As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Esta seção fornece instruções sobre como executar um trabalho de treinamento usando um cluster heterogêneo que consiste em vários tipos de instância.
Verifique o seguinte antes de começar:
-
Todos os grupos de instâncias compartilham a mesma imagem do Docker e o mesmo script de treinamento. Portanto, seu script de treinamento deve ser modificado para detectar a qual grupo de instâncias ele pertence e bifurcar a execução adequadamente.
-
O recurso de cluster heterogêneo não é compatível com o modo local de SageMaker IA.
-
Os fluxos de CloudWatch log da Amazon de um trabalho de treinamento de cluster heterogêneo não são agrupados por grupos de instâncias. Você precisa descobrir nos logs quais são os nós que estão em qual grupo.
Opção 1: usar o SDK do SageMaker Python
Siga as instruções sobre como configurar grupos de instâncias para um cluster heterogêneo usando o SDK do Python SageMaker .
-
Para configurar grupos de instâncias de um cluster heterogêneo para um trabalho de treinamento, use a classe
sagemaker.instance_group.InstanceGroup. Você pode especificar um nome personalizado para cada grupo de instâncias, o tipo de instância e o número de instâncias para cada grupo de instâncias. Para obter mais informações, consulte sagemaker.instance_group. InstanceGroupna documentação do SageMaker AI Python SDK. nota
Para obter mais informações sobre os tipos de instância disponíveis e o número máximo de grupos de instâncias que você pode configurar em um cluster heterogêneo, consulte a referência da InstanceGroupAPI.
O exemplo de código a seguir mostra como configurar dois grupos de instâncias que consistem em duas instâncias
ml.c5.18xlargesomente de CPU nomeadasinstance_group_1e uma instância de GPUml.p3dn.24xlargechamadainstance_group_2, conforme mostrado no diagrama a seguir.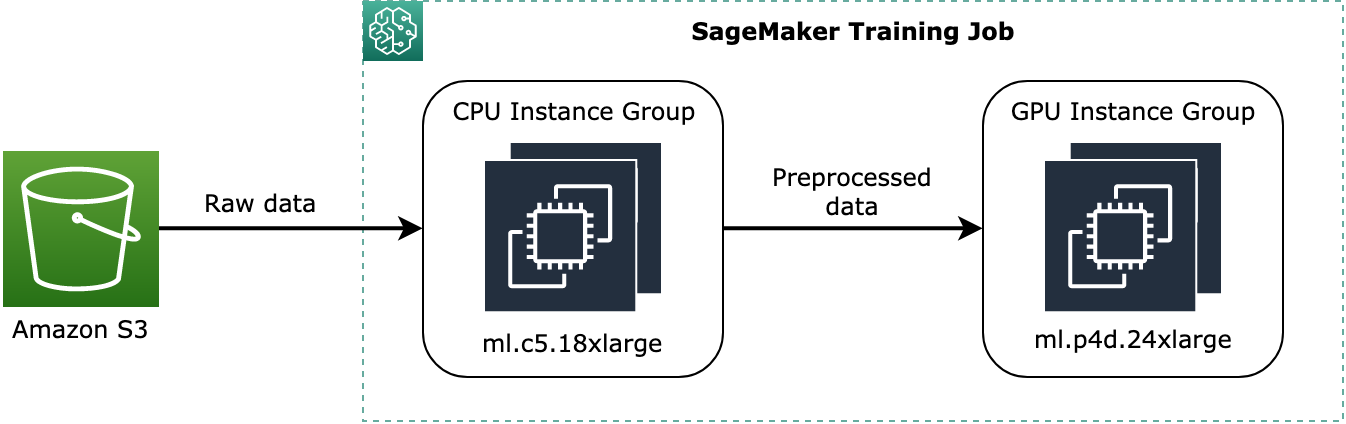
O diagrama anterior mostra um exemplo conceitual de como os processos de pré-treinamento, como o pré-processamento de dados, podem ser atribuídos ao grupo de instâncias da CPU e transmitir os dados pré-processados para o grupo de instâncias da GPU.
