As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
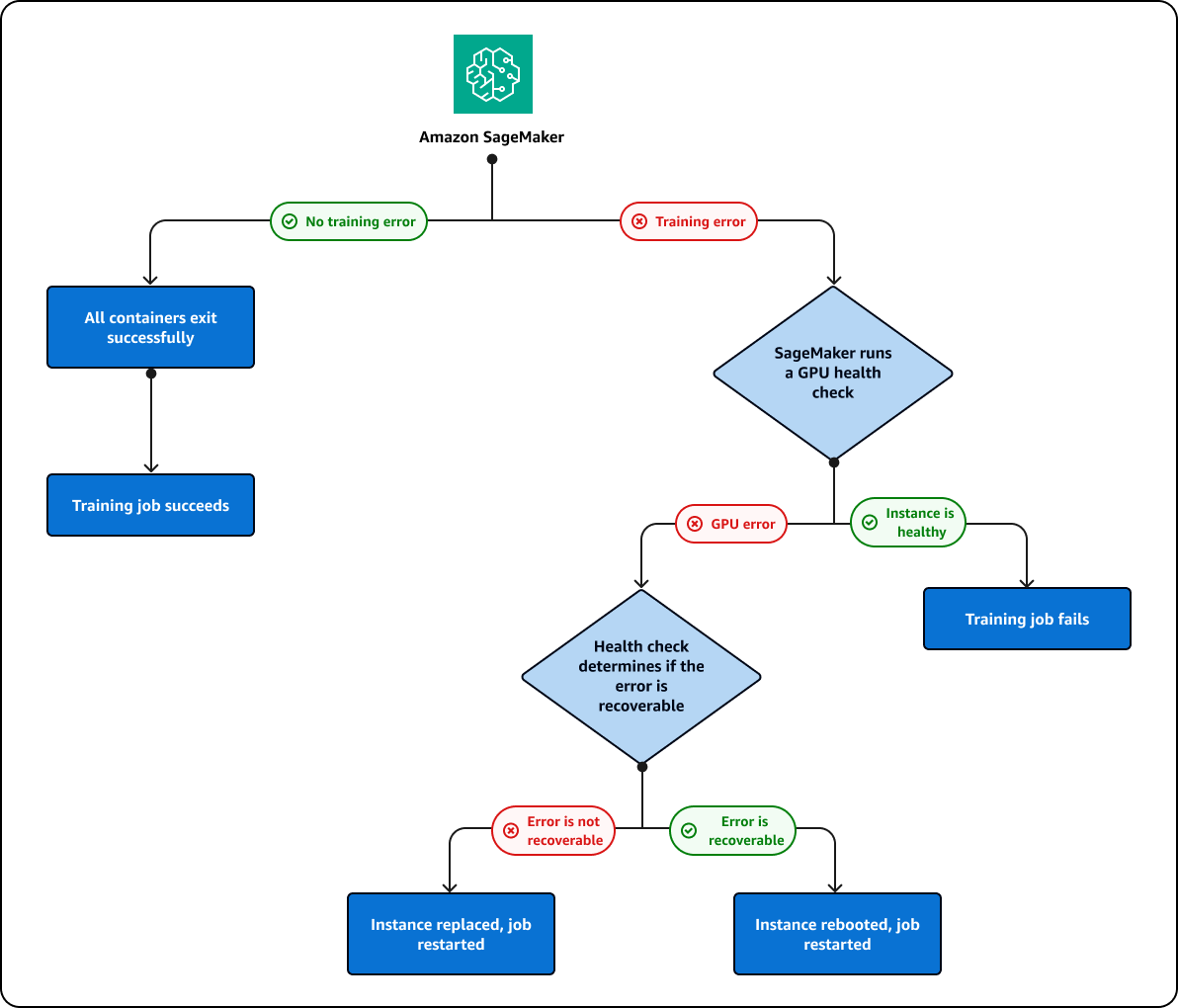
Se você estiver executando um trabalho de treinamento que falha em uma GPU, a SageMaker IA executará uma verificação de integridade da GPU para ver se a falha está relacionada a um problema na GPU. SageMaker A IA realiza as seguintes ações com base nos resultados da verificação de integridade:
Se o erro for recuperável e puder ser corrigido reinicializando a instância ou redefinindo a GPU, a SageMaker IA reinicializará a instância.
Se o erro não for recuperável e for causado por uma GPU que precisa ser substituída, a SageMaker IA substituirá a instância.
A instância é substituída ou reinicializada como parte de um processo de reparo do cluster de SageMaker IA. Durante esse processo, você receberá a seguinte mensagem no status do trabalho de treinamento:
Repairing training cluster due to hardware failure
SageMaker A IA tentará reparar o cluster 10 várias vezes. Se o reparo do cluster for bem-sucedido, a SageMaker IA reiniciará automaticamente o trabalho de treinamento a partir do ponto de verificação anterior. Se o reparo do cluster falhar, o trabalho de treinamento também falhará. Você não será cobrado pelo processo de reparo do cluster. Os reparos do cluster não serão iniciados a menos que o trabalho de treinamento falhe. Se um problema de GPU for detectado em um cluster de grupo de aquecimento, o cluster entrará no modo de reparo para reinicializar ou substituir a instância com defeito. Após o reparo, o cluster ainda pode ser usado como um cluster de grupo de aquecimento.
O processo de reparo de cluster e instância descrito anteriormente do é representado no seguinte diagrama: