As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Você pode usar o Amazon SageMaker Clarify para entender a imparcialidade e a explicabilidade do modelo e para explicar e detectar preconceitos em seus modelos. Você pode configurar um trabalho de processamento do SageMaker Clarify para calcular métricas de viés e atribuições de recursos e gerar relatórios para explicar o modelo. SageMaker Os trabalhos de processamento do Clarify são implementados usando uma imagem de contêiner especializada do SageMaker Clarify. A página a seguir descreve como o SageMaker Clarify funciona e como começar com uma análise.
O que é imparcialidade e explicabilidade do modelo para predições de machine learning?
Modelos de machine learning (ML) estão ajudando a tomar decisões em domínios, como serviços financeiros, saúde, educação e recursos humanos. Políticos, reguladores e defensores levantaram conscientização sobre os desafios éticos e políticos impostos pelo ML e pelos sistemas baseados em dados. O Amazon SageMaker Clarify pode ajudar você a entender por que seu modelo de ML fez uma previsão específica e se esse viés afeta essa previsão durante o treinamento ou a inferência. SageMaker O Clarify também fornece ferramentas que podem ajudar você a criar modelos de aprendizado de máquina menos tendenciosos e mais compreensíveis. SageMaker O Clarify também pode gerar modelos de relatórios de governança que você pode fornecer às equipes de risco e conformidade e aos reguladores externos. Com o SageMaker Clarify, você pode fazer o seguinte:
-
Detectar desvio e ajudar a explicar suas predições de modelo.
-
Identificar os tipos de desvio nos dados de pré-treinamento.
-
Identificar vários tipos de vieses nos dados de pós-treinamento que podem surgir durante o treinamento do modelo ou quando o modelo estiver em produção.
SageMaker O Clarify ajuda a explicar como seus modelos fazem previsões usando atribuições de recursos. Ele também monitora os modelos de inferência que estão em produção para desvios de atribuição de atributos e vieses. As informações podem ajudar nas seguintes áreas:
-
Regulatória: Os formuladores de políticas e outros reguladores podem se preocupar com os impactos discriminatórios das decisões que usam resultados de modelos de ML. Por exemplo, um modelo de ML pode codificar preconceitos e influenciar uma decisão automatizada.
-
Negócios: Os domínios regulamentados podem precisar de explicações confiáveis sobre como os modelos de ML fazem predições. A explicabilidade do modelo pode ser particularmente importante para setores que dependem de confiabilidade, segurança e conformidade. Isso pode incluir serviços financeiros, recursos humanos, assistência médica e transporte automatizado. Por exemplo, as aplicações de empréstimo podem precisar fornecer explicações sobre como os modelos de ML fizeram determinadas predições para agentes de crédito, analistas e clientes.
-
Ciência de dados: cientistas de dados e engenheiros de ML podem depurar e melhorar modelos de ML quando podem determinar se um modelo está fazendo inferências com base em atributos inconsistentes ou irrelevantes. Eles também podem entender as limitações de seus modelos e as falhas que seus modelos podem ter.
Para uma postagem no blog que mostra como arquitetar e criar um modelo completo de aprendizado de máquina para reclamações fraudulentas de automóveis que integre o SageMaker Clarify a um pipeline de SageMaker IA, consulte o Architect e crie o ciclo de vida completo do aprendizado de máquina com: AWS Uma
Melhores práticas para avaliar a imparcialidade e a explicabilidade no ciclo de vida de ML
Imparcialidade como processo: As noções de desvio e imparcialidade dependem da aplicação. A medição do desvio e a escolha das métricas de desvio podem ser orientadas por considerações sociais, legais e coisas não técnicas. A adoção bem-sucedida de abordagens de ML conscientes inclui criar consenso e alcançar a colaboração entre as principais partes interessadas. Isso pode incluir equipes de produtos, políticas, jurídicas, de engenharia, de IA/ML, usuários finais e comunidades.
