As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Consulte os itens de perguntas frequentes a seguir para obter respostas às perguntas mais frequentes sobre SageMaker AI Inference Hosting.
Hospedagem geral
Os itens de perguntas frequentes a seguir respondem a perguntas gerais comuns sobre inferência de SageMaker IA.
R: Depois de criar e treinar modelos, a Amazon SageMaker AI oferece quatro opções para implantá-los para que você possa começar a fazer previsões. A inferência em tempo real é adequada para workloads com requisitos de latência de milissegundos, tamanhos de carga útil de até 6 MB e tempos de processamento de até 60 segundos. O Transformação em lote é ideal para predições offline em grandes lotes de dados que estão disponíveis antecipadamente. A inferência assíncrona foi projetada para workloads que não têm requisitos de latência inferior a um segundo, tamanhos de carga útil de até 1 GB e tempos de processamento de até 15 minutos. Com a Inferência Sem Servidor, você pode implantar rapidamente modelos de machine learning para inferência sem precisar configurar ou gerenciar a infraestrutura subjacente, e você paga somente pela capacidade computacional usada para processar solicitações de inferência, o que é ideal para workloads intermitentes.
R: O diagrama a seguir pode ajudar você a escolher uma opção de implantação do modelo SageMaker AI Hosting.
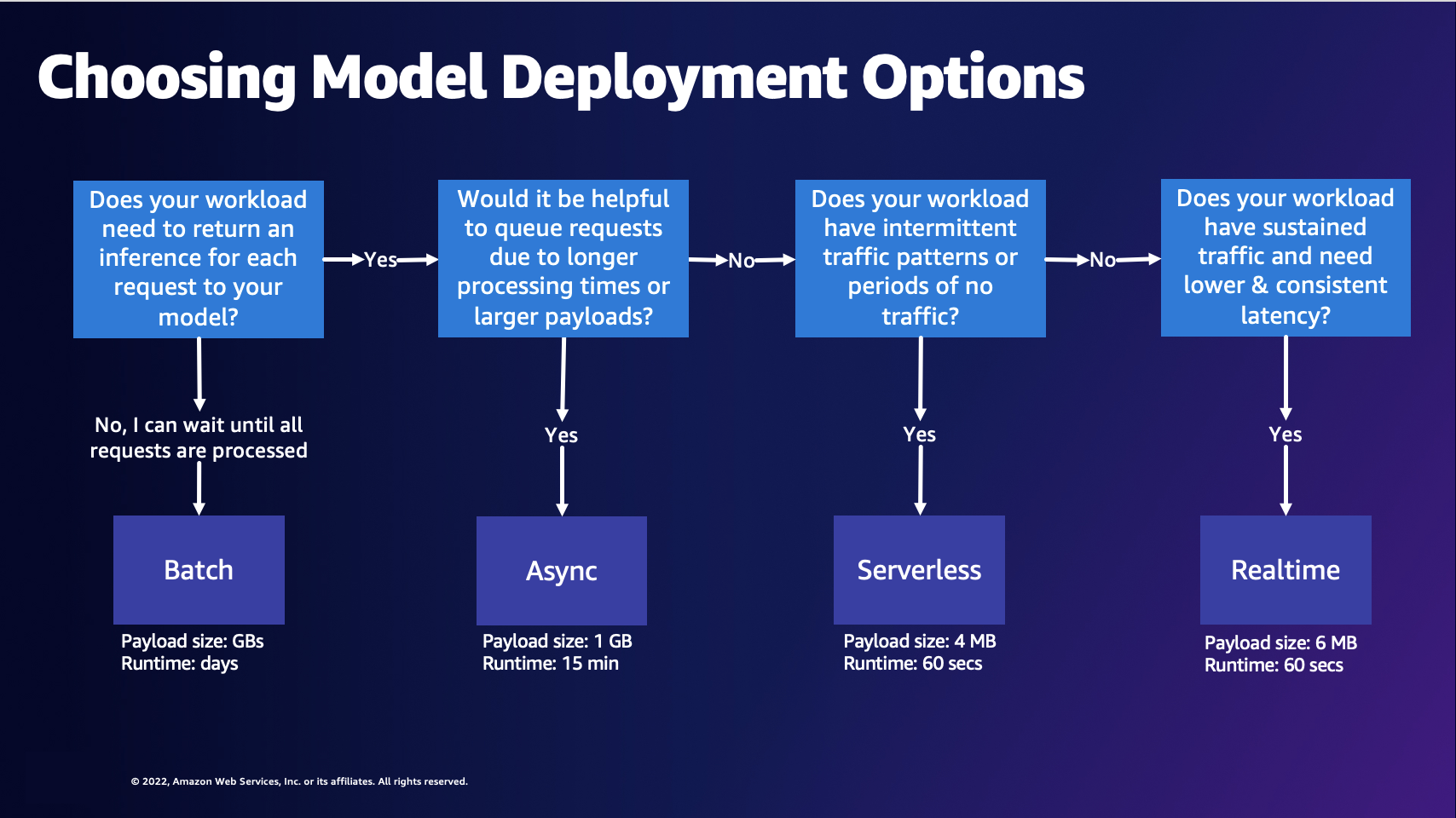
O diagrama anterior mostra o processo de decisão a seguir. Se quiser processar solicitações em lotes, talvez queira escolher Transformação em lote. Caso contrário, se você quiser receber inferência para cada solicitação ao seu modelo, talvez queira escolher inferência assíncrona, Inferência Sem Servidor ou inferência em tempo real. Você pode escolher a inferência assíncrona se tiver longos tempos de processamento ou grandes cargas úteis e quiser enfileirar solicitações. Você pode escolher a Inferência Sem Servidor se sua workload tiver tráfego imprevisível ou intermitente. Você pode escolher a inferência em tempo real se tiver tráfego sustentado e precisar de uma latência menor e consistente para suas solicitações.
R: O diagrama a seguir pode ajudar você a escolher uma opção de implantação do modelo SageMaker AI Hosting.
