Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Test de modèles avec des variantes de production
Dans les flux de travail ML de production, les scientifiques des données et les ingénieurs tentent souvent d'améliorer leurs performances de différentes manières, par exemple Réglage automatique du modèle grâce à l' SageMaker IA, l'entraînement sur des données supplémentaires ou plus récentes, et une meilleure sélection des fonctions avec des instances et des conteneurs en service améliorés et mis à jour. Vous pouvez utiliser des variantes de production pour comparer vos modèles, instances et conteneurs, et choisir le candidat le plus performant pour répondre aux demandes d'inférence.
Avec les points de terminaison multivariants SageMaker AI, vous pouvez répartir les demandes d'invocation des points de terminaison entre plusieurs variantes de production en fournissant la distribution du trafic pour chaque variante, ou vous pouvez invoquer une variante spécifique directement pour chaque demande. Dans cette rubrique, nous examinons les deux méthodes de test des modèles ML.
Rubriques
Test des modèles en spécifiant la répartition du trafic
Pour tester plusieurs modèles en répartissant le trafic entre eux, spécifiez le pourcentage du trafic qui est acheminé vers chaque modèle en spécifiant la pondération de chaque variante de production dans la configuration du point de terminaison. Pour plus d'informations, consultez CreateEndpointConfig. Le diagramme suivant montre de façon détaillée comment cela fonctionne.

Test des modèles en appelant des variantes spécifiques
Pour tester plusieurs modèles en invoquant des modèles spécifiques pour chaque demande, spécifiez la version spécifique du modèle que vous souhaitez invoquer en fournissant une valeur pour le TargetVariant paramètre lors de l'appel InvokeEndpoint. SageMaker L'IA garantit que la demande est traitée par la variante de production que vous spécifiez. Si vous avez déjà fourni la répartition du trafic et que vous spécifiez une valeur pour le paramètre TargetVariant, le routage ciblé remplace la répartition aléatoire du trafic. Le diagramme suivant montre de façon détaillée comment cela fonctionne.
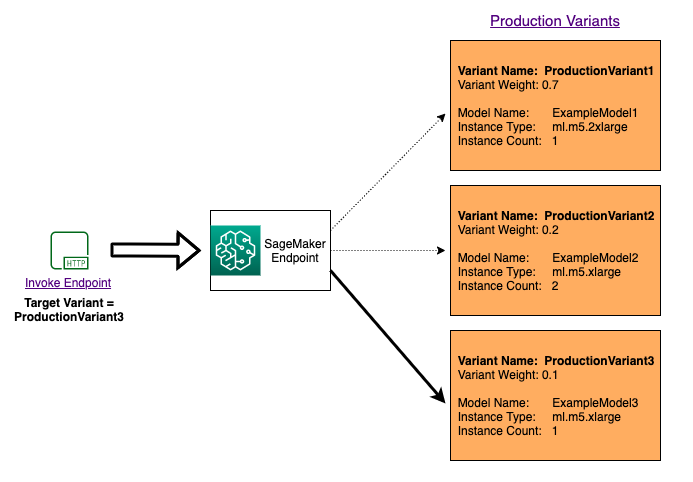
Exemple de A/B test de modèle
La réalisation de A/B tests entre un nouveau modèle et un ancien modèle avec du trafic de production peut constituer une étape finale efficace du processus de validation d'un nouveau modèle. Lors A/B des tests, vous testez différentes variantes de vos modèles et comparez les performances de chaque variante. Si la version la plus récente du modèle offre de meilleures performances que la version précédente existante, remplacez l'ancienne version du modèle par la nouvelle version en production.
L'exemple suivant montre comment effectuer des tests de A/B modèles. Pour un exemple de bloc-notes implémentant cet exemple, reportez-vous à « A/B Tester des modèles ML en production
Étape 1 : Créer et déployer des modèles
Tout d'abord, nous définissons l'emplacement de nos modèles dans Amazon S3. Ces emplacements sont utilisés lorsque nous déployons nos modèles dans les étapes suivantes :
model_url = f"s3://{path_to_model_1}" model_url2 = f"s3://{path_to_model_2}"
Ensuite, nous créons les objets du modèle avec les données d'image et de modèle. Ces objets de modèle sont utilisés pour déployer des variantes de production sur un point de terminaison. Les modèles sont développés en entraînant des modèles ML sur différents ensembles de données, différents algorithmes ou frameworks ML et différents hyperparamètres :
from sagemaker.amazon.amazon_estimator import get_image_uri model_name = f"DEMO-xgb-churn-pred-{datetime.now():%Y-%m-%d-%H-%M-%S}" model_name2 = f"DEMO-xgb-churn-pred2-{datetime.now():%Y-%m-%d-%H-%M-%S}" image_uri = get_image_uri(boto3.Session().region_name, 'xgboost', '0.90-1') image_uri2 = get_image_uri(boto3.Session().region_name, 'xgboost', '0.90-2') sm_session.create_model( name=model_name, role=role, container_defs={ 'Image': image_uri, 'ModelDataUrl': model_url } ) sm_session.create_model( name=model_name2, role=role, container_defs={ 'Image': image_uri2, 'ModelDataUrl': model_url2 } )
Nous créons maintenant deux variantes de production, chacune ayant ses propres exigences en matière de modèle et de ressources (type d'instance et nombre d'instances). Cela vous permet également de tester des modèles sur différents types d'instance.
Nous avons défini l'élément initial_weight sur 1 pour les deux variantes. Cela signifie que 50 % des demandes vont à Variant1, et les 50 % restants à Variant2. La somme des pondérations des deux variantes est de 2 et chaque variante a une pondération affectée de 1. Cela signifie que chaque variante reçoit 1/2, soit 50 %, du trafic total.
from sagemaker.session import production_variant variant1 = production_variant( model_name=model_name, instance_type="ml.m5.xlarge", initial_instance_count=1, variant_name='Variant1', initial_weight=1, ) variant2 = production_variant( model_name=model_name2, instance_type="ml.m5.xlarge", initial_instance_count=1, variant_name='Variant2', initial_weight=1, )
Nous sommes enfin prêts à déployer ces variantes de production sur un terminal d' SageMaker intelligence artificielle.
endpoint_name = f"DEMO-xgb-churn-pred-{datetime.now():%Y-%m-%d-%H-%M-%S}" print(f"EndpointName={endpoint_name}") sm_session.endpoint_from_production_variants( name=endpoint_name, production_variants=[variant1, variant2] )
Étape 2 : Appeler les modèles déployés
Maintenant, nous envoyons des demandes à ce point de terminaison pour obtenir des inférences en temps réel. Nous utilisons à la fois la répartition du trafic et le ciblage direct.
Tout d'abord, nous utilisons la répartition du trafic que nous avons configurée à l'étape précédente. Chaque réponse d'inférence contient le nom de la variante de production qui traite la demande, cela nous permettant de voir que le trafic vers les deux variantes de production est à peu près égal.
# get a subset of test data for a quick test !tail -120 test_data/test-dataset-input-cols.csv > test_data/test_sample_tail_input_cols.csv print(f"Sending test traffic to the endpoint {endpoint_name}. \nPlease wait...") with open('test_data/test_sample_tail_input_cols.csv', 'r') as f: for row in f: print(".", end="", flush=True) payload = row.rstrip('\n') sm_runtime.invoke_endpoint( EndpointName=endpoint_name, ContentType="text/csv", Body=payload ) time.sleep(0.5) print("Done!")
SageMaker L'IA émet des métriques telles que Latency et Invocations pour chaque variante sur Amazon CloudWatch. Pour une liste complète des métriques émises par SageMaker l'IA, voirMétriques Amazon SageMaker AI sur Amazon CloudWatch. Faisons une requête CloudWatch pour obtenir le nombre d'appels par variante, afin de montrer comment les appels sont répartis par défaut entre les variantes :
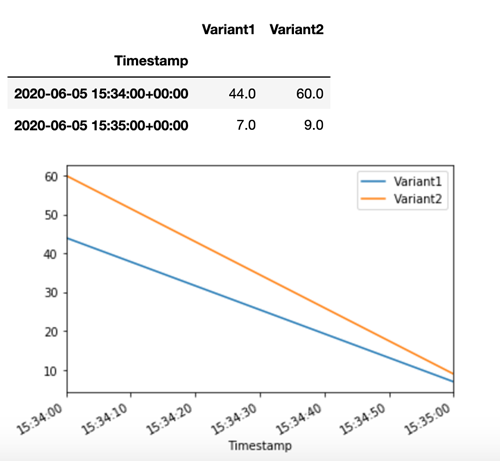
Appelons maintenant une version spécifique du modèle en spécifiant Variant1 comme TargetVariant dans l'appel à invoke_endpoint.