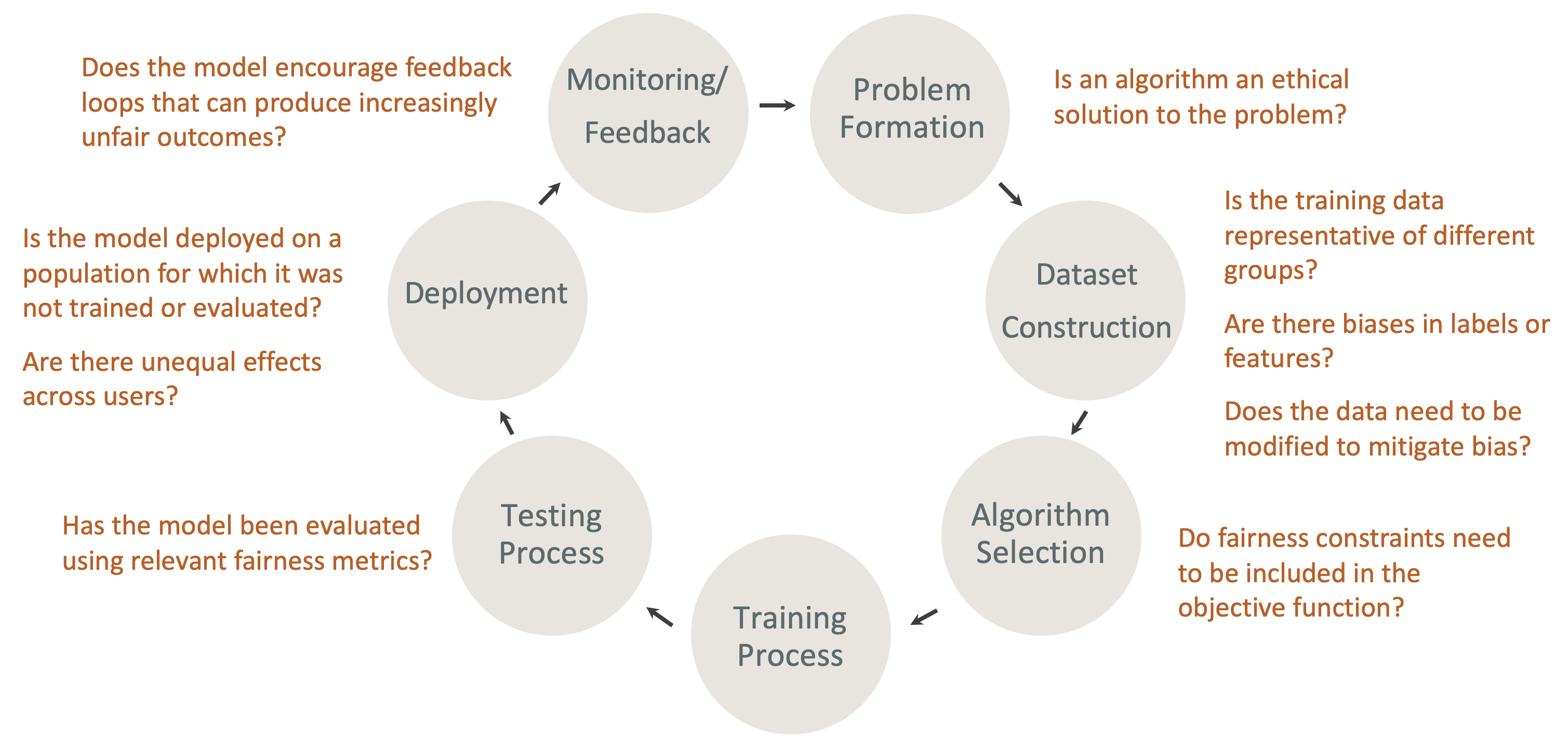
Imparcialidade e explicabilidade por design no ciclo de vida de ML: Considere a imparcialidade e a explicabilidade durante cada estágio do ciclo de vida do ML. Esses estágios incluem formação de problemas, construção de conjuntos de dados, seleção de algoritmos, processo de treinamento de modelos, processo de teste, implantação e monitoramento, além do feedback. É importante ter as ferramentas certas para fazer essa análise. Recomendamos fazer as seguintes perguntas durante o ciclo de vida de ML:
-
O modelo incentiva ciclos de feedback que podem produzir resultados cada vez mais injustos?
-
Um algoritmo é uma solução ética para o problema?
-
Os dados de treinamento possuem representatividade?
-
Há preconceitos nos rótulos ou nos atributos?
-
Os dados precisam ser modificados para mitigar o desvio?
-
As restrições de imparcialidade precisam ser incluídas na função objetiva?
-
O modelo foi avaliado com métricas imparciais relevantes?
-
Existem efeitos desiguais entre os usuários?
-
O modelo foi apresentado a uma população para a qual não foi treinado ou avaliado?
Guia para explicações sobre SageMaker IA e documentação sobre preconceitos
O desvio pode ocorrer e ser avaliado nos dados antes e depois do treinamento do modelo. SageMaker O Clarify pode fornecer explicações para as previsões do modelo após o treinamento e para os modelos implantados na produção. SageMaker O Clarify também pode monitorar modelos em produção para detectar qualquer variação em suas atribuições explicativas de linha de base e calcular linhas de base quando necessário. A documentação para explicar e detectar preconceitos usando o SageMaker Clarify está estruturada da seguinte forma:
-
Para obter informações sobre como configurar um trabalho de processamento para desvio e explicabilidade, consulte Configurar um SageMaker Clarify Processing Job.
-
Para obter informações sobre a detecção de desvio no pré-processamento de dados antes de serem usados para treinar um modelo, consulte Desvio nos dados de pré-treinamento.