O diagrama anterior mostra o processo de decisão a seguir. Se quiser processar solicitações em lotes, talvez queira escolher Transformação em lote. Caso contrário, se você quiser receber inferência para cada solicitação ao seu modelo, talvez queira escolher inferência assíncrona, Inferência Sem Servidor ou inferência em tempo real. Você pode escolher a inferência assíncrona se tiver longos tempos de processamento ou grandes cargas úteis e quiser enfileirar solicitações. Você pode escolher a Inferência Sem Servidor se sua workload tiver tráfego imprevisível ou intermitente. Você pode escolher a inferência em tempo real se tiver tráfego sustentado e precisar de uma latência menor e consistente para suas solicitações.
R: Para otimizar seus custos com o SageMaker AI Inference, você deve escolher a opção de hospedagem certa para seu caso de uso. Você também pode usar recursos de inferência, como Amazon SageMaker AI Savings Plans
R: Você deve usar o Amazon SageMaker Inference Recommender se precisar de recomendações para a configuração correta do endpoint para melhorar o desempenho e reduzir custos. Anteriormente, os cientistas de dados que queriam implantar seus modelos precisavam executar benchmarks manuais para selecionar a configuração correta do endpoint. Primeiro, eles precisaram selecionar o tipo certo de instância de machine learning entre mais de 70 tipos de instância disponíveis com base nos requisitos de recursos de seus modelos e cargas úteis de amostra e, em seguida, otimizar o modelo para considerar diferentes hardwares. Em seguida, eles tiveram que realizar testes de carga extensivos para validar se os requisitos de latência e throughput foram atendidos e se os custos eram baixos. O Inference Recommender elimina essa complexidade ao ajudar você a fazer o seguinte:
-
Comece em minutos com uma recomendação de instância.
-
Realize testes de carga em todos os tipos de instância para obter recomendações sobre a configuração do seu endpoint em poucas horas.
-
Ajuste automaticamente os parâmetros do contêiner e do servidor de modelo, além de realizar otimizações de modelo para um determinado tipo de instância.
R: Os endpoints de SageMaker IA são pontos de extremidade HTTP REST que usam um servidor web em contêineres, que inclui um servidor modelo. Esses contêineres são responsáveis por carregar e atender às solicitações de um modelo de machine learning. Eles implementam um servidor web que responda a /invocations e /ping na porta 8080.
Os servidores de modelos comuns incluem TensorFlow Serving TorchServe e Multi Model Server. SageMaker Os contêineres da estrutura de IA têm esses servidores de modelo integrados.
