As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Este guia mostra métricas e técnicas de validação que você pode usar para medir o desempenho de modelos de machine learning. O Amazon SageMaker Autopilot produz métricas que medem a qualidade preditiva dos candidatos ao modelo de aprendizado de máquina. As métricas calculadas para candidatos são especificadas usando uma variedade de MetricDatumtipos.
Métricas do Autopilot
A lista a seguir contém os nomes das métricas atualmente disponíveis para medir o desempenho de modelos no Autopilot.
nota
O Autopilot oferece apoio para pesos de amostra. Para saber mais sobre pesos de amostra e as métricas objetivas disponíveis, consulte Métricas ponderadas do Autopilot.
As métricas a seguir estão disponíveis.
Accuracy-
A razão entre o número de itens classificados corretamente e o número total de itens classificados (correta e incorretamente). É usado para classificação binária e multiclasse. A precisão mede o quão próximos estão os valores de classe previstos dos valores reais. Os valores das métricas de precisão variam entre zero (0) e um (1). Um valor de 1 indica precisão perfeita e 0 indica imprecisão perfeita.
AUC-
A métrica de área sob a curva (AUC) é usada para comparar e avaliar a classificação binária por algoritmos que retornam probabilidades, como regressão logística. Para mapear as probabilidades em classificações, elas são comparadas com um valor limite.
A curva relevante é a curva característica de operação do receptor. A curva traça a taxa de positivos verdadeiros (TPR) das predições (ou recall) em relação à taxa de falsos-positivos (FPR) em função do valor limite, acima do qual uma predição é considerada positiva. O aumento do limite resulta em menos falsos-positivos, mas em mais falsos-negativos.
A AUC é a área sob essa curva característica de operação do receptor. Portanto, a AUC fornece uma medida agregada do desempenho de modelos em todos os limites de classificação possíveis. As pontuações AUC variam entre 0 e 1. Uma pontuação de 1 indica precisão perfeita, e uma pontuação de metade (0,5) indica que a predição não é melhor do que um classificador aleatório.
BalancedAccuracy-
BalancedAccuracyé uma métrica que mede a razão entre as predições precisas e todas as predições. Essa razão é calculada após a normalização de positivos verdadeiros (TP) e negativos verdadeiros (TN) pelo número total de valores positivos (P) e negativos (N). É usado na classificação binária e multiclasse e é definido da seguinte forma: 0,5* ((TP/P)+(TN/N)), com valores que variam de 0 a 1.BalancedAccuracyfornece uma melhor medida de precisão quando o número de positivos ou negativos difere muito um do outro em um conjunto de dados desequilibrado, como quando apenas 1% dos e-mails são spam. F1-
A pontuação
F1é a média harmônica da precisão e do recall, definida da seguinte forma: F1 = 2 * (precisão * recall)/(precisão + recall). Ela é usada para classificação binária em classes tradicionalmente chamadas de positivas e negativas. Diz-se que as predições são verdadeiras quando correspondem à classe real (correta) e falsas quando não correspondem.A precisão é a razão entre as predições positivas verdadeiras e todas as predições positivas e inclui os falsos positivos em um conjunto de dados. A precisão mede a qualidade da predição ao prever a classe positiva.
Recall (ou sensibilidade) é a razão entre as predições positivas verdadeiras e todas as instâncias positivas reais. O recall mede o quão completamente um modelo prevê os membros de classe reais em um conjunto de dados.
As pontuações F1 variam entre 0 e 1. Uma pontuação de 1 indica a melhor performance possível, e 0 indica a pior.
F1macro-
A pontuação
F1macroaplica a pontuação F1 a problemas de classificação multiclasse. Ela faz isso calculando a precisão e o recall e, em seguida, calculando a média harmônica para calcular a pontuação F1 para cada classe. Por fim,F1macrocalcula a média das pontuações individuais para obter a pontuaçãoF1macro. As pontuaçõesF1macrovariam entre 0 e 1. Uma pontuação de 1 indica a melhor performance possível, e 0 indica a pior. InferenceLatency-
A latência de inferência é o tempo aproximado entre fazer uma solicitação de predição de modelo e recebê-la de um endpoint em tempo real no qual o modelo é implantado. Essa métrica é medida em segundos e está disponível somente no modo de agrupamento.
LogLoss-
A perda de log, também conhecida como perda de entropia cruzada, é uma métrica usada para avaliar a qualidade das saídas de probabilidade, em vez das saídas em si. Ela é usada para classificação binária e multiclasse e em redes neurais. É também a função de custo da regressão logística. A perda de log é uma métrica importante para indicar quando um modelo faz predições incorretas com altas probabilidades. Os valores variam de 0 a infinito. Um valor de 0 representa um modelo que prevê perfeitamente os dados.
MAE-
O erro absoluto médio (MAE) é uma medida de quão diferentes são os valores previstos e reais, quando se calcula a média de todos os valores. O MAE é comumente usado na análise de regressão para entender o erro de predição de modelo. Se houver regressão linear, o MAE representa a distância média de uma linha prevista até o valor real. O MAE é definido como a soma dos erros absolutos dividida pelo número de observações. Os valores variam de 0 a infinito, com números menores indicando um melhor ajuste do modelo aos dados.
MSE-
O erro quadrático médio (MSE) é a média das diferenças ao quadrado entre os valores previstos e reais. Ele é usado para regressão. Os valores do MSE são sempre positivos. Quanto melhor for o modelo em prever os valores reais, menor será o valor do MSE.
Precision-
A precisão mede o quão bem um algoritmo prevê os positivos verdadeiros (TP) de todos os positivos que ele identifica. Ela é definida da seguinte forma: Precisão = TP/ (TP+FP), com valores que variam de zero (0) a um (1), e é usada na classificação binária. A precisão é uma métrica importante quando o custo de um falso-positivo é alto. Por exemplo, o custo de um falso-positivo é muito alto se o sistema de segurança de um avião for considerado falsamente seguro para voar. Um falso-positivo (FP) reflete uma predição positiva que, na verdade, é negativa nos dados.
PrecisionMacro-
A macro de precisão calcula a precisão para problemas de classificação multiclasse. Ela faz isso calculando a precisão para cada classe e calculando a média das pontuações para obter precisão para várias classes. As pontuações
PrecisionMacrovariam de zero (0) a um (1). Pontuações mais altas refletem a capacidade do modelo de prever positivos verdadeiros (TP) a partir de todos os positivos identificados, com a média de várias classes. R2-
R2, também conhecido como coeficiente de determinação, é usado na regressão para quantificar o quanto um modelo pode explicar a variância de uma variável dependente. Os valores variam de um (1) a menos um (-1). Números maiores indicam uma fração maior de variabilidade explicada. Valores de
R2próximos a zero (0) indicam que muito pouco da variável dependente pode ser explicado pelo modelo. Valores negativos indicam um ajuste ruim, e que o modelo é superado por uma função constante. Para regressão linear, essa é uma linha horizontal. Recall-
O recall mede o quão bem um algoritmo prevê corretamente todos os positivos verdadeiros (TP) em um conjunto de dados. Um positivo verdadeiro é uma predição positiva que também é um valor positivo real nos dados. O recall é definido da seguinte forma: Recall = TP/(TP+FN), com valores que variam de 0 a 1. Pontuações mais altas refletem uma melhor capacidade do modelo de prever positivos verdadeiros (TP) nos dados. Ele é usado na classificação binária.
O recall é importante ao testar o câncer porque é usado para encontrar todos os positivos verdadeiros. Um falso-positivo (FP) reflete uma predição positiva que, na verdade, é negativa nos dados. Frequentemente, é insuficiente medir somente o recall, porque prever cada saída como um positivo verdadeiro produz uma pontuação de recall perfeita.
RecallMacro-
O
RecallMacrocalcula o recall para problemas de classificação multiclasse calculando o recall para cada classe e calculando a média das pontuações para obter o recall de várias classes. As pontuaçõesRecallMacrovariam de 0 a 1. Pontuações mais altas refletem a capacidade do modelo de prever positivos verdadeiros (TP) em um conjunto de dados, enquanto um positivo verdadeiro reflete uma predição positiva que também é um valor positivo real nos dados. Frequentemente, é insuficiente medir apenas o recall, porque prever cada saída como um positivo verdadeiro produzirá uma pontuação de recall perfeita. RMSE-
Erro quadrático médio (RMSE) mede a raiz quadrada da diferença ao quadrado entre os valores previstos e reais. É calculado como a média de todos os valores. Ela é usada em análise de regressão para entender o erro de predição dos modelos. É uma métrica importante para indicar a presença de grandes erros e valores atípicos no modelo. Os valores variam de zero (0) ao infinito, com números menores indicando um melhor ajuste do modelo aos dados. O RMSE depende da escala e não deve ser usado para comparar conjuntos de dados de tamanhos diferentes.
As métricas que são calculadas automaticamente para um candidato a modelo são determinadas pelo tipo de problema que está sendo tratado.
Consulte a documentação de referência SageMaker da API da Amazon para ver a lista de métricas disponíveis suportadas pelo Autopilot.
Métricas ponderadas do Autopilot
nota
O Autopilot oferece apoio para pesos de amostra apenas no modo de agrupamento para todas as métricas disponíveis, com exceção da Balanced Accuracy e InferenceLatency, a BalanceAccuracy vem com seu próprio esquema de ponderação para conjuntos de dados não equilibrados que não exigem pesos de amostra. A InferenceLatency não oferece apoio para pesos de amostra. Tanto a métrica objetiva Balanced Accuracy quanto a InferenceLatency ignoram qualquer peso de amostra existente ao treinar e avaliar um modelo.
Os usuários podem adicionar uma coluna de pesos de amostra aos seus dados para garantir que cada observação usada para treinar um modelo de machine learning receba um peso correspondente à sua importância percebida para o modelo. Isso é especialmente útil em cenários nos quais as observações no conjunto de dados têm vários graus de importância ou nos quais um conjunto de dados contém um número desproporcional de amostras de uma classe em comparação a outras. A atribuição de um peso a cada observação com base em sua importância ou maior importância para uma classe minoritária pode ajudar no desempenho geral de um modelo ou garantir que um modelo não seja tendencioso para a classe majoritária.
Para obter informações sobre como passar os pesos de amostra ao criar um experimento na interface do usuário do Studio Classic, consulte a Etapa 7 em Criação de um experimento do Autopilot usando o Studio Classic.
Para obter informações sobre como passar pesos de amostra programaticamente ao criar um experimento do Autopilot usando a API, consulte Como adicionar pesos de amostra a um trabalho do AutoML em Criação de um experimento do Autopilot programaticamente.
Validação cruzada no Autopilot
A validação cruzada é usada para reduzir o sobreajuste e o desvio na seleção de modelo. Ela também é usada para avaliar o quão bem um modelo pode prever os valores de um conjunto de dados de validação invisível, se o conjunto de dados de validação for extraído da mesma população. Esse método é especialmente importante ao treinar em conjuntos de dados com um número limitado de instâncias de treinamento.
O Autopilot usa validação cruzada para criar modelos no modo de otimização de hiperparâmetros (HPO) e treinamento em conjunto. A primeira etapa do processo de validação cruzada do Autopilot é dividir os dados em k-folds.
Divisão k-fold
A divisão K-fold é um método que separa um conjunto de dados de treinamento de entrada em vários conjuntos de dados de treinamento e validação. O conjunto de dados é dividido em subamostras de k de tamanhos iguais, chamadas de folds. Os modelos são então treinados em k-1 folds e testados em relação ao késimo fold restante, que é o conjunto de dados de validação. O processo é repetido k vezes usando um conjunto de dados diferente para validação.
A imagem a seguir mostra a divisão de k-fold com k = 4 folds. Cada fold é representado como uma linha. As caixas em tons escuros representam as partes dos dados usadas no treinamento. As caixas em tons claros restantes indicam os conjuntos de dados de validação.