print(f"Sending test traffic to the endpoint {endpoint_name}. \nPlease wait...") with open('test_data/test_sample_tail_input_cols.csv', 'r') as f: for row in f: print(".", end="", flush=True) payload = row.rstrip('\n') sm_runtime.invoke_endpoint( EndpointName=endpoint_name, ContentType="text/csv", Body=payload, TargetVariant="Variant1" ) time.sleep(0.5)
Pour confirmer que toutes les nouvelles invocations ont été traitées parVariant1, nous pouvons demander le nombre CloudWatch d'invocations par variante. Nous voyons que pour les appels les plus récents (dernier horodatage), toutes les demandes ont été traitées par Variant1, comme nous l'avions spécifié. Aucune invocation n'a été faite pour Variant2.
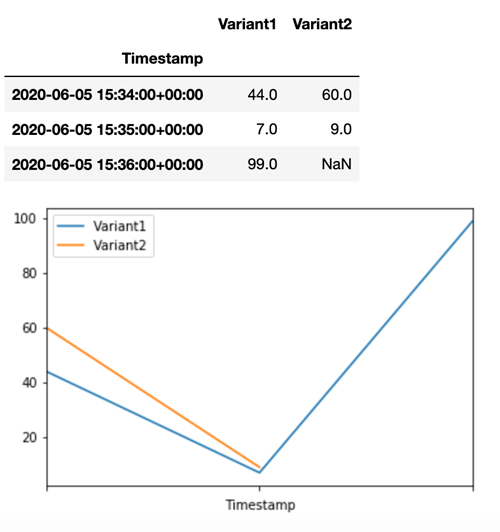
Étape 3 : Évaluer la performance du modèle
Pour voir quelle version du modèle fonctionne le mieux, évaluons l'exactitude, la précision, le rappel, le score F1 et le récepteur fonctionnant charactersistic/Area sous la courbe pour chaque variante. Tout d'abord, examinons ces métriques pour Variant1 :
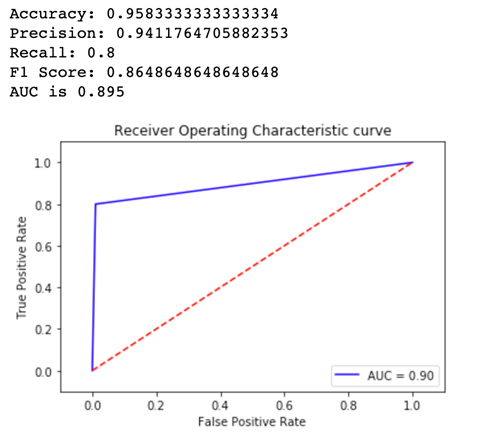
Regardons maintenant les métriques pour Variant2 :
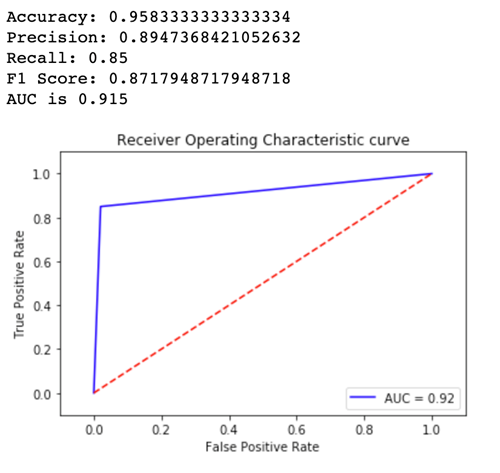
Pour la plupart de nos métriques définies, Variant2 fonctionne mieux, donc c'est la variante que nous voulons utiliser en production.