R: Tudo no SageMaker AI Inference é armazenado em contêineres. SageMaker A IA fornece contêineres gerenciados para estruturas populares TensorFlow, como SKlearn, e. HuggingFace Para obter uma lista abrangente e atualizada dessas imagens, consulte Imagens disponíveis
Às vezes, há estruturas personalizadas para as quais talvez seja necessário criar um contêiner. Essa abordagem é conhecida como Traga seu próprio contêiner ou BYOC (Bring Your Own Container). Com a abordagem BYOC, você fornece a imagem do Docker para configurar sua estrutura ou biblioteca. Em seguida, você envia a imagem para o Amazon Elastic Container Registry (Amazon ECR) para poder usar a imagem SageMaker com IA. Para ver um exemplo de uma abordagem de BYOC, consulte Visão geral dos contêineres para Amazon AI
Como alternativa, em vez de criar uma imagem do zero, você pode estender um contêiner. Você pode pegar uma das imagens básicas que a SageMaker IA fornece e adicionar suas dependências em cima dela no Dockerfile.
R: A SageMaker IA oferece a capacidade de trazer seu próprio modelo de estrutura treinado que você treinou fora da SageMaker IA e implantá-lo em qualquer uma das opções de hospedagem de SageMaker IA.
SageMaker A IA exige que você empacote o modelo em um model.tar.gz arquivo e tenha uma estrutura de diretórios específica. Cada estrutura tem sua própria estrutura de modelo (consulte a pergunta a seguir para ver exemplos de estruturas). Para obter mais informações, consulte a documentação do SDK do SageMaker Python para TensorFlow
Embora você possa escolher entre imagens de estrutura pré-criadas TensorFlow, como, PyTorch, e MXNet para hospedar seu modelo treinado, você também pode criar seu próprio contêiner para hospedar seus modelos treinados em endpoints de SageMaker IA. Para uma explicação passo a passo, consulte o exemplo do caderno Jupyter Criando seu próprio contêiner de algoritmo
R: A SageMaker IA exige que os artefatos do seu modelo sejam compactados em um .tar.gz arquivo ou em um arquivo tar. SageMaker O AI extrai automaticamente esse .tar.gz arquivo no /opt/ml/model/ diretório do seu contêiner. O tarball não deve conter links simbólicos ou arquivos desnecessários. Se você estiver usando um dos contêineres da estrutura, como TensorFlow, PyTorch, ou MXNet, o contêiner espera que sua estrutura TAR seja a seguinte:
TensorFlow
model.tar.gz/
|--[model_version_number]/
|--variables
|--saved_model.pb
code/
|--inference.py
|--requirements.txtPyTorch
model.tar.gz/
|- model.pth
|- code/
|- inference.py
|- requirements.txt # only for versions 1.3.1 and higherMXNet
model.tar.gz/
|- model-symbol.json
|- model-shapes.json
|- model-0000.params
|- code/
|- inference.py
|- requirements.txt # only for versions 1.6.0 and higherR: ContentType é o tipo MIME dos dados de entrada no corpo da solicitação (o tipo MIME dos dados que você está enviando para o seu endpoint). O servidor modelo usa o ContentType para determinar se ele pode lidar com o tipo fornecido ou não.
Accept é o tipo MIME da resposta de inferência (o tipo MIME dos dados que seu endpoint retorna). O servidor modelo usa o tipo Accept para determinar se ele pode lidar com o tipo fornecido ou não.
Os tipos comuns de MIME incluem text/csv, application/json e application/jsonlines.
R: A SageMaker IA passa qualquer solicitação para o contêiner do modelo sem modificação. O contêiner deve conter a lógica para desserializar a solicitação. Para obter informações sobre os formatos definidos para algoritmos integrados, consulte Formatos de dados comuns para inferência. Se você estiver criando seu próprio contêiner ou usando um contêiner do SageMaker AI Framework, poderá incluir a lógica para aceitar um formato de solicitação de sua escolha.
Da mesma forma, a SageMaker IA também retorna a resposta sem modificação e, em seguida, o cliente deve desserializar a resposta. No caso dos algoritmos integrados, eles retornam respostas em formatos específicos. Se você estiver criando seu próprio contêiner ou usando um contêiner do SageMaker AI Framework, poderá incluir a lógica para retornar uma resposta no formato escolhido.
Use a chamada da API Invoke Endpoint para fazer inferências em relação ao seu endpoint.
Ao passar sua entrada como carga útil para a API InvokeEndpoint, você deve fornecer o tipo correto de dados de entrada que seu modelo espera. Ao transmitir uma carga útil na chamada da API InvokeEndpoint, os bytes da solicitação são encaminhados diretamente para o contêiner do modelo. Por exemplo, para uma imagem, você pode usar application/jpeg para o ContentType e garantir que seu modelo possa realizar inferências sobre esse tipo de dados. Isso se aplica a JSON, CSV, vídeo ou qualquer outro tipo de entrada com a qual você possa estar lidando.