O Autopilot usa validação cruzada de k-fold para criar modelos no modo de otimização de hiperparâmetros (HPO) e de agrupamento.
Você pode implantar modelos de piloto automático criados usando validação cruzada, como faria com qualquer outro modelo de piloto automático ou SageMaker de IA.
Modo HPO
A validação cruzada k-fold usa o método de divisão k-fold para validação cruzada. No modo HPO, o Autopilot implementa automaticamente a validação cruzada k-fold para pequenos conjuntos de dados com 50.000 ou menos instâncias de treinamento. A realização da validação cruzada é especialmente importante ao treinar em pequenos conjuntos de dados, pois protege contra sobreajuste e desvio de seleção.
O modo HPO usa um valor k de 5 em cada um dos algoritmos candidatos usados para modelar o conjunto de dados. Vários modelos são treinados em diferentes divisões, e os modelos são armazenados separadamente. Quando o treinamento é concluído, a média das métricas de validação de cada um dos modelos é calculada para produzir uma única métrica de estimativa. Por fim, o Autopilot combina os modelos do teste com a melhor métrica de validação em um modelo de agrupamento. O Autopilot usa esse modelo de agrupamento para fazer predições.
A métrica de validação para os modelos treinados pelo Autopilot é apresentada como a métrica objetiva no placar de modelos. O Autopilot usa a métrica de validação padrão para cada tipo de problema que ele trata, a menos que você especifique o contrário. Para obter uma lista de todas as métricas utilizadas pelo Autopilot, consulte Métricas do Autopilot.
Por exemplo, o conjunto de dados Boston Housing
A validação cruzada pode aumentar os tempos de treinamento em uma média de 20%. Os tempos de treinamento também podem aumentar significativamente para conjuntos de dados complexos.
nota
No modo HPO, você pode ver as métricas de treinamento e validação de cada dobra em seus /aws/sagemaker/TrainingJobs CloudWatch registros. Para obter mais informações sobre CloudWatch registros, consulteGrupos de registros e streams que o Amazon SageMaker AI envia para o Amazon CloudWatch Logs.
Modo de agrupamento
nota
O Autopilot oferece apoio a pesos de amostra no modo de agrupamento. Para obter a lista de métricas disponíveis que oferecem apoio a pesos de amostra, consulte Métricas do Autopilot.
No modo de agrupamento, a validação cruzada é realizada independentemente do tamanho do conjunto de dados. Os clientes podem fornecer seu próprio conjunto de dados de validação e taxa de divisão de dados personalizada ou podem deixar o Autopilot dividir o conjunto de dados automaticamente em uma taxa de divisão de 80-20%. Os dados de treinamento são então divididos em k -folds para validação cruzada, onde o valor de k é determinado pelo mecanismo. AutoGluon Um agrupamento consiste em vários modelos de machine learning, em que cada modelo é conhecido como o modelo básico. Um modelo de base única é treinado em (k-1) dobras e faz out-of-fold previsões na dobra restante. Esse processo é repetido em todas as k dobras, e as previsões out-of-fold (OOF) são concatenadas para formar um único conjunto de previsões. Todos os modelos básicos do agrupamento seguem esse mesmo processo de geração de predições OOF.
A imagem a seguir mostra a validação de k-fold com k = 4 folds. Cada fold é representado como uma linha. As caixas em tons escuros representam as partes dos dados usadas no treinamento. As caixas em tons claros restantes indicam os conjuntos de dados de validação.
Na parte superior da imagem, em cada fold, o primeiro modelo básico faz predições no conjunto de dados de validação após o treinamento nos conjuntos de dados de treinamento. Em cada fold subsequente, os conjuntos de dados mudam de função. Um conjunto de dados que antes era usado para treinamento agora é usado para validação, e isso também se aplica ao contrário. No final das k dobras, todas as previsões são concatenadas para formar um único conjunto de previsões chamado de previsão (OOF). out-of-fold Esse processo é repetido para cada modelo básico de n.
