Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Entraînement d’un modèle
La phase d'entraînement du cycle de vie complet du machine learning (ML) va de l'accès à votre jeu de données d'entraînement à la génération d'un modèle final et à la sélection du modèle le plus performant pour le déploiement. Les sections suivantes fournissent un aperçu des fonctionnalités et des ressources de SageMaker formation disponibles, ainsi que des informations techniques détaillées pour chacune d'entre elles.
L'architecture de base de la SageMaker formation
Si vous utilisez l' SageMaker IA pour la première fois et que vous souhaitez trouver une solution de machine learning rapide pour entraîner un modèle sur votre jeu de données, envisagez d'utiliser une solution sans code ou low-code telle que SageMaker Canvas, JumpStartdans SageMaker Studio Classic, ou SageMaker Autopilot.
Pour les expériences de codage intermédiaires, pensez à utiliser un bloc-notes SageMaker Studio Classic ou des instances de SageMaker bloc-notes. Pour commencer, suivez les instructions du guide Entraînement d’un modèle de démarrage de l' SageMaker IA. Nous recommandons cette option pour les cas d'utilisation dans lesquels vous créez votre propre modèle et script d'entraînement à l'aide d'un framework de machine learning.
La conteneurisation des charges de travail de machine learning et la capacité de gérer les ressources informatiques sont au cœur des métiers de l' SageMaker IA. La plateforme de SageMaker formation prend en charge le gros du travail associé à la mise en place et à la gestion de l'infrastructure pour les charges de travail de formation au ML. Avec SageMaker Training, vous pouvez vous concentrer sur le développement, la formation et la mise au point de votre modèle.