Outro fator a ser considerado são os limites de tamanho da carga útil. Em termos de endpoints em tempo real e sem servidor, o limite de carga útil é de 6 MB. Você pode dividir seu vídeo em vários quadros e invocar o endpoint com cada quadro individualmente. Como alternativa, se o seu caso de uso permitir, você pode enviar o vídeo inteiro na carga útil usando um endpoint assíncrono, que é compatível com cargas úteis de até 1 GB.
Para ver um exemplo que mostra como executar inferência de visão computacional em vídeos grandes com inferência assíncrona, consulte esta postagem do blog.
Inferência em tempo real
Os itens de perguntas frequentes a seguir respondem a perguntas comuns sobre a inferência em tempo real de SageMaker IA.
R: Você pode criar um endpoint de SageMaker IA por meio AWS de ferramentas compatíveis, como o SDK AWS SDKs do SageMaker Python, o, e o. AWS Management Console AWS CloudFormation AWS Cloud Development Kit (AWS CDK)
Há três entidades principais na criação de endpoints: um modelo de SageMaker IA, uma configuração de endpoint de SageMaker IA e um endpoint de SageMaker IA. O modelo de SageMaker IA aponta para os dados e a imagem do modelo que você está usando. A configuração do endpoint define suas variantes de produção, que podem incluir o tipo de instância e a contagem de instâncias. Em seguida, você pode usar a chamada da API create_endpoint
R: Não, você pode usar os vários AWS SDKs (consulte Invoke/Create for available SDKs) ou até mesmo ligar APIs diretamente para a web correspondente.
R: Um endpoint multimodelo é uma opção de inferência em tempo real fornecida pela IA. SageMaker Com endpoints multimodelo, você pode hospedar milhares de modelos atrás de um endpoint. O Multi Model Server
R: O SageMaker AI Real-Time Inference oferece suporte a várias arquiteturas de implantação de modelos, como endpoints multimodelo, endpoints de vários contêineres e pipelines de inferência serial.
Endpoints multimodelo (MME): O MME permite que os clientes implantem milhares de modelos hiperpersonalizados de forma econômica. Todos os modelos são implantados em uma frota de recursos compartilhados. O MME funciona melhor quando os modelos têm tamanho e latência semelhantes e pertencem à mesma estrutura de ML. Esses endpoints são ideais para quando você não precisa chamar o mesmo modelo o tempo todo. Você pode carregar dinamicamente os respectivos modelos no endpoint de SageMaker IA para atender à sua solicitação.
Endpoints de vários contêineres (MCE) — O MCE permite que os clientes implantem 15 contêineres diferentes com diversas estruturas e funcionalidades de ML sem inicialização a frio, usando apenas um endpoint. SageMaker Você pode invocar diretamente esses contêineres. O MCE é melhor para quando você deseja manter todos os modelos na memória.
Pipelines de inferência serial (SIP): Você pode usar o SIP para encadear de 2 a 15 contêineres em um único endpoint. O SIP é principalmente adequado para combinar pré-processamento e inferência de modelos em um endpoint e para operações de baixa latência.
Inferência Sem Servidor
Os itens de perguntas frequentes a seguir respondem a perguntas comuns sobre o Amazon SageMaker Serverless Inference.
R: Implante modelos com o Amazon SageMaker Serverless Inference é uma opção de fornecimento de modelos sem servidor criada especificamente para facilitar a implantação e o dimensionamento de modelos de ML. Os endpoints da Inferência Sem Servidor iniciam automaticamente os recursos de computação e aumentam e reduzem a escala horizontalmente, dependendo do tráfego, eliminando a necessidade de escolher tipos de instância ou gerenciar políticas de ajuste de escala. Opcionalmente, você pode especificar os requisitos de memória do endpoint sem servidor. Você paga somente pela duração da execução do código de inferência e pela quantidade de dados processados, não pelos períodos de inatividade.
R: A Inferência Sem Servidor simplifica a experiência do desenvolvedor, eliminando a necessidade de provisionar capacidade antecipadamente e gerenciar políticas de ajuste de escala. A Inferência Sem Servidor pode ser escalada instantaneamente de dezenas a milhares de inferências em segundos com base nos padrões de uso, tornando-a ideal para aplicações de ML com tráfego intermitente ou imprevisível. Por exemplo, um serviço de chatbot usado por uma empresa de processamento de folha de pagamento experimenta um aumento nas consultas no final do mês, enquanto o tráfego é intermitente no resto do mês. O provisionamento de instâncias para o mês inteiro nesses cenários não é econômico, pois você acaba pagando por períodos de inatividade.
