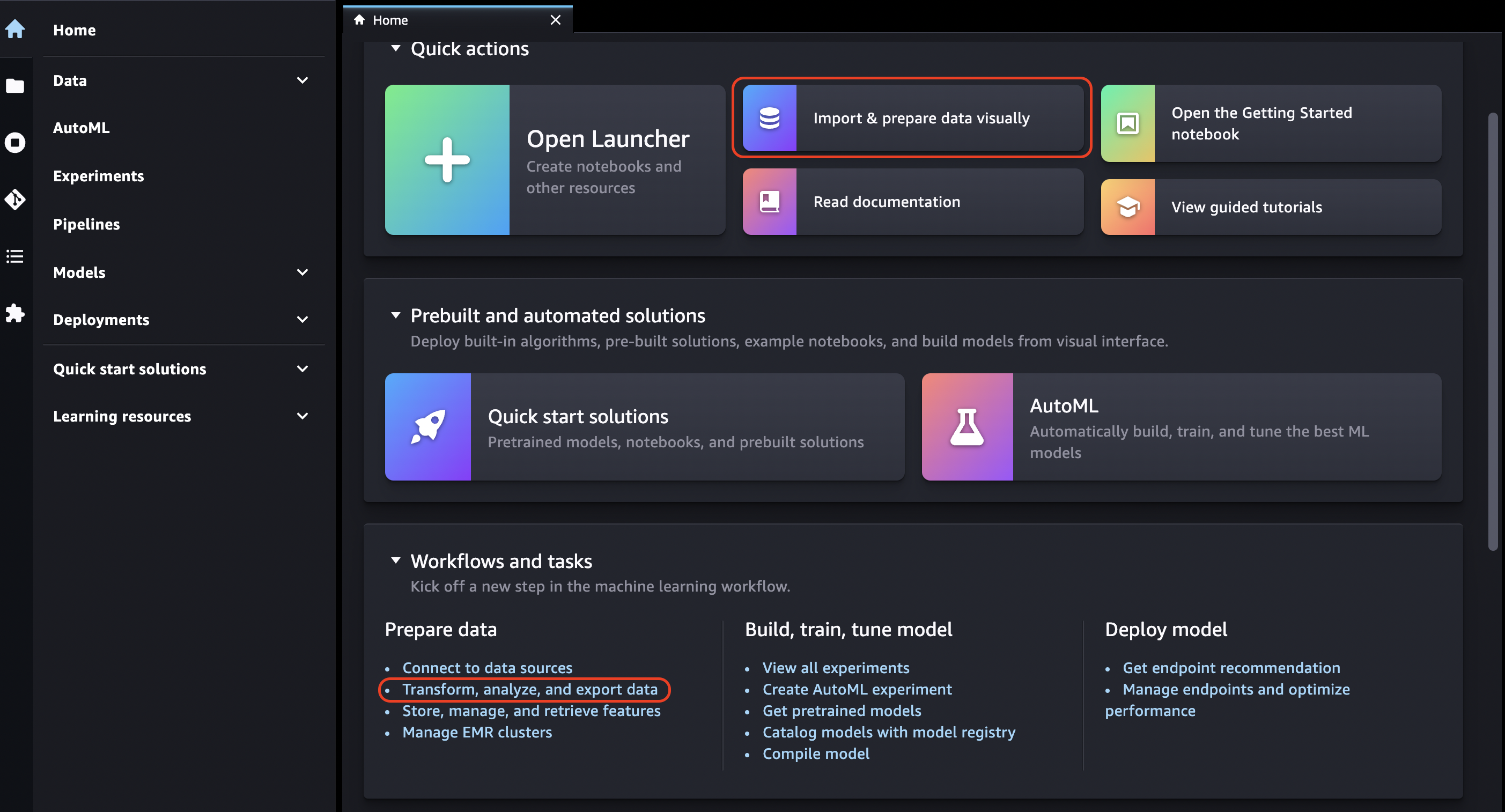
Choisissez l'icône d'accueil.