from sagemaker.instance_group import InstanceGroup instance_group_1 = InstanceGroup( "instance_group_1", "ml.c5.18xlarge",2) instance_group_2 = InstanceGroup( "instance_group_2", "ml.p3dn.24xlarge",1) -
Usando os objetos do grupo de instâncias, configure canais de entrada de treinamento e atribua grupos de instâncias aos canais por meio do
instance_group_namesargumento do sagemaker.inputs. TrainingInputclasse. O argumento instance_group_namesaceita uma lista de strings de nomes de grupos de instâncias.O exemplo a seguir mostra como definir dois canais de entrada de treinamento e atribuir os grupos de instâncias criados no exemplo da etapa anterior. Você também pode especificar caminhos de bucket do Amazon S3 para o argumento
s3_datapara que os grupos de instâncias processem dados para suas finalidades de uso.from sagemaker.inputs import TrainingInput training_input_channel_1 = TrainingInput( s3_data_type='S3Prefix', # Available Options: S3Prefix | ManifestFile | AugmentedManifestFile s3_data='s3://your-training-data-storage/folder1', distribution='FullyReplicated', # Available Options: FullyReplicated | ShardedByS3Key input_mode='File', # Available Options: File | Pipe | FastFile instance_groups=["instance_group_1"] ) training_input_channel_2 = TrainingInput( s3_data_type='S3Prefix', s3_data='s3://your-training-data-storage/folder2', distribution='FullyReplicated', input_mode='File', instance_groups=["instance_group_2"] )Para obter mais informações sobre os argumentos de
TrainingInput, consulte os seguintes links:-
O sagemaker.inputs. TrainingInput
classe na documentação do SageMaker Python SDK -
A DataSource API S3 na referência da API SageMaker AI
-
-
Configure um estimador de SageMaker IA com o
instance_groupsargumento, conforme mostrado no exemplo de código a seguir. O argumentoinstance_groupsaceita uma lista de objetosInstanceGroup.nota
O recurso de cluster heterogêneo está disponível por meio das classes de estimadores de TensorFlow
estrutura PyTorch e SageMaker IA. As estruturas suportadas são PyTorch v1.10 ou posterior e TensorFlow v2.6 ou posterior. Para encontrar uma lista completa dos contêineres, versões do framework e versões do Python disponíveis, consulte Contêineres do SageMaker AI Framework no repositório do AWS Deep Learning Container GitHub . from sagemaker.pytorchimportPyTorchestimator =PyTorch( ... entry_point='my-training-script.py', framework_version='x.y.z', # 1.10.0 or later py_version='pyxy', job_name='my-training-job-with-heterogeneous-cluster', instance_groups=[instance_group_1,instance_group_2] )nota
O
instance_typepar deinstance_countargumentos e e oinstance_groupsargumento da classe de SageMaker estimadores de IA são mutuamente exclusivos. Para um treinamento de cluster homogêneo, use o par de argumentosinstance_typeeinstance_count. Para treinamento de clusters heterogêneos, useinstance_groups.nota
Para encontrar uma lista completa dos contêineres, versões do framework e versões do Python disponíveis, consulte Contêineres do SageMaker AI Framework
no repositório do AWS Deep Learning Container GitHub . -
Configure o
estimator.fitmétodo com os canais de entrada de treinamento configurados com os grupos de instâncias e inicie o trabalho de treinamento.estimator.fit( inputs={ 'training':training_input_channel_1, 'dummy-input-channel':training_input_channel_2} )
Opção 2: Usando o nível baixo SageMaker APIs
Se você usa o AWS Command Line Interface ou AWS SDK for Python (Boto3) e deseja usar o nível baixo SageMaker APIs para enviar uma solicitação de trabalho de treinamento com um cluster heterogêneo, consulte as referências de API a seguir.
