Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Cette section explique comment configurer rapidement un environnement de test complet dans Amazon SageMaker Studio. Vous allez créer un nouveau domaine Studio qui permettra aux utilisateurs de lancer de nouveaux clusters Amazon EMR directement depuis Studio. Les étapes fournissent un exemple de bloc-notes que vous pouvez connecter à un cluster Amazon EMR pour commencer à fonctionner Spark charges de travail. À l'aide de ce bloc-notes, vous allez créer un système de génération augmentée (RAG) à l'aide du traitement distribué Amazon EMR Spark et de la base de données vectorielle. OpenSearch
Note
Pour commencer, connectez-vous à la console de AWS gestion à l'aide d'un compte utilisateur AWS Identity and Access Management (IAM) doté d'autorisations d'administrateur. Pour plus d'informations sur la création d'un AWS compte et la création d'un utilisateur doté d'un accès administratif, consultezCompléter les prérequis SageMaker relatifs à Amazon AI.
Pour configurer votre environnement de test Studio et commencer à exécuter Spark emplois :
Étape 1 : créer un domaine SageMaker AI pour lancer des clusters Amazon EMR dans Studio
Dans les étapes suivantes, vous appliquez une AWS CloudFormation pile pour créer automatiquement un nouveau domaine d' SageMaker IA. La pile crée également un profil utilisateur et configure l'environnement et les autorisations nécessaires. Le domaine SageMaker AI est configuré pour vous permettre de lancer directement des clusters Amazon EMR depuis Studio. Dans cet exemple, les clusters Amazon EMR sont créés dans le même AWS
compte que SageMaker AI sans authentification. Vous pouvez trouver des AWS CloudFormation piles supplémentaires prenant en charge diverses méthodes d'authentification telles que Kerberos dans le référentiel getting_started.
Note
SageMaker L'IA autorise 5 domaines Studio par AWS compte et Région AWS par défaut. Assurez-vous que votre compte ne comporte pas plus de 4 domaines dans votre région avant de créer votre stack.
Suivez ces étapes pour configurer un domaine SageMaker AI afin de lancer des clusters Amazon EMR depuis Studio.
-
Téléchargez le fichier brut de ce AWS CloudFormation modèle
depuis le sagemaker-studio-emrGitHub référentiel. -
Accédez à la AWS CloudFormation console : https://console.aws.amazon.com/cloudformation
-
Choisissez Créer une pile, puis sélectionnez Avec de nouvelles ressources (standard) dans le menu déroulant.
-
À l'étape 1 :
-
Dans la section Préparer le modèle, sélectionnez Choisir un modèle existant.
-
Dans la section Spécifier un modèle, sélectionnez Charger un modèle de fichier.
-
Téléchargez le AWS CloudFormation modèle téléchargé et choisissez Next.
-
-
À l'étape 2, entrez un nom de pile SageMakerDomainName, puis choisissez Next.
-
À l'étape 3, conservez toutes les valeurs par défaut et choisissez Next.
-
À l'étape 4, cochez la case pour accuser réception de la création de ressources et choisissez Create stack. Cela crée un domaine Studio dans votre compte et dans votre région.
Étape 2 : Lancer un nouveau cluster Amazon EMR depuis l'interface utilisateur de Studio
Dans les étapes suivantes, vous allez créer un nouveau cluster Amazon EMR à partir de l'interface utilisateur de Studio.
-
Accédez à la console SageMaker AI https://console.aws.amazon.com/sagemaker/
et choisissez Domaines dans le menu de gauche. -
Cliquez sur votre nom de domaine Generative AIDomain pour ouvrir la page des détails du domaine.
-
Lancez Studio depuis le profil utilisateur
genai-user. -
Dans le volet de navigation de gauche, accédez à Data puis à Amazon EMR Clusters.
-
Sur la page des clusters Amazon EMR, choisissez Create. Sélectionnez le modèle SageMaker Studio Domain No Auth EMR créé par AWS CloudFormation la pile, puis choisissez Next.
-
Entrez un nom pour le nouveau cluster Amazon EMR. Mettez éventuellement à jour d'autres paramètres tels que le type d'instance des nœuds principaux et principaux, le délai d'inactivité ou le nombre de nœuds principaux.