-
Choisissez Données.
-
Choisissez Data Wrangler.
-
Vous pouvez également créer un flux Data Wrangler en procédant comme suit.
-
Dans la barre de navigation supérieure, sélectionnez File (Fichier).
-
Sélectionnez New (Nouveau).
-
Sélectionnez Data Wrangler Flow (Flux Data Wrangler).
-
-
(Facultatif) Renommez le nouveau répertoire et le fichier .flow.
-
Lorsque vous créez un nouveau fichier .flow dans Studio Classic, vous pouvez voir un carrousel qui vous présente Data Wrangler.
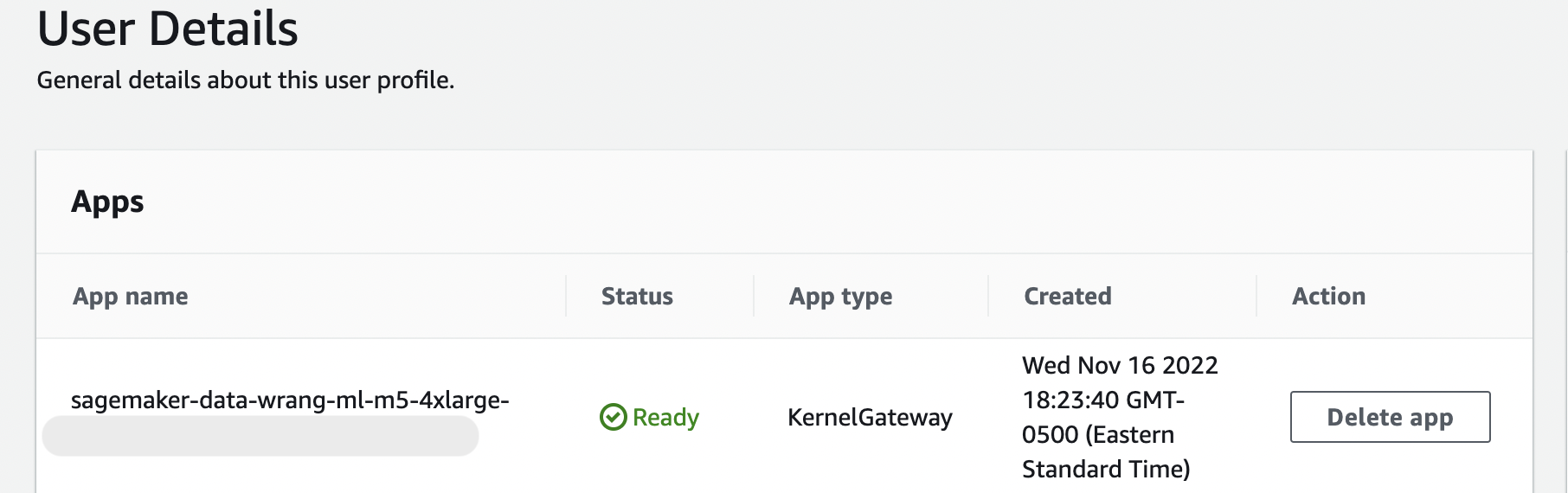
Cette opération peut prendre quelques minutes.
Ce message persiste tant que l'KernelGatewayapplication sur votre page d'informations utilisateur est en attente. Pour connaître le statut de cette application, dans la console SageMaker AI de la page Amazon SageMaker Studio Classic, sélectionnez le nom de l'utilisateur que vous utilisez pour accéder à Studio Classic. Sur la page Informations utilisateur, vous pouvez voir une KernelGatewayapplication sous Applications. Attendez que l'état de l'appli passe à Ready (Prêt) pour commencer à utiliser Data Wrangler. Cela peut prendre environ 5 minutes la première fois que vous lancez Data Wrangler.
-
Pour commencer, choisissez une source de données et utilisez-la pour importer un jeu de données. Pour en savoir plus, consultez Importer.