A Inferência Sem Servidor ajuda a lidar com esses tipos de casos de uso, fornecendo ajuste de escala automático e rápido, sem a necessidade de prever o tráfego antecipadamente ou gerenciar políticas de ajuste de escala. Além disso, você paga somente pelo tempo de computação para executar seu código de inferência e pelo processamento de dados, o que o torna ideal para workloads com tráfego intermitente.
R: Seu endpoint sem servidor tem um tamanho mínimo de RAM de 1024 MB (1 GB), e o tamanho máximo de RAM que você pode escolher é 6144 MB (6 GB). Os tamanhos de memória que você pode escolher são 1024 MB, 2048 MB, 3072 MB, 4096 MB, 5120 MB ou 6144 MB. A Inferência Sem Servidor atribui automaticamente recursos computacionais proporcionais à memória que você seleciona. Se você escolher um tamanho de memória maior, seu contêiner terá acesso a mais CPUs v.
Escolha o tamanho da memória do seu endpoint de acordo com o tamanho do modelo. Geralmente, o tamanho da memória deve ser pelo menos tão grande quanto o tamanho do modelo. Talvez seja necessário fazer um benchmark para escolher a seleção de memória certa para seu modelo com base na sua latência SLAs. Os incrementos do tamanho da memória têm preços diferentes; consulte a página de SageMaker preços da Amazon
Transformação em lote
Os itens de perguntas frequentes a seguir respondem a perguntas comuns sobre o SageMaker AI Batch Transform.
R: Para formatos de arquivo específicos, como CSV, ReCordio TFRecord e SageMaker , o AI pode dividir seus dados em minilotes de registro único ou de vários registros e enviá-los como carga útil para o contêiner do modelo. Quando o valor de BatchStrategy éMultiRecord, a SageMaker IA envia o número máximo de registros em cada solicitação, até o MaxPayloadInMB limite. Quando o valor de BatchStrategy éSingleRecord, a SageMaker IA envia registros individuais em cada solicitação.
R: O tempo máximo para transformação em lote é de 3600 segundos. O tamanho máximo da carga útil de um registro (por minilote) é de 100 MB.
Se você estiver usando a API CreateTransformJob poderá reduzir o tempo necessário para concluir trabalhos de transformação em lote usando valores ideais para parâmetros, como MaxPayloadInMB, MaxConcurrentTransforms ou BatchStrategy. O valor ideal para MaxConcurrentTransforms é igual ao número de operadores de computação na tarefa de transformação em lote. Se você estiver usando o console do SageMaker AI, poderá especificar esses valores ideais de parâmetros na seção Configuração adicional da página de configuração do trabalho de transformação em lote. SageMaker A IA encontra automaticamente as configurações de parâmetros ideais para algoritmos integrados. Para obter algoritmos personalizados, forneça esses valores por meio de um endpoint execution-parameters.
R: O transformação em lote é compatível com CSV e JSON.
Inferência assíncrona
Os itens de perguntas frequentes a seguir respondem a perguntas gerais comuns sobre a SageMaker inferência assíncrona de IA.
R: A inferência assíncrona enfileira as solicitações recebidas e as processa de forma assíncrona. Essa opção é ideal para solicitações com grandes tamanhos de carga útil ou longos tempos de processamento que precisam ser processadas à medida que chegam. Opcionalmente, você pode definir configurações de ajuste de escala automático para reduzir verticalmente a contagem de instâncias para zero quando não estiver processando ativamente as solicitações.
R: O Amazon SageMaker AI oferece suporte à escalabilidade automática (escalonamento automático) do seu endpoint assíncrono. O ajuste de escala automático ajusta dinamicamente o número de instâncias provisionadas para um modelo em resposta às alterações na workload. Ao contrário de outros modelos hospedados que a SageMaker IA suporta, com a inferência assíncrona, você também pode reduzir suas instâncias de endpoints assíncronos para zero. As solicitações recebidas quando não há instâncias são enfileiradas para processamento quando o endpoint aumenta a escala verticalmente. Para obter mais informações, consulte Escalar automaticamente um endpoint assíncrono.
O Amazon SageMaker Serverless Inference também diminui automaticamente para zero. Você não verá isso porque a SageMaker IA gerencia a escalabilidade de seus endpoints sem servidor, mas se você não estiver enfrentando nenhum tráfego, a mesma infraestrutura se aplica.