Le schéma d'architecture suivant montre comment l' SageMaker IA gère les tâches de formation ML et approvisionne les instances Amazon EC2 pour le compte des utilisateurs de l' SageMaker IA. En tant qu'utilisateur d' SageMaker IA, vous pouvez apporter votre propre ensemble de données de formation et l'enregistrer sur Amazon S3. Vous pouvez choisir un modèle d'apprentissage automatique parmi les algorithmes intégrés d' SageMaker IA disponibles, ou apporter votre propre script d'entraînement avec un modèle conçu à l'aide de frameworks d'apprentissage automatique populaires.
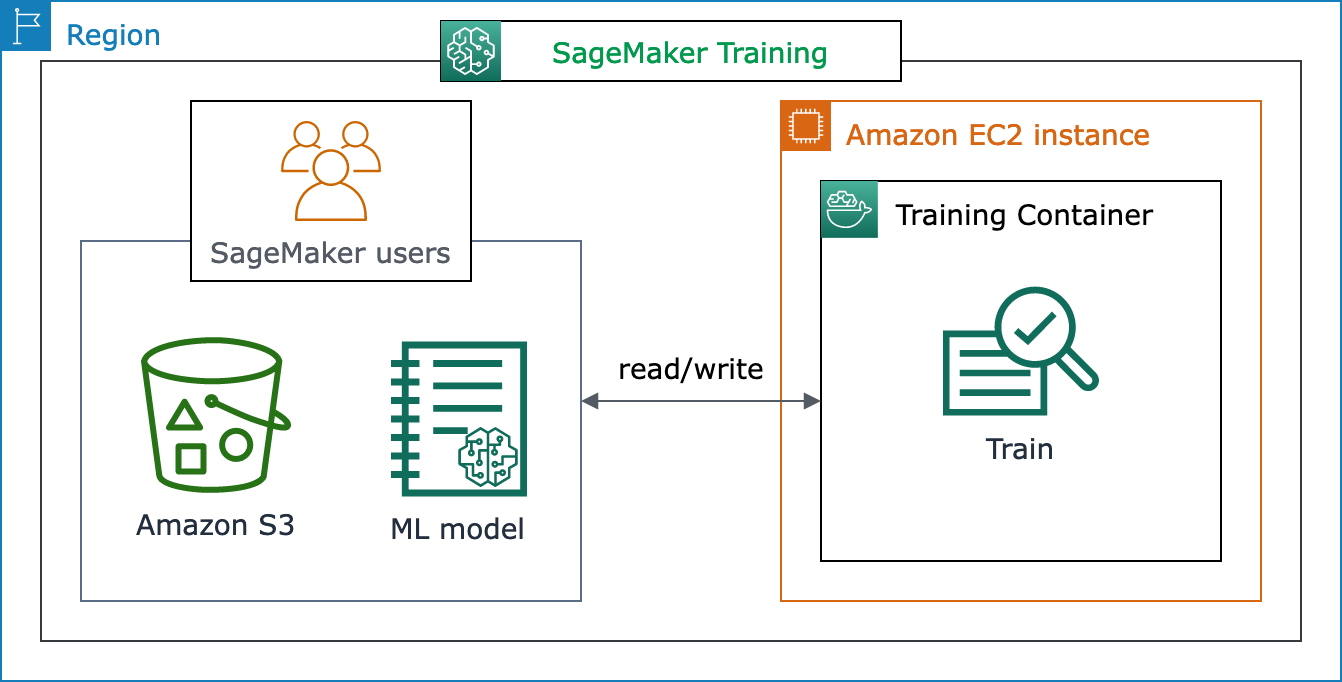
Vue complète du flux de travail et des fonctionnalités de SageMaker formation
Le parcours complet de l'entraînement de machine learning implique des tâches allant au-delà de l'ingestion de données vers des modèles de machine learning, de l'entraînement de modèles sur des instances de calcul et de l'obtention d'artefacts et de sorties de modèles. Vous devez évaluer chaque étape avant, pendant et après l'entraînement pour vous assurer que votre modèle est correctement entraîné pour atteindre la précision cible correspondant à vos objectifs.
L'organigramme suivant présente un aperçu général de vos actions (dans des cases bleues) et des fonctionnalités de SageMaker formation disponibles (dans des cases bleu clair) tout au long de la phase de formation du cycle de vie du machine learning.