Lorsque vous importez un jeu de données, il apparaît dans votre flux de données. Pour en savoir plus, consultez Créer et utiliser un flux Data Wrangler.
-
Après avoir importé un jeu de données, Data Wrangler déduit automatiquement le type de données dans chaque colonne. Cliquez sur + à côté de l'étape Data types (Types de données) et cliquez sur Edit data types (Modification des types de données).
Important
Après avoir ajouté des transformations à l'étape Data types (Types de données), vous ne pouvez pas mettre à jour en bloc les types de colonne en utilisant Update types (Mise à jour des types).
-
Utilisez le flux de données pour ajouter des transformations et des analyses. Pour en savoir plus, consultez les rubriques Transformation de données et Analyse et visualisation.
-
Pour exporter un flux de données complet, cliquez sur Export (Exporter) et choisissez une option d'exportation. Pour en savoir plus, consultez Exporter.
-
Enfin, cliquez sur l'icône Components and registries (Composants et registres), puis sélectionnez Data Wrangler dans la liste déroulante pour afficher tous les fichiers .flow que vous avez créés. Vous pouvez utiliser ce menu pour rechercher des flux de données et passer d’un flux à l’autre.
Une fois que vous avez lancé Data Wrangler, vous pouvez utiliser la section suivante pour découvrir comment utiliser Data Wrangler afin de créer un flux de préparation de données ML.
Mettre à jour Data Wrangler
Nous recommandons de mettre régulièrement à jour l’application Data Wrangler Studio Classic pour accéder aux dernières fonctionnalités et mises à jour. Le nom de l’application Data Wrangler commence par sagemaker-data-wrang. Pour savoir comment mettre à jour une application Studio Classic, consultez Arrêter et mettre à jour les applications Amazon SageMaker Studio Classic.
Démo : Démonstration du jeu de données Titanic de Data Wrangler
Les sections suivantes fournissent une démonstration pour vous aider à débuter à l'aide de Data Wrangler. Cette démonstration présume que vous avez déjà suivi les étapes décrites dans Accéder à Data Wrangler et que vous avez ouvert un nouveau fichier de flux de données que vous avez l’intention d’utiliser pour la démonstration. Vous pouvez renommer ce fichier .flow en titanic-demo.flow, par exemple.
Cette démonstration utilise le jeu de données Titanic
Dans ce tutoriel, vous exécuterez les étapes suivantes.
-
Effectuez l’une des actions suivantes :
-
Ouvrez votre flux Data Wrangler et choisissez Use Sample Dataset (Utiliser un exemple de jeu de données).
-
Chargez le jeu de données Titanic
sur Amazon Simple Storage Service (Amazon S3), puis importez-le dans Data Wrangler.
-
-
Analysez ce jeu de données à l'aide des analyses Data Wrangler.
-
Définissez un flux de données à l'aide des transformations Data Wrangler.
-
Exportez votre flux vers un bloc-notes Jupyter que vous pouvez utiliser pour créer une tâche Data Wrangler.
-
Traitez vos données et lancez un travail de SageMaker formation pour former un classificateur binaire XGBoost.
Charger un jeu de données vers S3 et l’importer
Pour commencer, vous pouvez utiliser l'une des méthodes suivantes pour importer le jeu de données Titanic dans Data Wrangler :
-
Importation du jeu de données directement depuis le flux Data Wrangler
-
Chargement du jeu de données sur Amazon S3, suivi de son importation dans Data Wrangler
Pour importer le jeu de données directement dans Data Wrangler, ouvrez le flux et choisissez Use Sample Dataset (Utiliser un exemple de jeu de données).
Le chargement du jeu de données sur Amazon S3 et son importation dans Data Wrangler se rapprochent de l'expérience que vous connaissez en important vos propres données. Les informations suivantes vous indiquent comment charger votre jeu de données et l'importer.