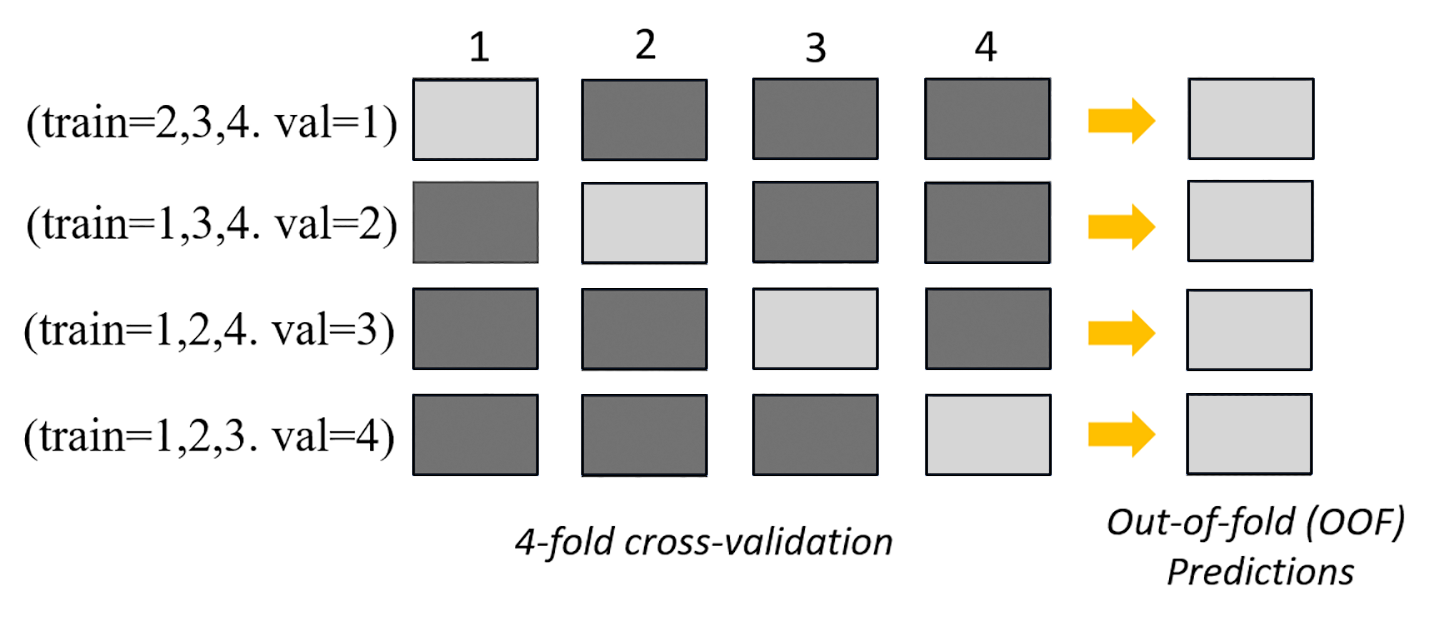
As predições OOF para cada modelo básico são então usadas como atributos para treinar um modelo de empilhamento. O modelo de empilhamento aprende os pesos de importância de cada modelo básico. Esses pesos são usados para combinar as predições OOF para formar a predição final. A performance no conjunto de dados de validação determina qual modelo básico ou de empilhamento é o melhor, e esse modelo é retornado como o modelo final.
No modo de agrupamento, você pode fornecer seu próprio conjunto de dados de validação ou permitir que o Autopilot divida o conjunto de dados de entrada automaticamente em conjunto de dados 80% de treinamento e 20% de validação. Os dados de treinamento são então divididos em k-folds para validação cruzada e produzem uma predição OOF e um modelo básico para cada fold.
Essas predições OOF são usadas como atributos para treinar um modelo de empilhamento, que aprende simultaneamente os pesos para cada modelo básico. Esses pesos são usados para combinar as predições OOF para formar a predição final. Os conjuntos de dados de validação para cada fold são usados para o ajuste de hiperparâmetros de todos os modelos básicos e do modelo de empilhamento. A performance no conjunto de dados de validação determina qual modelo básico ou de empilhamento é o melhor, e esse modelo é retornado como o modelo final.