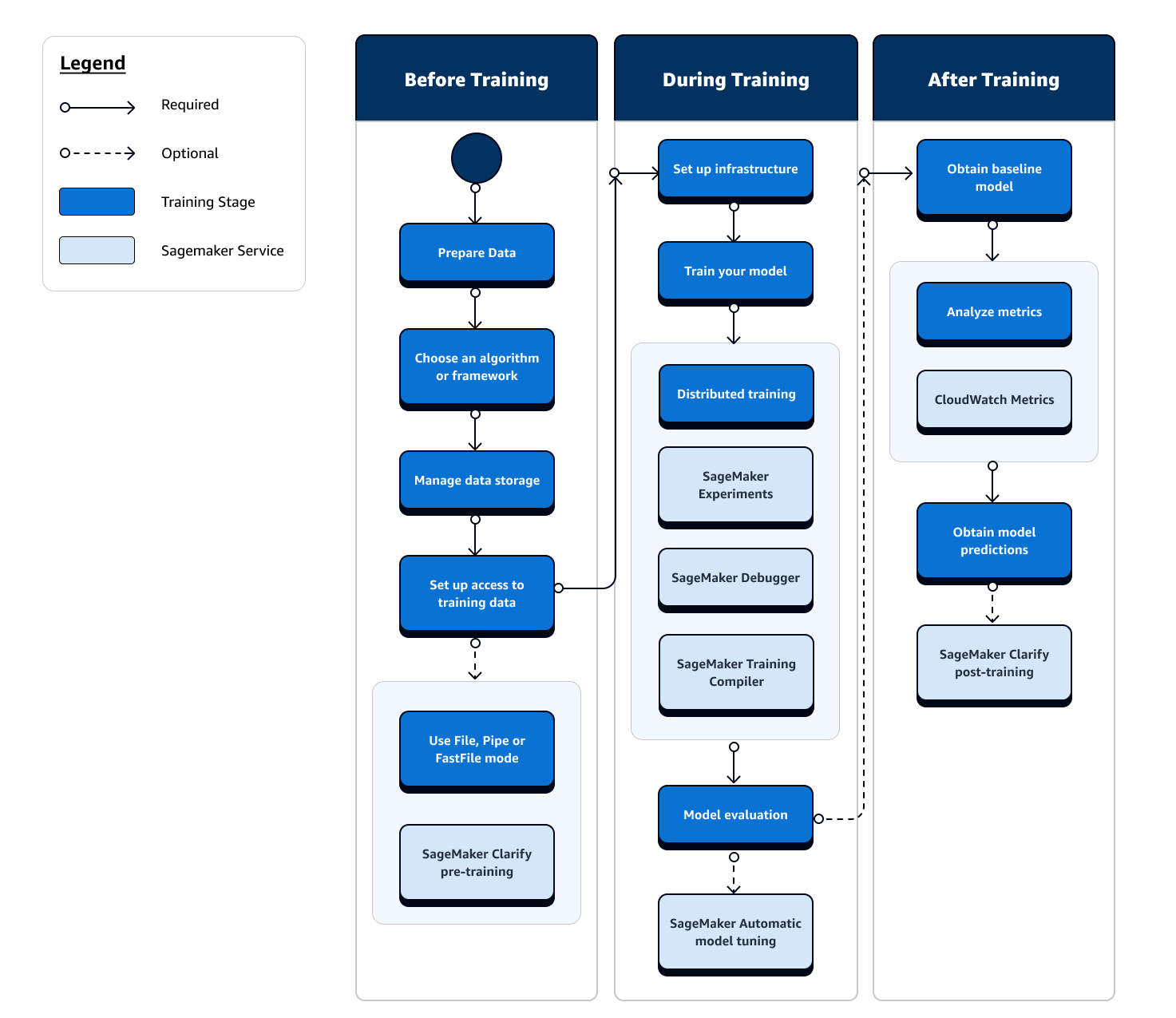
Les sections suivantes vous présentent chaque phase de formation décrite dans l'organigramme précédent et les fonctionnalités utiles offertes par l' SageMaker IA au cours des trois sous-étapes de la formation ML.
Avant l'entraînement
Il existe un certain nombre de scénarios de configuration des ressources de données et de l'accès aux données à prendre en compte avant l'entraînement. Reportez-vous au diagramme suivant et aux détails de chaque phase avant l'entraînement pour avoir une idée des décisions que vous devez prendre.
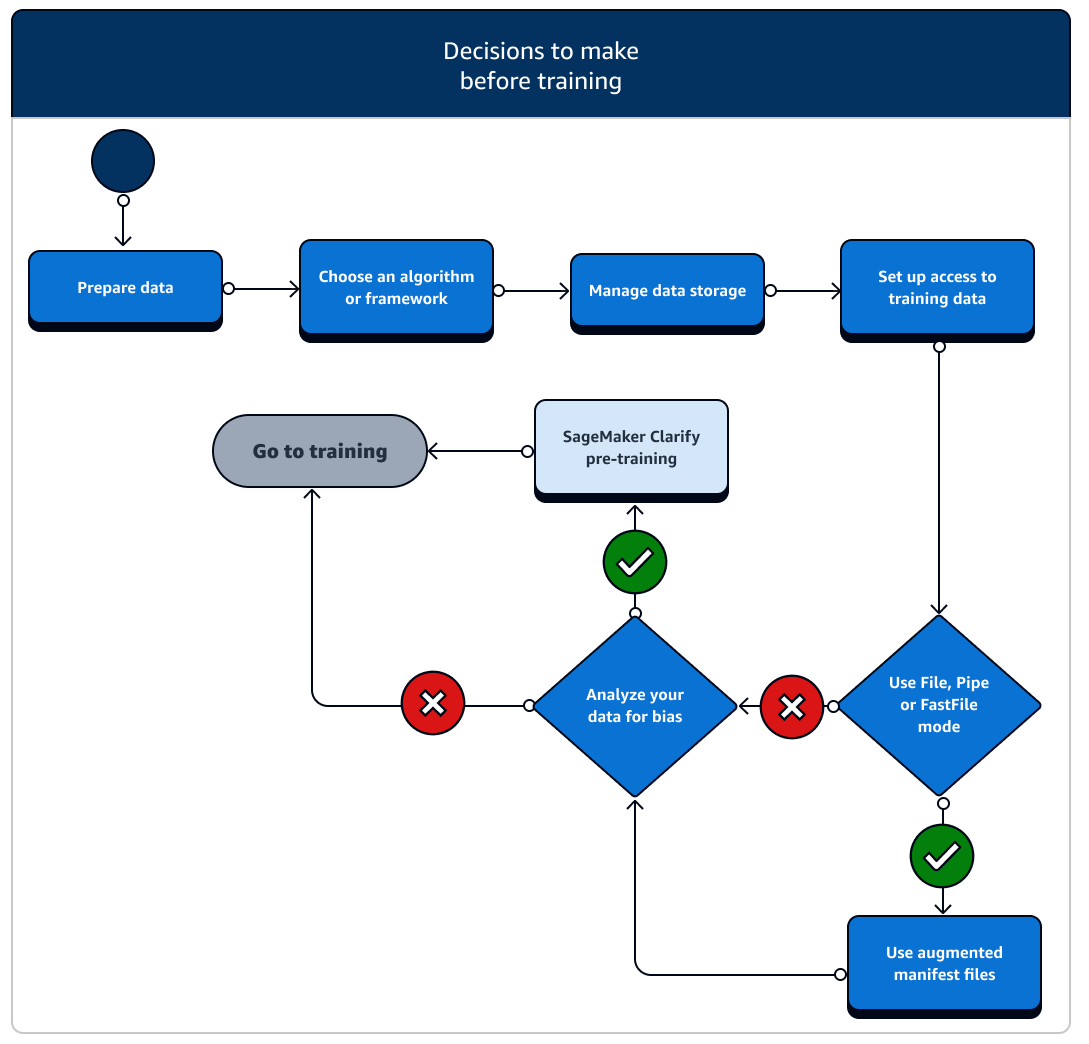
-
Préparation des données : avant la formation, vous devez avoir terminé le nettoyage des données et l'ingénierie des fonctionnalités pendant la phase de préparation des données. SageMaker L'IA dispose de plusieurs outils d'étiquetage et d'ingénierie des fonctionnalités pour vous aider. Consultez Étiquetage des données, Préparation et analyse des jeux de données, Traitement des données et Création, stockage et partage des fonctionnalités pour plus d'informations.
-
Choix d'un algorithme ou d'un framework : selon le niveau de personnalisation dont vous avez besoin, il existe différentes options pour les algorithmes et les frameworks.
-
Si vous préférez une implémentation low-code d'un algorithme prédéfini, utilisez l'un des algorithmes intégrés proposés par SageMaker l'IA. Pour plus d'informations, consultez Choix d'un algorithme.
-
Si vous avez besoin de plus de flexibilité pour personnaliser votre modèle, exécutez votre script d'entraînement à l'aide de vos frameworks et boîtes à outils préférés au sein de l' SageMaker IA. Pour plus d'informations, consultez Frameworks et boîtes à outils de machine learning.