Avant de commencer l'importation des données dans Data Wrangler, téléchargez le jeu de données Titanic
Si vous êtes un nouvel utilisateur d’Amazon S3, vous pouvez le faire en utilisant le glisser-déposer dans la console Amazon S3. Pour savoir comment procéder, consultez Chargement de fichiers et de dossiers par glisser-déposer dans le Guide de l’utilisateur Amazon Simple Storage Service.
Important
Téléchargez votre ensemble de données dans un compartiment S3 de la même AWS région que celle que vous souhaitez utiliser pour terminer cette démonstration.
Lorsque votre jeu de données a été chargé avec succès sur Amazon S3, vous pouvez l'importer dans Data Wrangler.
Importer le jeu de données Titanic dans Data Wrangler
-
Cliquez sur le bouton Import data (Importer des données) dans l'onglet Data flow (Flux de données) ou choisissez l'onglet Import (Importer).
-
Cliquez sur Amazon S3.
-
Utilisez le tableau Import a dataset from S3 (Importer un jeu de données depuis S3) pour trouver le compartiment dans lequel vous avez ajouté le jeu de données Titanic. Choisissez le fichier CSV du jeu de données Titanic pour ouvrir la boîte de dialogue Details (Détails).
-
Sous (Details (Détails), le File type (Type de fichier) devrait être CSV. Cochez la case First row is header (La première ligne est un en-tête) pour spécifier que la première ligne du jeu de données est un en-tête. Vous pouvez également nommer le jeu de données de manière plus conviviale, par exemple
Titanic-train. -
Cliquez sur le bouton Import (Importer).
Lorsque votre jeu de données est importé dans Data Wrangler, il apparaît dans votre onglet Data Flow (Flux de données). Vous pouvez double-cliquer sur un nœud pour accéder à la vue détaillée du nœud, qui vous permet d'ajouter des transformations ou des analyses. Vous pouvez également utiliser l'icône « plus » pour naviguer rapidement. Dans la section suivante, vous utilisez ce flux de données pour ajouter des étapes d’analyse et de transformation.
Flux de données
Dans la section dédiée au flux de données, les seules étapes du flux de données sont votre jeu de données récemment importé et une étape Data type (Type de données). Après avoir appliqué des transformations, vous pouvez revenir à cet onglet pour voir à quoi ressemble le flux de données. Maintenant, ajoutez quelques transformations de base sous les onglets Prepare (Préparation) et Analyze (Analyse).
Préparer et visualiser
Data Wrangler dispose de transformations et de visualisations intégrées que vous pouvez utiliser pour analyser, nettoyer et transformer vos données.
L'onglet Data (Données) de la vue détaillée du nœud répertorie toutes les transformations intégrées dans le panneau de droite, qui contient également une zone dans laquelle vous pouvez ajouter des transformations personnalisées. Le cas d’utilisation suivant montre comment utiliser ces transformations.
Pour obtenir des informations susceptibles de vous aider dans l'exploration des données et l'ingénierie des fonctionnalités, créez un rapport d'informations et de qualité des données. Les informations de ce rapport peuvent vous aider à nettoyer et à traiter vos données. Il fournit des informations telles que le nombre de valeurs manquantes et le nombre de valeurs aberrantes. Si vous rencontrez des problèmes avec vos données, tels que des déséquilibres ou des fuites de caractéristique cible, le rapport d’informations peut signaler ces problèmes. Pour plus d'informations sur la création d'un rapport, consultez Obtention d’informations sur les données et la qualité des données.
Exploration des données
D'abord, créez un tableau récapitulatif des données à l'aide d'une analyse. Procédez comme suit :
-
Cliquez sur + à côté de l'étape Data type (Type de données) dans votre flux de données et sélectionnez Add analysis (Ajouter une analyse).
-
Dans la zone Analyze (Analyse), sélectionnez Table summary (Résumé du tableau) dans la liste déroulante.
-
Donnez un Name (Nom) au résumé du tableau.