-
Choisissez Create resource pour lancer le nouveau cluster Amazon EMR.
Après avoir créé le cluster Amazon EMR, suivez le statut sur la page Clusters EMR. Lorsque le statut passe à
Running/Waiting, votre cluster Amazon EMR est prêt à être utilisé dans Studio.
Étape 3 : Connecter un JupyterLab bloc-notes au cluster Amazon EMR
Dans les étapes suivantes, vous allez connecter un bloc-notes JupyterLab à votre cluster Amazon EMR en cours d'exécution. Dans cet exemple, vous importez un bloc-notes vous permettant de créer un système RAG (Retrieval Augmented Generation) à l'aide du traitement distribué Amazon EMR Spark et de la base de données vectorielle. OpenSearch
-
Lancement JupyterLab
Depuis Studio, lancez l' JupyterLab application.
-
Créez un espace privé
Si vous n'avez pas créé d'espace pour votre JupyterLab application, choisissez Créer un JupyterLab espace. Entrez un nom pour l'espace et conservez-le comme privé. Conservez les valeurs par défaut de tous les autres paramètres, puis choisissez Créer un espace.
Sinon, exécutez votre JupyterLab espace pour lancer une JupyterLab application.
-
Déployez votre LLM et vos modèles d'intégration à des fins d'inférence
-
Dans le menu supérieur, choisissez Fichier, Nouveau, puis Terminal.
-
Dans le terminal, exécutez la commande suivante.
wget --no-check-certificate https://raw.githubusercontent.com/aws-samples/sagemaker-studio-foundation-models/main/lab-00-setup/Lab_0_Warm_Up_Deploy_EmbeddingModel_Llama2_on_Nvidia.ipynb mkdir AWSGuides cd AWSGuides wget --no-check-certificate https://raw.githubusercontent.com/aws-samples/sagemaker-studio-foundation-models/main/lab-03-rag/AWSGuides/AmazonSageMakerDeveloperGuide.pdf wget --no-check-certificate https://raw.githubusercontent.com/aws-samples/sagemaker-studio-foundation-models/main/lab-03-rag/AWSGuides/EC2DeveloperGuide.pdf wget --no-check-certificate https://raw.githubusercontent.com/aws-samples/sagemaker-studio-foundation-models/main/lab-03-rag/AWSGuides/S3DeveloperGuide.pdfCela permet de récupérer le
Lab_0_Warm_Up_Deploy_EmbeddingModel_Llama2_on_Nvidia.ipynbbloc-notes dans votre répertoire local et de télécharger trois fichiers PDF dans unAWSGuidesdossier local. -
Ouvrez
lab-00-setup/Lab_0_Warm_Up_Deploy_EmbeddingModel_Llama2_on_Nvidia.ipynb, conservez lePython 3 (ipykernel)noyau et exécutez chaque cellule.Avertissement
Dans la section Contrat de licence Llama 2, assurez-vous d'accepter le CLUF Llama2 avant de continuer.
Le bloc-notes déploie deux modèles
all-MiniLM-L6-v2 Models,Llama 2et c'est partiml.g5.2xlargepour l'inférence.Le déploiement des modèles et la création des points de terminaison peuvent prendre un certain temps.
-
-
Ouvrez votre bloc-notes principal
Dans JupyterLab, ouvrez votre terminal et exécutez la commande suivante.
cd .. wget --no-check-certificate https://raw.githubusercontent.com/aws-samples/sagemaker-studio-foundation-models/main/lab-03-rag/Lab_3_RAG_on_SageMaker_Studio_using_EMR.ipynbVous devriez voir le
Lab_3_RAG_on_SageMaker_Studio_using_EMR.ipynbbloc-notes supplémentaire dans le panneau de gauche de JupyterLab. -
Choisissez un
PySparknoyauOuvrez votre
Lab_3_RAG_on_SageMaker_Studio_using_EMR.ipynbbloc-notes et assurez-vous que vous utilisez leSparkMagic PySparknoyau. Vous pouvez changer de noyau en haut à droite de votre bloc-notes. Choisissez le nom actuel du noyau pour ouvrir un modal de sélection du noyau, puis choisissezSparkMagic PySpark. -
Connectez votre ordinateur portable au cluster
-
En haut à droite de votre bloc-notes, choisissez Cluster. Cette action ouvre une fenêtre modale répertoriant tous les clusters en cours d'exécution auxquels vous êtes autorisé à accéder.