-
Pour étendre les images SageMaker AI Docker prédéfinies en tant qu'image de base de votre propre conteneur, voir Utiliser des images Pre-built SageMaker AI Docker.
-
Pour intégrer votre conteneur Docker personnalisé à l' SageMaker IA, consultez Adapter votre propre conteneur Docker pour qu'il fonctionne avec SageMaker l'IA. Vous devez installer sagemaker-training-toolkit
sur votre conteneur.
-
-
Gestion du stockage des données : comprenez le mappage entre le stockage de données (tel qu'Amazon S3, Amazon EFS ou Amazon FSx) et le conteneur de formation qui s'exécute dans l'instance de calcul Amazon EC2. SageMaker L'IA permet de cartographier les chemins de stockage et les chemins locaux dans le conteneur de formation. Vous pouvez également les spécifier manuellement. Une fois le mappage terminé, envisagez d'utiliser l'un des modes de transmission de données : File, Pipe et FastFile mode. Pour savoir comment l' SageMaker IA cartographie les chemins de stockage, consultez la section Dossiers de stockage d'entraînement.
-
Configurez l'accès aux données de formation : utilisez un domaine Amazon SageMaker AI, un profil d'utilisateur de domaine, IAM, Amazon VPC, AWS KMS et pour répondre aux exigences des organisations les plus sensibles en matière de sécurité.
-
Pour l'administration du compte, consultez le domaine Amazon SageMaker AI.
-
Pour une référence complète sur les politiques IAM et la sécurité, consultez la section Sécurité dans Amazon SageMaker AI.
-
-
Diffusez vos données d'entrée : SageMaker AI propose trois modes de saisie de données, File, Pipe et FastFile. Le mode de saisie par défaut est le mode File, qui charge l'intégralité du jeu de données lors de l'initialisation de la tâche d'entraînement. Pour en savoir plus sur les bonnes pratiques générales en matière de diffusion de données depuis votre stockage de données vers le conteneur d'entraînement, consultez Accès aux données d'entraînement.
Dans le cas du mode Pipe, vous pouvez également envisager d'utiliser un fichier manifeste augmenté afin de diffuser vos données directement depuis Amazon Simple Storage Service (Amazon S3) afin d'entraîner votre modèle. L'utilisation du mode Pipe réduit l'espace disque, car Amazon Elastic Block Store doit uniquement stocker les artefacts de votre modèle final, plutôt que de stocker le jeu de données d'entraînement complet. Pour plus d'informations, consultez Fourniture de métadonnées de jeu de données à des tâches d'entraînement avec un fichier manifeste augmenté.
-
Analysez vos données pour détecter les biais : avant l'entraînement, vous pouvez analyser votre jeu de données et votre modèle pour détecter tout biais par rapport à un groupe défavorisé afin de vérifier que votre modèle apprend un ensemble de données non biaisé à l'aide SageMaker de Clarify.
-
Choisissez le SageMaker SDK à utiliser : il existe deux manières de lancer une tâche de formation en SageMaker IA : en utilisant le SDK Python SageMaker AI de haut niveau ou en utilisant les SageMaker API de bas niveau pour le SDK for Python (Boto3) ou le. AWS CLI Le SDK SageMaker Python extrait l' SageMaker API de bas niveau pour fournir des outils pratiques. Comme indiqué ci-dessusL'architecture de base de la SageMaker formation, vous pouvez également utiliser des options sans code ou à code minimal à l'aide de SageMaker Canvas, de SageMaker Studio Classic ou JumpStart SageMaker d'AI Autopilot.
Pendant l'entraînement
Pendant l'entraînement, vous devez continuellement améliorer la stabilité, la vitesse et l'efficacité de l'entraînement tout en mettant à l'échelle les ressources informatiques, l'optimisation des coûts et, surtout, les performances des modèles. Lisez la suite pour plus d'informations sur les étapes de formation et les fonctionnalités de SageMaker formation pertinentes.