-
Sélectionnez Preview (Aperçu) pour avoir un aperçu du tableau qui sera créé.
-
Choisissez Save (Enregistrer) pour l'enregistrer dans votre flux de données. Il apparaît sous All Analyses (Toutes les analyses).
En utilisant les statistiques que vous voyez, vous pouvez faire des observations similaires aux suivantes sur ce jeu de données :
-
Le tarif moyen est d'environ 33 dollars, tandis que le tarif maximum est de plus de 500 dollars. Cette colonne comporte probablement des valeurs aberrantes.
-
Ce jeu de données utilise ? pour indiquer les valeurs manquantes. Un certain nombre de colonnes ont des valeurs manquantes : cabin (cabine), embarked (embarqué), et home.dest (origine.destination)
-
Il manque plus de 250 valeurs dans la catégorie d’âge.
Ensuite, nettoyez vos données en utilisant les informations obtenues grâce à ces statistiques.
Supprimez les colonnes inutilisées
À l'aide de l'analyse de la section précédente, nettoyez le jeu de données pour le préparer à l'entraînement. Pour ajouter une nouvelle transformation à votre flux de données, cliquez sur + à côté de l'étape Data type (Type de données) dans votre flux de données et choisissez Add transform (Ajouter une transformation).
Supprimez d'abord les colonnes que vous ne souhaitez pas utiliser pour l'entraînement. Pour cela, vous pouvez utiliser la bibliothèque d'analyse de données pandas
Suivez la procédure ci-dessous pour supprimer les colonnes inutilisées.
Pour supprimer les colonnes inutilisées.
-
Ouvrez le flux Data Wrangler.
-
Votre flux Data Wrangler comporte deux nœuds. Choisissez le + à droite du nœud Data types (Types de données).
-
Choisissez Ajouter une transformation.
-
Dans la colonne All steps (Toutes les étapes), choisissez Add step (Ajouter une étape).
-
Dans la liste des transformations Standard, choisissez Manage Columns (Gérer les colonnes). Les transformations standard sont des transformations intégrées prêtes à l'emploi. Assurez-vous que l'option Drop column (Supprimer la colonne) est sélectionnée.
-
Sous Columns to drop (Colonnes à supprimer), cochez les noms de colonne suivants :
-
cabin
-
ticket
-
name
-
sibsp
-
parch
-
home.dest
-
boat
-
body
-
-
Choisissez Preview (Aperçu).
-
Vérifiez que les colonnes ont été supprimées, puis cliquez sur Add (Ajouter).
Pour effectuer cela avec pandas, procédez comme suit.
-
Dans la colonne All steps (Toutes les étapes), choisissez Add step (Ajouter une étape).
-
Dans la liste de transformation Custom (Personnalisée), choisissez Custom transform (Transformation personnalisée).
-
Donnez un nom à votre transformation, puis sélectionnez Python (Pandas) dans la liste déroulante.
-
Saisissez le script Python suivant dans la zone de code.
cols = ['name', 'ticket', 'cabin', 'sibsp', 'parch', 'home.dest','boat', 'body'] df = df.drop(cols, axis=1) -
Cliquez sur Preview (Aperçu) pour afficher un aperçu de la modification, puis cliquez sur Add (Ajouter) pour ajouter la transformation.
Nettoyer les valeurs manquantes
Maintenant, nettoyez les valeurs manquantes. Vous pouvez le faire avec le groupe de transformation Handling missing values (Traitement des valeurs manquantes).
Un certain nombre de colonnes ont des valeurs manquantes. Parmi les autres colonnes, age (âge) et fare (tarif)contiennent des valeurs manquantes. Inspectez cela à l'aide d'une transformation Custom Transform (Transformation personnalisée).
