Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Évaluation du modèle
Maintenant que vous avez formé et déployé un modèle à l'aide d'Amazon SageMaker AI, évaluez-le pour vous assurer qu'il génère des prévisions précises sur les nouvelles données. Pour l’évaluation du modèle, utilisez le jeu de données de test que vous avez créé dans Préparation d’un jeu de données.
Évaluer le modèle déployé pour les services d'hébergement SageMaker AI
Pour évaluer le modèle et l’utiliser en production, invoquez le point de terminaison avec le jeu de données de test et vérifiez si les inférences que vous obtenez donnent une précision cible que vous souhaitez atteindre.
Pour évaluer le modèle
-
Configurez la fonction suivante pour prédire chaque ligne du jeu de tests. Dans l'exemple de code suivant, l'argument
rowssert à spécifier le nombre de lignes à prédire à la fois. Vous pouvez en modifier la valeur pour effectuer une inférence par lots qui utilise entièrement les ressources matérielles de l'instance.import numpy as np def predict(data, rows=1000): split_array = np.array_split(data, int(data.shape[0] / float(rows) + 1)) predictions = '' for array in split_array: predictions = ','.join([predictions, xgb_predictor.predict(array).decode('utf-8')]) return np.fromstring(predictions[1:], sep=',') -
Exécutez le code suivant pour faire des prédictions du jeu de données de test et tracer un histogramme. Vous devez uniquement prendre les colonnes de fonctions du jeu de données de test, à l'exclusion de la colonne 0 pour les valeurs réelles.
import matplotlib.pyplot as plt predictions=predict(test.to_numpy()[:,1:]) plt.hist(predictions) plt.show()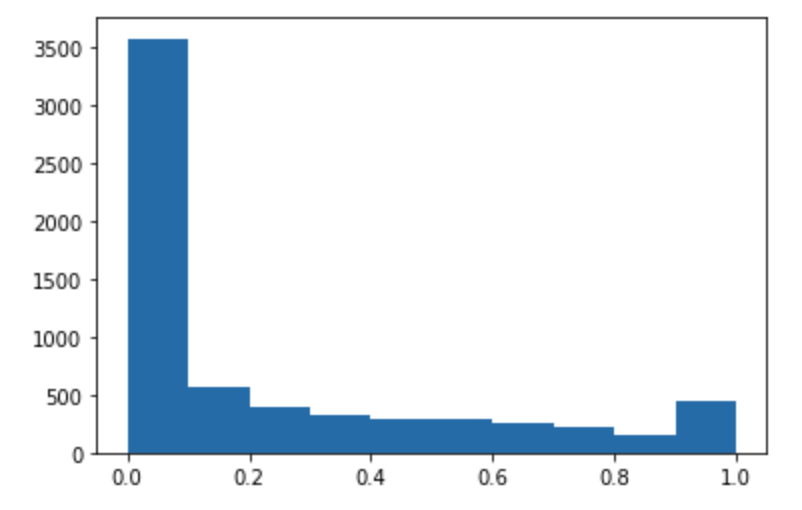
-
Les valeurs prédites sont de type flottant. Pour déterminer
TrueouFalseen fonction des valeurs flottantes, vous devez définir une valeur limite. Comme indiqué dans l'exemple de code suivant, utilisez la Scikit-learn bibliothèque pour renvoyer les mesures de confusion en sortie et le rapport de classification avec un seuil de 0,5.import sklearn cutoff=0.5 print(sklearn.metrics.confusion_matrix(test.iloc[:, 0], np.where(predictions > cutoff, 1, 0))) print(sklearn.metrics.classification_report(test.iloc[:, 0], np.where(predictions > cutoff, 1, 0)))Cela doit renvoyer la matrice de confusion suivante :
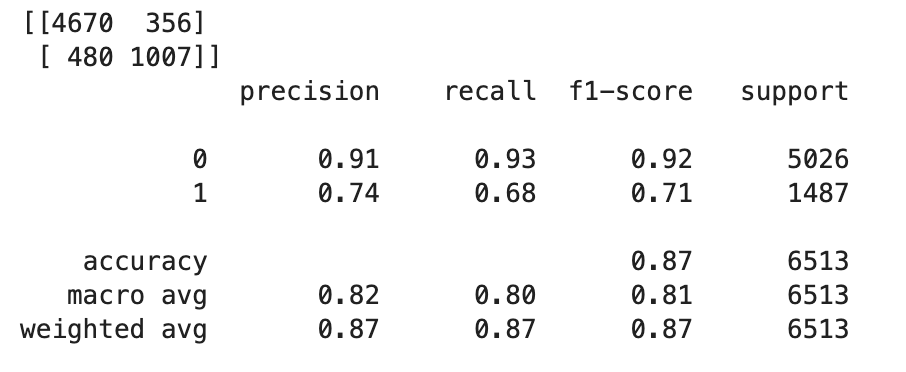
-
Pour trouver la meilleure limite avec l'ensemble de tests donné, calculez la fonction de perte de journaux de la régression logistique. La fonction de perte de journaux est définie comme la probabilité de journalisation négative d'un modèle logistique qui renvoie des probabilités de prédiction pour ses étiquettes Ground Truth. L'exemple de code suivant calcule numériquement et itérativement les valeurs de perte de journaux (
-(y*log(p)+(1-y)log(1-p)), oùyest l'étiquette true etpest une estimation de probabilité de l'exemple de test correspondant. Il renvoie une perte de journaux par rapport au graphique de limite.import matplotlib.pyplot as plt cutoffs = np.arange(0.01, 1, 0.01) log_loss = [] for c in cutoffs: log_loss.append( sklearn.metrics.log_loss(test.iloc[:, 0], np.where(predictions > c, 1, 0)) ) plt.figure(figsize=(15,10)) plt.plot(cutoffs, log_loss) plt.xlabel("Cutoff") plt.ylabel("Log loss") plt.show()Cela doit renvoyer la courbe de perte de journaux suivante.
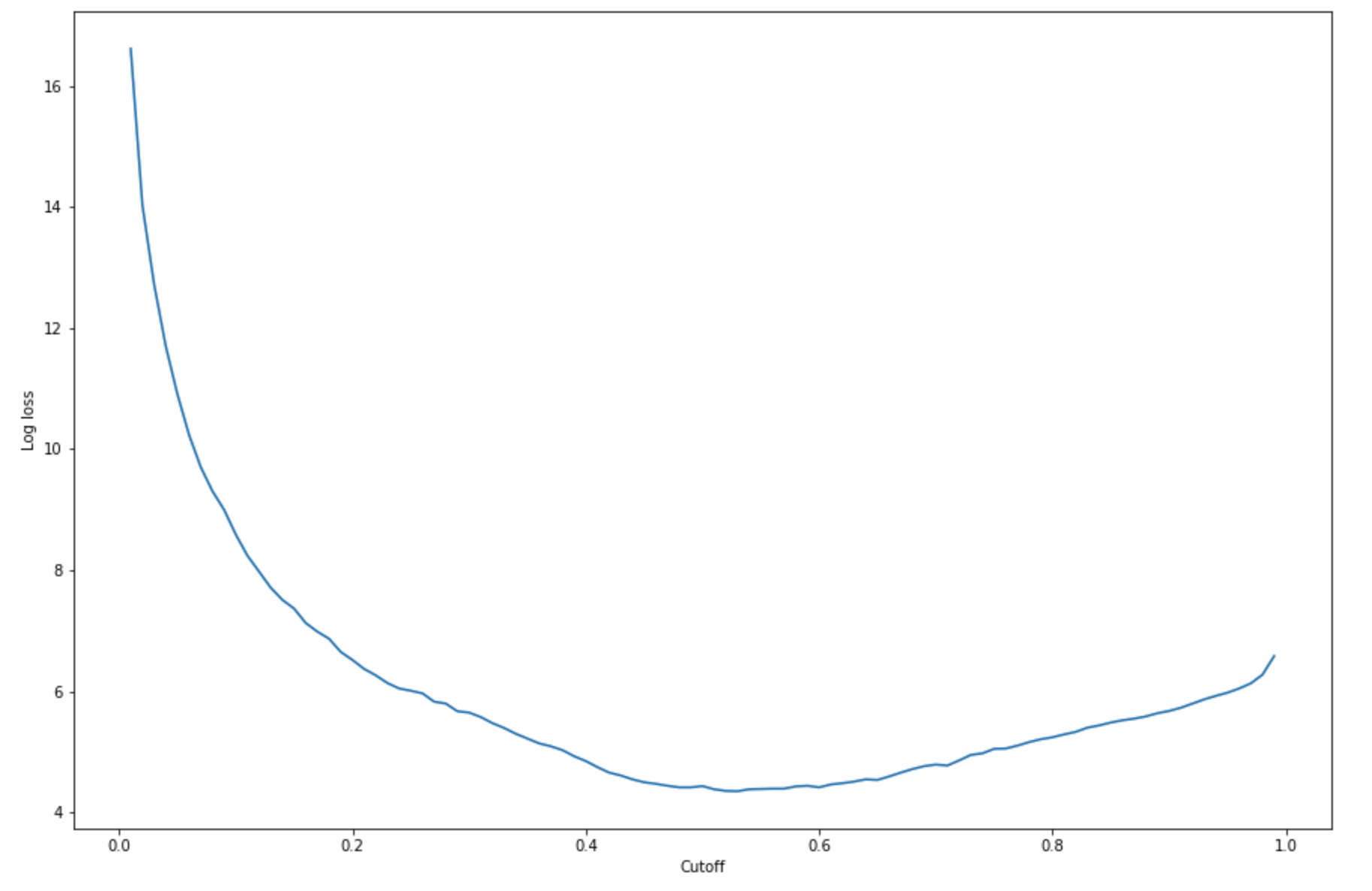
-
Trouvez les points minimaux de la courbe d'erreur à l'aide NumPy
argmindesminfonctions et :print( 'Log loss is minimized at a cutoff of ', cutoffs[np.argmin(log_loss)], ', and the log loss value at the minimum is ', np.min(log_loss) )Cela doit renvoyer :
Log loss is minimized at a cutoff of 0.53, and the log loss value at the minimum is 4.348539186773897.Au lieu de calculer et de réduire la fonction de perte de journaux, vous pouvez estimer une fonction de coût comme alternative. Par exemple, si vous souhaitez entraîner un modèle à effectuer une classification binaire pour un problème métier, tel qu’un problème de prédiction du taux de désabonnement des clients, vous pouvez définir des pondérations sur les éléments de la matrice de confusion et calculer la fonction de coût en conséquence.
Vous avez maintenant formé, déployé et évalué votre premier modèle en SageMaker IA.
Astuce
Pour surveiller la qualité du modèle, la qualité des données et la dérive des biais, utilisez Amazon SageMaker Model Monitor et SageMaker AI Clarify. Pour en savoir plus, consultez Amazon SageMaker Model Monitor, Monitor Data Quality, Monitor Model Quality, Monitor Bias Drift et Monitor Feature Attribution Drift.
Astuce
Pour une vérification humaine des prédictions de ML de faible confiance ou un exemple aléatoire de prédictions, utilisez les flux de vérification humaine de l’IA augmentée d’Amazon. Pour plus d’informations, consultez Utilisation de l’IA augmentée d’Amazon pour la vérification humaine.