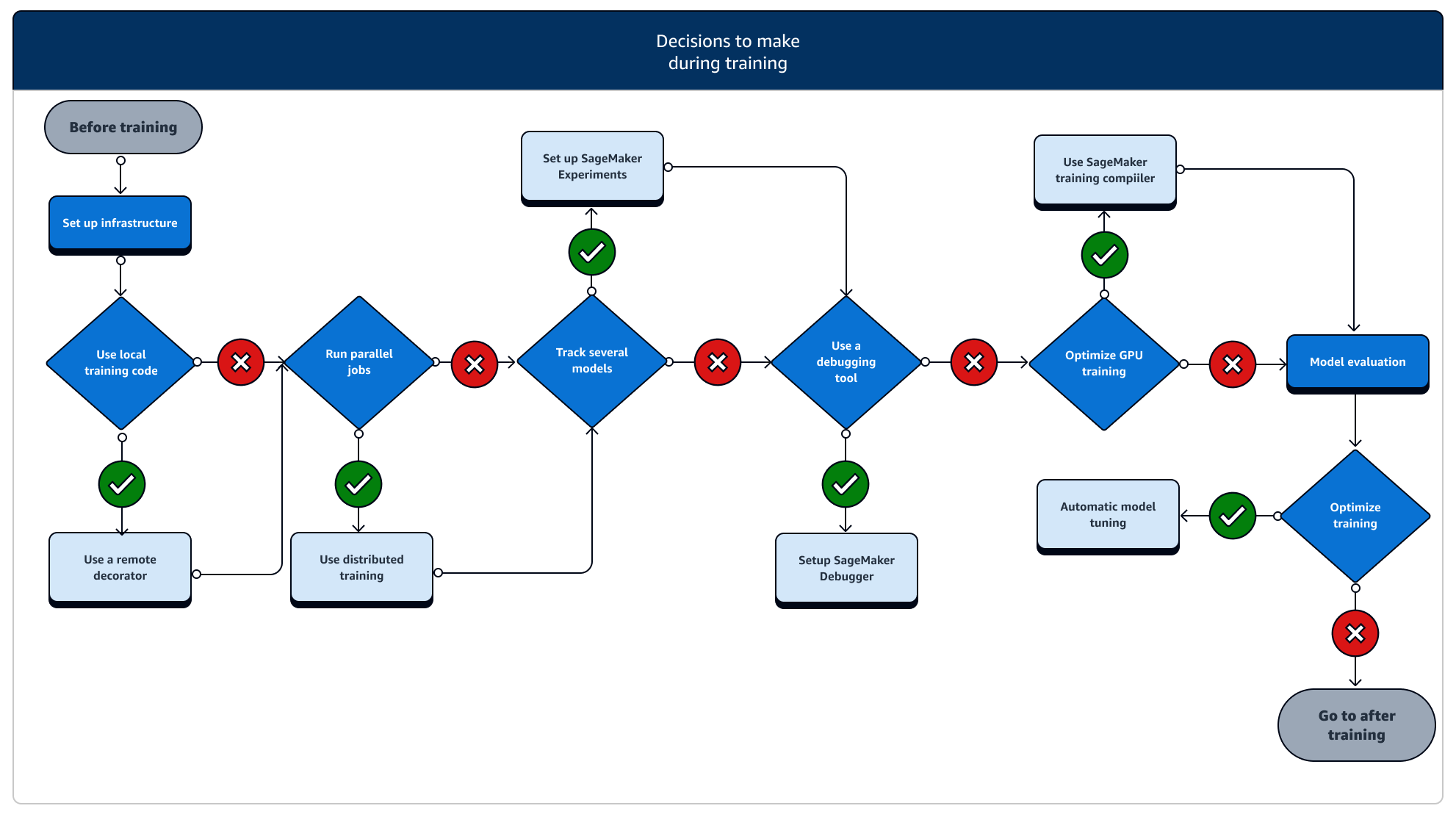
-
Configuration de l'infrastructure : choisissez le type d'instance et les outils de gestion d'infrastructure adaptés à votre cas d'utilisation. Vous pouvez démarrer à partir d'une petite instance et l'augmenter en fonction de votre charge de travail. Pour entraîner un modèle sur un jeu de données tabulaire, commencez par la plus petite instance de CPU des familles d'instances C4 ou C5. Pour entraîner un modèle de grande taille pour la vision par ordinateur ou le traitement du langage naturel, commencez par la plus petite instance de GPU des familles d'instances P2, P3, G4dn ou G5. Vous pouvez également mélanger différents types d'instances dans un cluster ou conserver des instances dans des pools chauds à l'aide des outils de gestion d'instances suivants proposés par SageMaker AI. Vous pouvez également utiliser le cache permanent pour réduire la latence et le temps facturable des tâches d'entraînement itératives par rapport à la réduction de latence due uniquement aux groupes d'instances pré-initialisées. Pour en savoir plus, consultez les rubriques suivantes.
Vous devez disposer d'un quota suffisant pour exécuter une tâche d'entraînement. Si vous exécutez votre tâche d'entraînement sur une instance dont le quota est insuffisant, vous recevrez un message d'erreur
ResourceLimitExceeded. Pour vérifier les quotas actuellement disponibles sur votre compte, utilisez votre console Service Quotas. Pour découvrir comment demander une augmentation de quota, consultez Régions et quotas pris en charge. En outre, pour trouver des informations sur les prix et les types d'instances disponibles en fonction de la Régions AWS, consultez les tableaux sur la page de SageMaker tarification d'Amazon . -
Exécuter une tâche de formation à partir d'un code local : vous pouvez annoter votre code local à l'aide d'un décorateur à distance pour exécuter votre code en tant que tâche de SageMaker formation depuis Amazon SageMaker Studio Classic, un SageMaker bloc-notes Amazon ou depuis votre environnement de développement intégré local. Pour de plus amples informations, veuillez consulter Exécutez votre code local en tant que tâche SageMaker de formation.