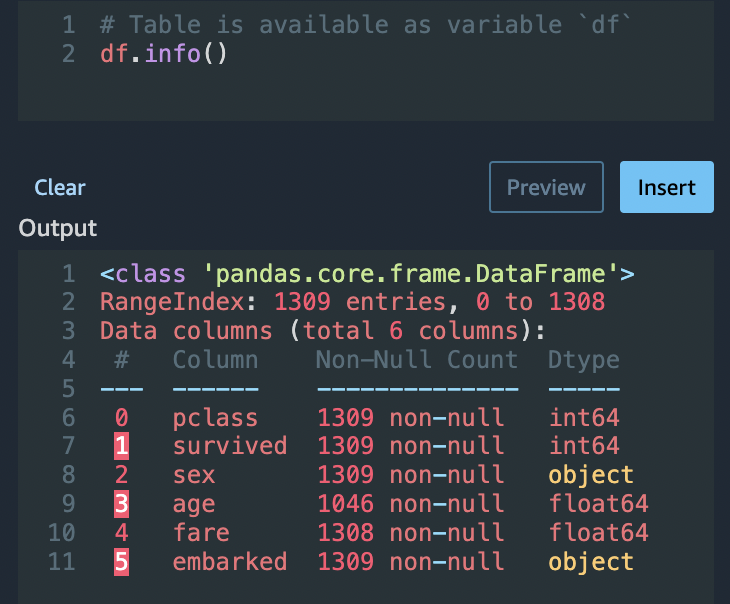
En utilisant l’option Python (Pandas), utilisez ce qui suit pour examiner rapidement le nombre d’entrées dans chaque colonne :
df.info()
Pour supprimer des lignes avec des valeurs manquantes dans la catégorie age (âge), procédez comme suit :
-
Choisissez Handle missing (Gérer les valeurs manquantes).
-
Choisissez Drop missing (Supprimer les valeurs manquantes) pour Transformation.
-
Choisissez age (âge) pour Input column (Colonne d’entrée).
-
Cliquez sur Preview (Aperçu) pour voir le nouveau bloc de données, puis cliquez sur Add (Ajouter) pour ajouter la transformation à votre flux.
-
Répétez le même processus pour fare (tarif).
Vous pouvez utiliser df.info() dans la section Custom Transformation (Transformation personnalisée) pour confirmer que toutes les lignes ont désormais 1 045 valeurs.
Pandas personnalisé : encodage
Essayez l'encodage plat à l'aide de Pandas. Le codage des données catégorielles est le processus de création d’une représentation numérique pour les catégories. Par exemple, si vos catégories sont Dog et Cat, vous pouvez encoder ces informations en deux vecteurs : [1,0] pour représenter Dog, et [0,1] pour représenter Cat.
-
Dans la section Custom Transform (Transformation personnalisée), sélectionnez Python (Pandas) dans la liste déroulante.
-
Saisissez le texte suivant dans la zone de code.
import pandas as pd dummies = [] cols = ['pclass','sex','embarked'] for col in cols: dummies.append(pd.get_dummies(df[col])) encoded = pd.concat(dummies, axis=1) df = pd.concat((df, encoded),axis=1) -
Cliquez sur Preview (Aperçu) pour afficher un aperçu de la modification. La version encodée de chaque colonne est ajoutée au jeu de données.
-
Cliquez sur Add (Ajouter) pour ajouter la transformation.
SQL personnalisé : colonnes SELECT
Maintenant, sélectionnez les colonnes que vous voulez conserver en utilisant SQL. Pour cette démonstration, sélectionnez les colonnes listées dans l'instruction SELECT suivante. Etant donné que survived (a survécu) est votre colonne cible pour l'entraînement, mettez cette colonne en premier.
-
Dans la section Transformation personnalisée, sélectionnez SQL (PySpark SQL) dans la liste déroulante.
-
Saisissez le texte suivant dans la zone de code.
SELECT survived, age, fare, 1, 2, 3, female, male, C, Q, S FROM df; -
Cliquez sur Preview (Aperçu) pour afficher un aperçu de la modification. Les colonnes énumérées dans votre instruction
SELECTsont les seules colonnes restantes. -
Cliquez sur Add (Ajouter) pour ajouter la transformation.