-
Para obter informações sobre a detecção de desvio no pós-treinamento de dados do modelo, consulte Dados de pós-treinamento e desvio do modelo.
-
Para obter informações sobre a abordagem de atribuição de atributos para explicar as predições de modelo dele após o treinamento, consulte Explicabilidade do modelo.
-
Para obter informações sobre o monitoramento do desvio das contribuições dos atributos em relação à linha de base que foi estabelecida durante o treinamento de modelo, consulte Desvio de atribuição de atributos para modelos em produção.
-
Para obter informações sobre o monitoramento de modelos que estão em produção para o desvio da linha de base, consulte Desvio de polarização para modelos em produção.
-
Para obter informações sobre como obter explicações em tempo real a partir de um endpoint de SageMaker IA, consulte. Explicabilidade on-line com Clarify SageMaker
Como funcionam os trabalhos de processamento do SageMaker Clarify
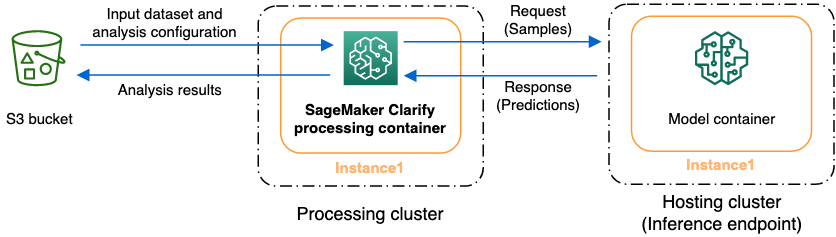
Você pode usar o SageMaker Clarify para analisar seus conjuntos de dados e modelos quanto à explicabilidade e ao viés. Um trabalho de processamento do SageMaker Clarify usa o contêiner de processamento do SageMaker Clarify para interagir com um bucket do Amazon S3 contendo seus conjuntos de dados de entrada. Você também pode usar o SageMaker Clarify para analisar um modelo de cliente implantado em um endpoint de inferência de SageMaker IA.
O gráfico a seguir mostra como uma tarefa de processamento do SageMaker Clarify interage com seus dados de entrada e, opcionalmente, com um modelo de cliente. Essa interação depende do tipo específico de análise que está sendo realizada. O contêiner de processamento SageMaker Clarify obtém o conjunto de dados de entrada e a configuração para análise de um bucket S3. Para determinados tipos de análise, incluindo análise de recursos, o contêiner de processamento do SageMaker Clarify deve enviar solicitações ao contêiner modelo. Em seguida, ele recupera as predições de modelo a partir da resposta que o contêiner do modelo envia. Depois disso, o contêiner de processamento do SageMaker Clarify calcula e salva os resultados da análise no bucket do S3.
Você pode executar uma tarefa de processamento do SageMaker Clarify em vários estágios do ciclo de vida do fluxo de trabalho de aprendizado de máquina. SageMaker O Clarify pode ajudá-lo a calcular os seguintes tipos de análise:
-
Métricas de desvio pré-treinamento. As métricas podem ajudá-lo a entender vieses em seus dados para que você possa abordá-los e treinar seu modelo em um conjunto de dados mais justo. Consulte Métricas de desvio pré-treinamento para obter informações sobre métricas de desvio pré-treinamento. Para executar um trabalho de análise de métricas de desvio pré-treinamento, você deve fornecer o conjunto de dados e um arquivo de configuração de análise JSON para Arquivos de configuração de análise.
-
Métricas de desvio do pós-treinamento. As métricas podem ajudá-lo a entender qualquer desvio introduzido por um algoritmo, escolhas de hiperparâmetros ou qualquer desvio que não tenha sido aparente no início do fluxo. Para obter mais informações sobre métricas de viés pós-treinamento, consulteMétricas de dados pós-treinamento e desvio do modelo. SageMaker O Clarify usa as previsões do modelo, além dos dados e rótulos, para identificar o viés. Para executar um trabalho de análise de métricas de desvio pós-treinamento, você deve fornecer o conjunto de dados e um arquivo de configuração de análise JSON. A configuração deve incluir o nome do modelo ou do endpoint.
-
Valores Shapley, que podem ajudá-lo a entender o impacto que seu atributo tem sobre o que seu modelo prevê. Para obter mais informações sobre valores Shapley, consulte Atributos de atributos que usam valores de Shapley. Esse atributo exige um modelo treinado.
-
Gráficos de dependência parcial (PDPs), que podem ajudá-lo a entender o quanto sua variável-alvo prevista mudaria se você variasse o valor de um recurso. Para obter mais informações sobre PDPs, consulte Análise de gráficos de dependência parcial (PDPs) Esse recurso requer um modelo treinado.