-
Suivez les tâches de formation : surveillez et suivez vos tâches de formation à l'aide d' SageMaker Experiments, SageMaker Debugger ou Amazon. CloudWatch Vous pouvez observer les performances du modèle en termes de précision et de convergence, et effectuer une analyse comparative des métriques entre plusieurs tâches de formation à l'aide d'expériences d' SageMaker IA. Vous pouvez suivre le taux d'utilisation des ressources de calcul en utilisant les outils de profilage de SageMaker Debugger ou Amazon. CloudWatch Pour en savoir plus, consultez les rubriques suivantes.
En outre, pour les tâches de deep learning, utilisez les outils de débogage des modèles Amazon SageMaker Debugger et les règles intégrées pour identifier les problèmes plus complexes liés aux processus de convergence des modèles et de mise à jour du poids.
-
Entraînement distribué : si votre tâche d'entraînement entre dans une phase stable sans interruption en raison d'une mauvaise configuration de l'infrastructure d'entraînement ou de problèmes de mémoire insuffisante, vous souhaiterez peut-être trouver d'autres options pour mettre à l'échelle votre tâche et l'exécuter sur une période prolongée pendant des jours, voire des mois. Lorsque vous serez prêt à passer à l'échelle supérieure, pensez à la formation distribuée. SageMaker L'IA propose diverses options de calcul distribué, qu'il s'agisse de charges de travail ML légères ou de lourdes charges de travail de deep learning.
Pour les tâches d'apprentissage profond qui impliquent l'entraînement de très grands modèles sur de très grands ensembles de données, envisagez d'utiliser l'une des stratégies de formation distribuée basées sur l'SageMaker IA pour étendre et atteindre le parallélisme des données, le parallélisme des modèles ou une combinaison des deux. Vous pouvez également utiliser SageMaker Training Compiler pour compiler et optimiser les graphiques du modèle sur les instances de GPU. Ces fonctionnalités d' SageMaker IA prennent en charge les frameworks d'apprentissage en profondeur tels que PyTorch TensorFlow, et Hugging Face Transformers.
-
Réglage des hyperparamètres du modèle : ajustez les hyperparamètres de votre modèle à l'aide du réglage automatique du modèle avec SageMaker l'IA. SageMaker L'IA fournit des méthodes de réglage des hyperparamètres telles que la recherche par grille et la recherche bayésienne, en lançant des tâches de réglage d'hyperparamètres parallèles avec une fonctionnalité d'arrêt anticipé pour les tâches de réglage d'hyperparamètres non améliorantes.
-
Point de contrôle et réduction des coûts grâce aux instances Spot : si la durée d'entraînement n'est pas une préoccupation majeure, vous pouvez envisager d'optimiser les coûts d'entraînement des modèles avec des instances Spot gérées. Notez que vous devez activer le point de contrôle pour l'entraînement Spot afin de poursuivre le rétablissement après des interruptions de tâches intermittentes dues au remplacement d'instances Spot. Vous pouvez également utiliser la fonctionnalité de point de contrôle pour sauvegarder vos modèles en cas de résiliation imprévue d'une tâche d'entraînement. Pour en savoir plus, consultez les rubriques suivantes.
Après l'entraînement
Après l'entraînement, vous obtenez un artefact de modèle final à utiliser pour le déploiement et l'inférence du modèle. Des actions supplémentaires sont impliquées dans la phase de post-entraînement, comme le montre le diagramme suivant.