Exportation vers un bloc-notes Data Wrangler
Lorsque vous avez terminé de créer un flux de données, vous disposez de plusieurs options d’exportation. La section suivante explique comment exporter vers un bloc-notes de tâches Data Wrangler. Une tâche Data Wrangler est utilisée pour traiter vos données en suivant les étapes définies dans votre flux de données. Pour en savoir plus sur toutes les options d’exportation, consultez Exporter.
Exporter vers un bloc-notes de tâches Data Wrangler
Lorsque vous exportez votre flux de données à l’aide d’une tâche Data Wrangler, le processus crée automatiquement un bloc-notes Jupyter. Ce bloc-notes s'ouvre automatiquement dans votre instance Studio Classic et est configuré pour exécuter une tâche de SageMaker traitement afin d'exécuter votre flux de données Data Wrangler, appelée tâche Data Wrangler.
-
Sauvegardez votre flux de données. Sélectionnez File (Fichier) et cliquez sur Save Data Wrangler Flow (Enregistrer le flux Data Wrangler).
-
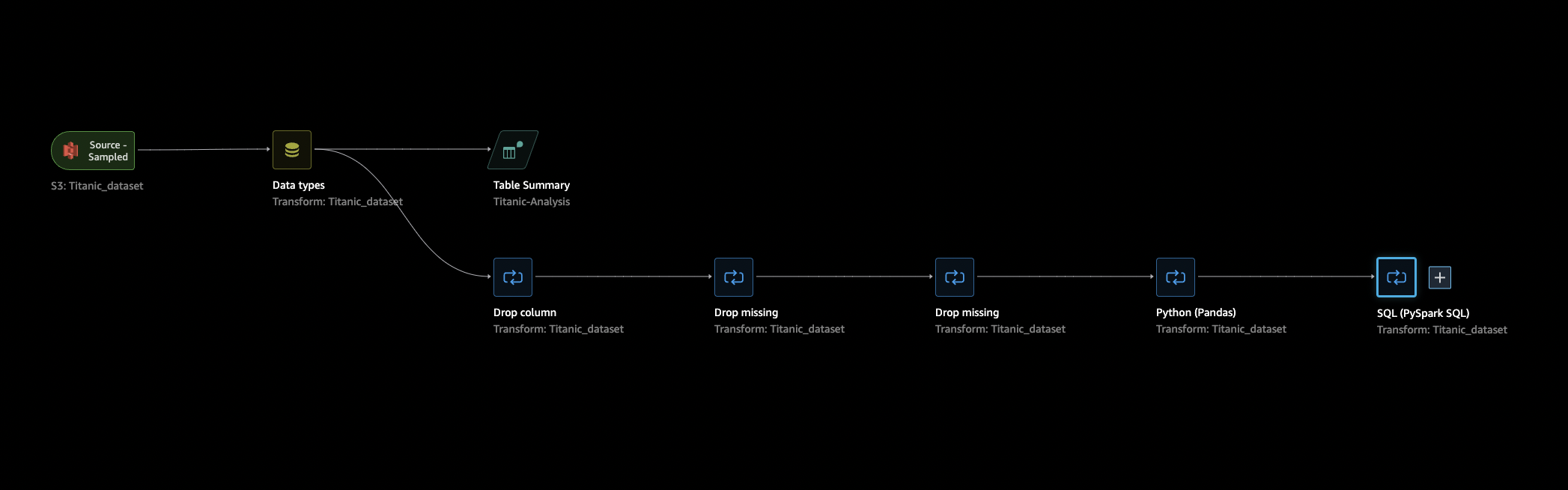
Revenez à l'onglet Data Flow (Flux de données), sélectionnez la dernière étape de votre flux de données (SQL), puis cliquez sur le + pour ouvrir la navigation.