SageMaker Esclareça as previsões do modelo de necessidades para calcular métricas de viés pós-treinamento e atribuições de recursos. Você pode fornecer um endpoint ou o SageMaker Clarify criará um endpoint efêmero usando o nome do seu modelo, também conhecido como endpoint sombra. O contêiner SageMaker Clarify exclui o endpoint de sombra após a conclusão dos cálculos. Em um nível alto, o contêiner SageMaker Clarify conclui as seguintes etapas:
-
Validação de entradas e parâmetros.
-
Criação do endpoint de sombra (se um nome de modelo for fornecido).
-
Carregamento do conjunto de dados de entrada em um quadro de dados.
-
Obtenção das predições de modelo a partir do endpoint, se necessário.
-
Cálculo das métricas de desvio e atribuições de atributos.
-
Exclusão do endpoint de sombra.
-
Geração dos resultados da análise.
Depois que a tarefa de processamento do SageMaker Clarify for concluída, os resultados da análise serão salvos no local de saída que você especificou no parâmetro de saída de processamento da tarefa. Esses resultados incluem um arquivo JSON com métricas de desvio e atribuições de atributos globais, um relatório visual e arquivos adicionais para atribuições de atributos locais. Você pode baixar os resultados do local de saída e visualizá-los.
Para obter informações adicionais sobre métricas de viés, explicabilidade e como interpretá-las, consulte Saiba como o Amazon SageMaker Clarify ajuda a detectar preconceitos
Cadernos de amostra
As seções a seguir contêm cadernos para ajudá-lo a começar a usar o SageMaker Clarify, para usá-lo para tarefas especiais, incluindo aquelas dentro de um trabalho distribuído, e para visão computacional.
Conceitos básicos
Os exemplos de cadernos a seguir mostram como usar o SageMaker Clarify para começar com tarefas de explicabilidade e viés de modelo. As tarefas incluem a criação de um trabalho de processamento, o treinamento de um modelo de machine learning (ML) e o monitoramento de predições de modelo:
-
Explicabilidade e detecção de viés com o Amazon SageMaker Clarify
— Use o SageMaker Clarify para criar um trabalho de processamento para detectar viés e explicar as previsões do modelo. -
Monitorando o desvio de viés e o desvio de atribuição de recursos Amazon Clarify SageMaker — Use o Amazon
SageMaker Model Monitor para monitorar o desvio de viés e o desvio de atribuição de recursos ao longo do tempo. -
Como ler um conjunto de dados no formato JSON Lines em
um trabalho de processamento do SageMaker Clarify. -
Mitigue o viés, treine outro modelo imparcial e coloque-o no registro do modelo — Use a
Synthetic Minority Oversampling Technique (SMOTE) e o SageMaker Clarify para mitigar o viés, treine outro modelo e, em seguida, coloque o novo modelo no registro do modelo. O caderno de amostra também mostra como colocar os novos artefatos do modelo, incluindo dados, código e metadados do modelo, no registro. Este caderno faz parte de uma série que mostra como integrar o SageMaker Clarify a um pipeline de SageMaker IA descrito no Architect e criar o ciclo de vida completo do aprendizado de máquina com uma AWS postagem no blog.
Casos especiais
Os cadernos a seguir mostram como usar o SageMaker Clarify para casos especiais, inclusive dentro de seu próprio contêiner e para tarefas de processamento de linguagem natural:
-
Imparcialidade e explicabilidade com o SageMaker Clarify (traga seu próprio contêiner)
— Crie seu próprio modelo e contêiner que possam ser integrados ao SageMaker Clarify para medir o viés e gerar um relatório de análise de explicabilidade. Este exemplo de caderno também apresenta os principais termos e mostra como acessar o relatório por meio do SageMaker Studio Classic. -
Imparcialidade e explicabilidade com o processamento distribuído do SageMaker Clarify Spark — Use o processamento distribuído
para executar uma tarefa do SageMaker Clarify que mede o viés pré-treinamento de um conjunto de dados e o viés pós-treinamento de um modelo. Este exemplo de caderno também mostra como obter uma explicação sobre a importância dos recursos de entrada na saída do modelo e acessar o relatório de análise de explicabilidade por meio do SageMaker Studio Classic. -
Explicabilidade com SageMaker Clarify - Gráficos de dependência parcial (PDP)
— Use o SageMaker Clarify para gerar PDPs e acessar um modelo de relatório de explicabilidade. -
Use a explicabilidade da visão computacional (CV) para classificação de imagens
e detecção de objetos .
Verificou-se que esses notebooks são executados no Amazon SageMaker Studio Classic. Se você precisar de instruções sobre como abrir um caderno no Studio Classic, consulte Crie ou abra um notebook Amazon SageMaker Studio Classic. Caso seja solicitado que você escolha um kernel, escolha Python 3 (Ciência de dados).