Étape 4 : Augmenter le trafic vers le meilleur modèle
Maintenant que nous avons déterminé que Variant2 fonctionnait mieux que Variant1, nous allons déplaçons plus de trafic vers elle. Nous pouvons continuer à l'utiliser TargetVariant pour invoquer une variante de modèle spécifique, mais une approche plus simple consiste à mettre à jour les poids attribués à chaque variante en appelant UpdateEndpointWeightsAndCapacities. Cela permet de modifier la répartition du trafic en direction de vos variantes de production sans nécessiter de mises à jour de votre point de terminaison. Dans la section de configuration, rappelons que nous avons défini des coefficients de pondération variables pour diviser le trafic 50/50. Les CloudWatch statistiques du nombre total d'appels pour chaque variante ci-dessous nous montrent les modèles d'invocation pour chaque variante :
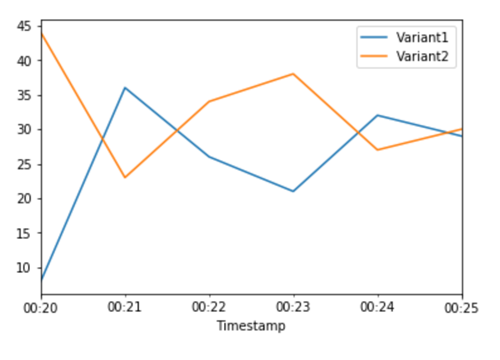
Nous transférons maintenant 75 % du trafic Variant2 en attribuant de nouvelles pondérations à chaque variante utilisée. UpdateEndpointWeightsAndCapacities SageMaker L'IA envoie désormais 75 % des demandes d'inférence à Variant2 et 25 % des demandes restantes àVariant1.
sm.update_endpoint_weights_and_capacities( EndpointName=endpoint_name, DesiredWeightsAndCapacities=[ { "DesiredWeight": 25, "VariantName": variant1["VariantName"] }, { "DesiredWeight": 75, "VariantName": variant2["VariantName"] } ] )
Les CloudWatch statistiques relatives au nombre total d'appels pour chaque variante nous indiquent que le nombre d'appels est plus élevé pour : Variant2 Variant1
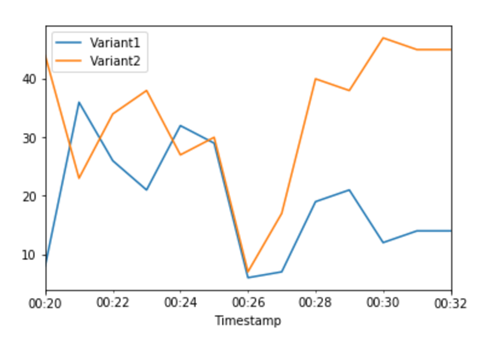
Nous pouvons continuer à surveiller nos métriques et, lorsque nous sommes satisfaits des performances d'une variante, nous pouvons acheminer 100 % du trafic vers cette dernière. Nous utilisons UpdateEndpointWeightsAndCapacities pour mettre à jour les affectations de trafic pour les variantes. Le poids pour Variant1 est défini sur 0 et le poids pour Variant2 est défini sur 1. SageMaker L'IA envoie désormais 100 % de toutes les demandes d'inférence àVariant2.
sm.update_endpoint_weights_and_capacities( EndpointName=endpoint_name, DesiredWeightsAndCapacities=[ { "DesiredWeight": 0, "VariantName": variant1["VariantName"] }, { "DesiredWeight": 1, "VariantName": variant2["VariantName"] } ] )
Les CloudWatch mesures relatives au nombre total d'appels pour chaque variante indiquent que toutes les demandes d'inférence sont traitées par Variant2 et qu'aucune demande d'inférence n'est traitée par. Variant1

Vous pouvez maintenant mettre à jour votre point de terminaison en toute sécurité et supprimer Variant1 de votre point de terminaison. Vous pouvez également continuer à tester de nouveaux modèles en production en ajoutant de nouvelles variantes à votre point de terminaison et en suivant les étapes 2 à 4.