-
Choisissez Export (Exporter) et Amazon S3 (via Jupyter Notebook) (Amazon S3 (via le bloc-notes Jupyter)). Un bloc-notes Jupyter s’ouvre.
-
Choisissez n’importe quel noyau Python 3 (Science des données) pour Kernel (Noyau).
-
Lorsque le noyau démarre, exécutez les cellules du bloc-notes jusqu'à Kick off SageMaker Training Job (facultatif).
-
Vous pouvez éventuellement exécuter les cellules dans Kick off SageMaker Training Job (facultatif) si vous souhaitez créer une tâche de formation en SageMaker IA pour entraîner un classificateur XGBoost. Vous trouverez le coût d'une SageMaker formation sur Amazon SageMaker Pricing
. Sinon, vous pouvez ajouter les blocs de code trouvés dans Entraînement d’un classificateur XGBoost sur le bloc-notes et les exécuter pour utiliser la bibliothèque open source XGBoost
afin d’entraîner un classificateur XGBoost. -
Décommentez, exécutez la cellule sous Cleanup et exécutez-la pour rétablir la version d'origine du SDK SageMaker Python.
Vous pouvez surveiller l'état de votre tâche Data Wrangler dans la console SageMaker AI, dans l'onglet Traitement. En outre, vous pouvez surveiller votre travail avec Data Wrangler à l'aide d'Amazon. CloudWatch Pour plus d'informations, consultez Surveiller les tâches de SageMaker traitement Amazon à l'aide de CloudWatch journaux et de métriques.
Si vous avez lancé une tâche de formation, vous pouvez suivre son statut à l'aide de la console SageMaker AI sous Tâches de formation dans la section Formation.
Entraînement d’un classificateur XGBoost
Vous pouvez entraîner un classificateur binaire XGBoost à l'aide d'un bloc-notes Jupyter ou d'un pilote automatique Amazon. SageMaker Vous pouvez utiliser Autopilot pour entraîner et régler automatiquement les modèles sur les données que vous avez transformées directement à partir de votre flux Data Wrangler. Pour obtenir des informations sur Autopilot, consultez Entraînement automatique des modèles sur votre flux de données.
Dans le même bloc-notes que celui qui a lancé la tâche Data Wrangler, vous pouvez extraire les données et entraîner un classificateur binaire XGBoost en utilisant les données préparées avec une préparation minimale des données.
-
Tout d’abord, mettez à niveau les modules nécessaires en utilisant
pipet supprimez le fichier _SUCCESS (ce dernier fichier est problématique lors de l’utilisation deawswrangler).! pip install --upgrade awscli awswrangler boto sklearn ! aws s3 rm {output_path} --recursive --exclude "*" --include "*_SUCCESS*" -
Lisez les données depuis Amazon S3. Vous pouvez utiliser
awswranglerpour lire récursivement tous les fichiers CSV dans le préfixe S3. Les données sont ensuite divisées en ressources et en étiquettes. L'étiquette est la première colonne du dataframe.import awswrangler as wr df = wr.s3.read_csv(path=output_path, dataset=True) X, y = df.iloc[:,:-1],df.iloc[:,-1]-
Enfin, créez DMatrices (la structure primitive XGBoost pour les données) et effectuez une validation croisée en utilisant la classification binaire XGBoost.
import xgboost as xgb dmatrix = xgb.DMatrix(data=X, label=y) params = {"objective":"binary:logistic",'learning_rate': 0.1, 'max_depth': 5, 'alpha': 10} xgb.cv( dtrain=dmatrix, params=params, nfold=3, num_boost_round=50, early_stopping_rounds=10, metrics="rmse", as_pandas=True, seed=123)
-
Arrêter Data Wrangler
Lorsque vous avez terminé d'utiliser Data Wrangler, nous vous recommandons d'arrêter l'instance sur laquelle il s'exécute pour éviter d'encourir des frais supplémentaires. Pour savoir comment arrêter l’appli Data Wrangler et l’instance associée, consultez Arrêter Data Wrangler.