-
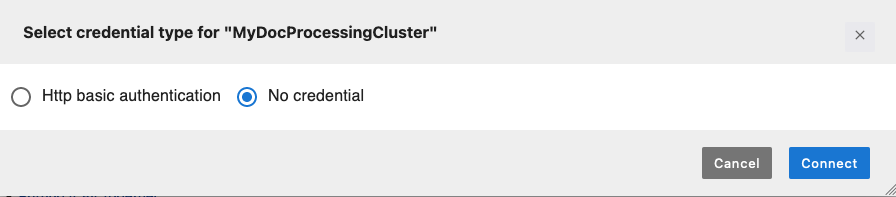
Sélectionnez votre cluster, puis sélectionnez Connect. Une nouvelle fenêtre modale de sélection du type d'identifiant s'ouvre.
-
Choisissez Aucune information d'identification, puis Connect.
-
Une cellule de bloc-notes se remplit et s'exécute automatiquement. La cellule du bloc-notes charge l'
sagemaker_studio_analytics_extension.magicsextension, qui fournit des fonctionnalités permettant de se connecter au cluster Amazon EMR. Il utilise ensuite la commande%sm_analyticsmagique pour établir la connexion à votre cluster Amazon EMR et à l'application Spark.Note
Assurez-vous que le type d'authentification de la chaîne de connexion à votre cluster Amazon EMR est défini sur.
NoneCeci est illustré par la valeur--auth-type Nonede l'exemple suivant. Vous pouvez modifier le champ si nécessaire.%load_ext sagemaker_studio_analytics_extension.magics %sm_analytics emr connect --verify-certificate False --cluster-idyour-cluster-id--auth-typeNone--language python -
Une fois que vous avez établi la connexion avec succès, le message de sortie de votre cellule de connexion doit afficher vos
SparkSessioninformations, notamment votre identifiant de cluster,YARNl'identifiant d'application et un lien vers le Spark Interface utilisateur pour surveiller votre Spark emplois.
-
Vous êtes prêt à utiliser le Lab_3_RAG_on_SageMaker_Studio_using_EMR.ipynb bloc-notes. Cet exemple de bloc-notes exécute des PySpark charges de travail distribuées pour créer un système RAG à l'aide LangChain de et. OpenSearch
Étape 4 : Nettoyez votre AWS CloudFormation pile
Une fois que vous avez terminé, assurez-vous de résilier vos deux terminaux et de supprimer votre AWS CloudFormation pile pour éviter des frais continus. La suppression de la pile nettoie toutes les ressources mises en service par la pile.
Pour supprimer votre AWS CloudFormation pile lorsque vous en avez terminé
-
Accédez à la AWS CloudFormation console : https://console.aws.amazon.com/cloudformation
-
Sélectionnez la pile que vous souhaitez supprimer. Vous pouvez le rechercher par son nom ou le trouver dans la liste des piles.
-
Cliquez sur le bouton Supprimer pour finaliser la suppression de la pile, puis sur Supprimer à nouveau pour confirmer que toutes les ressources créées par la pile seront supprimées.
Attendez que la suppression de la pile soit terminée. Cela peut prendre quelques minutes. AWS CloudFormation nettoie automatiquement toutes les ressources définies dans le modèle de pile.
-
Vérifiez que toutes les ressources créées par la pile ont été supprimées. Par exemple, vérifiez s'il n'y a pas de cluster Amazon EMR restant.
Pour supprimer les points de terminaison d'API d'un modèle
-
Accédez à la console SageMaker AI : https://console.aws.amazon.com/sagemaker/
. -
Dans le volet de navigation de gauche, choisissez Inference, puis Endpoints.
-
Sélectionnez le point de terminaison,
hf-allminil6v2-embedding-eppuis choisissez Supprimer dans la liste déroulante Actions. Répétez l'étape pour le point de terminaisonmeta-llama2-7b-chat-tg-ep.