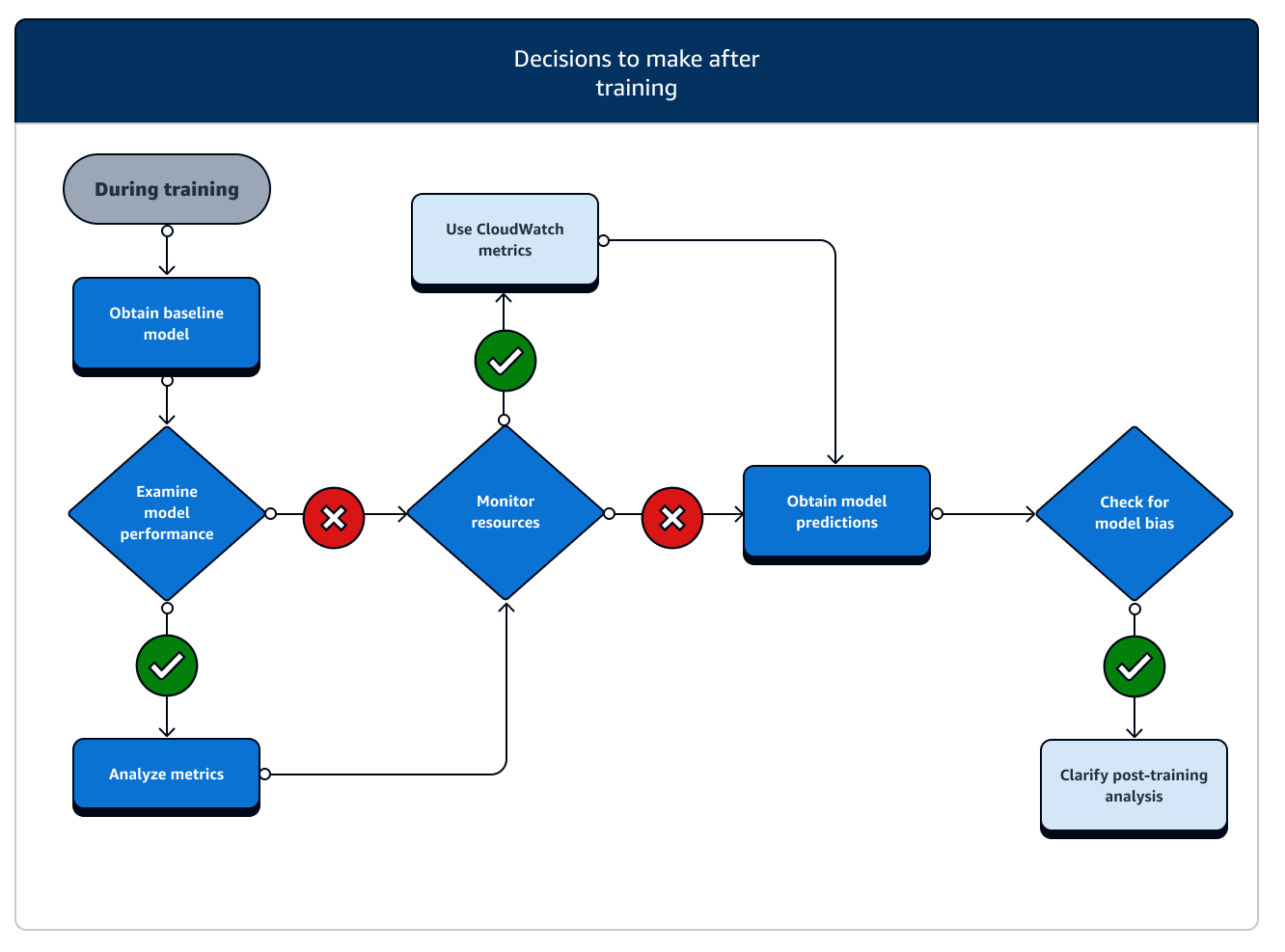
-
Obtention du modèle de référence : une fois que vous avez l'artefact du modèle, vous pouvez le définir comme modèle de référence. Pensez aux actions suivantes après la formation et à l'utilisation des fonctionnalités d' SageMaker IA avant de passer au déploiement du modèle en production.
-
Examinez les performances du modèle et vérifiez l'absence de biais : utilisez Amazon CloudWatch Metrics et SageMaker Clarify pour détecter les biais après l'entraînement afin de détecter tout biais dans les données entrantes et modélisez au fil du temps par rapport à la base de référence. Vous devez évaluer vos nouvelles données et prédictions de modèle par rapport aux nouvelles données régulièrement ou en temps réel. Grâce à ces fonctionnalités, vous pouvez recevoir des alertes en cas de modifications ou d'anomalies graves, ainsi que de modifications ou de dérives graduelles des données et du modèle.
-
Vous pouvez également utiliser la fonctionnalité d'entraînement incrémental de l' SageMaker IA pour charger et mettre à jour votre modèle (ou le peaufiner) avec un ensemble de données étendu.
-
Vous pouvez enregistrer la formation des modèles en tant qu'étape de votre pipeline d'SageMaker IA ou dans le cadre d'autres fonctionnalités de flux de travail proposées par l' SageMaker IA afin d'orchestrer le cycle de vie complet du machine learning.
