Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Préparez les données ML avec Amazon SageMaker Data Wrangler
Important
Amazon SageMaker Data Wrangler a été intégré à Amazon SageMaker Canvas. Dans la nouvelle expérience Data Wrangler de SageMaker Canvas, vous pouvez utiliser une interface en langage naturel pour explorer et transformer vos données en plus de l'interface visuelle. Pour plus d'informations sur Data Wrangler dans SageMaker Canvas, consultez. Préparation des données
Amazon SageMaker Data Wrangler (Data Wrangler) est une fonctionnalité d'Amazon SageMaker Studio Classic qui fournit une solution de bout en bout pour importer, préparer, transformer, présenter et analyser des données. Vous pouvez intégrer un flux de préparation de données Data Wrangler dans vos flux de travail de machine learning (ML) afin de simplifier et de rationaliser le prétraitement des données et l’ingénierie des caractéristiques en utilisant peu ou pas de codage. Vous pouvez également ajouter vos propres scripts et transformations Python pour personnaliser les flux de travail.
Data Wrangler fournit les principales fonctionnalités suivantes pour vous aider à analyser et à préparer les données pour les applications de machine learning.
-
Importation — Connectez-vous et importez des données depuis Amazon Simple Storage Service (Amazon S3), Amazon Athena (Athena), Amazon Redshift, Snowflake et Databricks.
-
Flux de données : créez un flux de données permettant de définir une série d’étapes de préparation des données ML. Vous pouvez utiliser un flux pour combiner des jeux de données provenant de différentes sources de données, identifier le nombre et les types de transformations que vous souhaitez appliquer aux jeux de données, et définir un flux de préparation des données qui peut être intégré à un pipeline ML.
-
Transformation : nettoyez et transformez votre jeu de données à l’aide de transformations standard, telles que les outils de formatage de chaînes, de vecteurs et de données numériques. Mettez en valeur vos données à l'aide de transformations telles que le texte, date/time l'intégration et le codage catégoriel.
-
Generate Data Insights (Générer une analyse de données) : vérifiez automatiquement la qualité des données et détectez des anomalies dans vos données grâce à Data Wrangler Data Insights and Quality Report.
-
Analyser : analysez les caractéristiques de votre jeu de données à n’importe quel moment de votre flux. Data Wrangler dispose d’outils intégrés de visualisation des données, tels que des diagrammes de dispersion et des histogrammes, ainsi que d’outils d’analyse des données, tels que l’analyse des fuites de caractéristique cible et la modélisation rapide pour comprendre la corrélation des caractéristiques.
-
Export (Exporter) : exportez votre flux de travail de préparation des données vers un autre emplacement. Voici des exemples d'emplacements :
-
Compartiment Amazon Simple Storage Service (Amazon S3)
-
Amazon SageMaker Pipelines — Utilisez des pipelines pour automatiser le déploiement des modèles. Vous pouvez exporter les données que vous avez transformées directement vers les pipelines.
-
Amazon SageMaker Feature Store : stockez les fonctionnalités et leurs données dans un magasin centralisé.
-
Script Python : stockez les données et leurs transformations dans un script Python pour vos flux de travail personnalisés.
-
Pour commencer à utiliser Data Wrangler, consultez Démarrer avec Data Wrangler.
Important
Data Wrangler ne prend plus en charge Jupyter Lab Version 1 (JL1). Pour accéder aux dernières fonctionnalités et mises à jour, effectuez la mise à jour vers la version 3 de Jupyter Lab. Pour plus d’informations sur la mise à niveau, consultez Afficher et mettre à jour la JupyterLab version d'une application depuis la console.
Important
Les informations et les procédures de ce guide utilisent la dernière version d'Amazon SageMaker Studio Classic. Pour en savoir plus sur la mise à jour de Studio Classic vers la version la plus récente, consultez Présentation de l'interface utilisateur Amazon SageMaker Studio Classic.
Vous devez utiliser la version 1.3.0 ou ultérieure de Studio Classic. Suivez la procédure ci-dessous pour ouvrir Amazon SageMaker Studio Classic et voir quelle version vous utilisez.
Pour ouvrir Studio Classic et vérifier sa version, consultez la procédure suivante.
-
Suivez les étapes ci-dessous Conditions préalables pour accéder à Data Wrangler via Amazon SageMaker Studio Classic.
-
En regard de l’utilisateur que vous souhaitez utiliser pour lancer Studio Classic, sélectionnez Lancer l’application.
-
Choisissez Studio.
-
Après le chargement de Studio Classic, sélectionnez Fichier, puis Nouveau et Terminal.
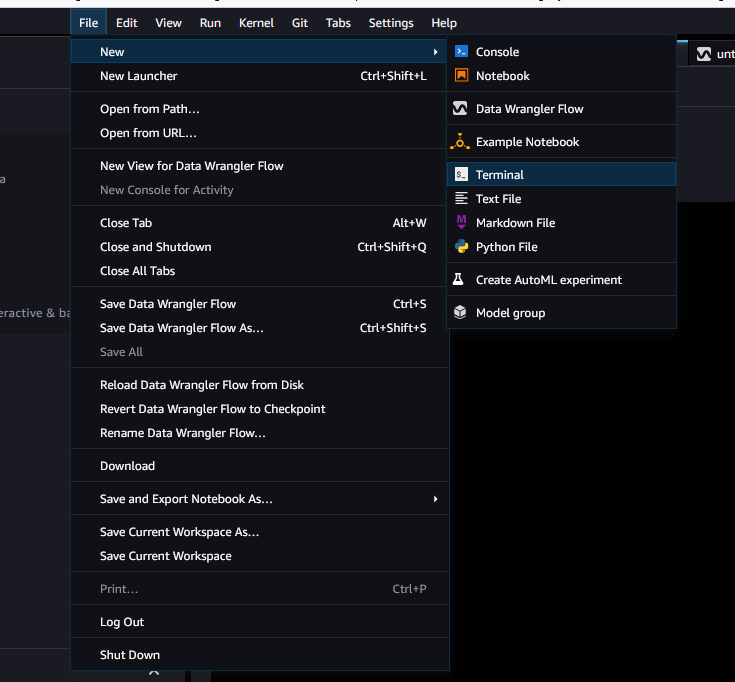
-
Une fois que vous avez lancé Studio Classic, sélectionnez Fichier, puis Nouveau et enfin Terminal.
-
Saisissez
cat /opt/conda/share/jupyter/lab/staging/yarn.lock | grep -A 1 "@amzn/sagemaker-ui-data-prep-plugin@"pour afficher la version de votre instance Studio Classic. Vous devez disposer de Studio Classic version 1.3.0 pour utiliser Snowflake.
Vous pouvez mettre à jour Amazon SageMaker Studio Classic depuis le Console de gestion AWS. Pour plus d’informations sur la mise à jour de Studio Classic, consultez Présentation de l'interface utilisateur Amazon SageMaker Studio Classic.
Rubriques
