As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
SageMaker Arquitetura do Amazon Debugger
Este tópico mostra uma visão geral de alto nível do fluxo de trabalho do Amazon SageMaker Debugger.
O Depurador oferece apoio à funcionalidade do perfilador para otimização de performance e para identificar problemas de computação, como gargalos e subutilização do sistema, além de ajudar a otimizar a utilização de recursos de hardware em escala.
A funcionalidade de depuração do Depurador para a otimização de modelos consiste em analisar problemas de treinamento não convergentes que podem surgir e, ao mesmo tempo, minimizar as funções de perda usando algoritmos de otimização, como gradiente descendente e suas variações.
O diagrama a seguir mostra a arquitetura do SageMaker Debugger. Os blocos com linhas de limite em negrito são o que o Depurador gerencia para analisar o seu trabalho de treinamento.
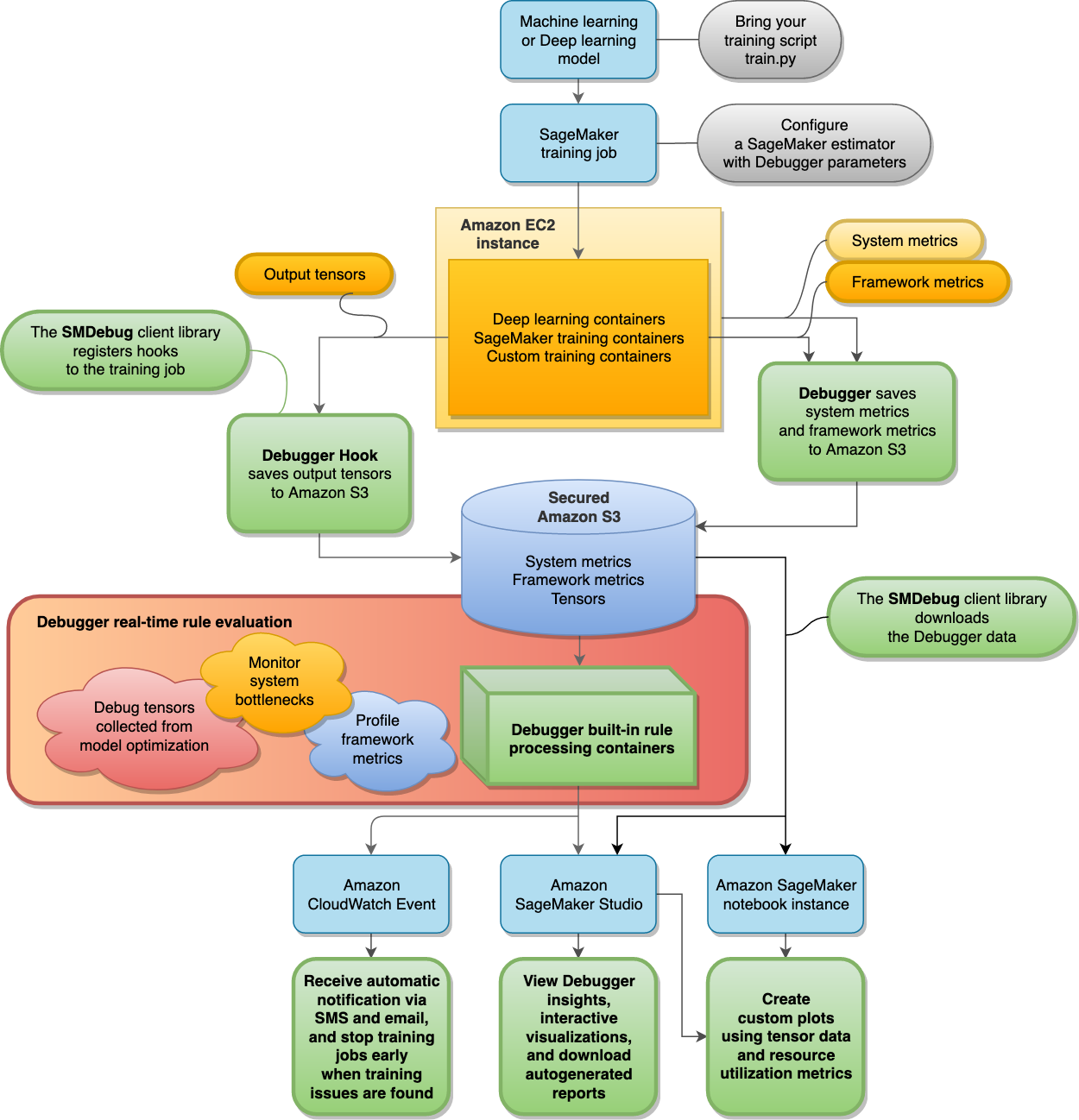
O Depurador armazena os seguintes dados de seus trabalhos de treinamento no seu bucket seguro do Amazon S3:
-
Tensores de saída: Coleções de escalares e parâmetros de modelo que são continuamente atualizados durante as passagens de avanço e retorno durante o treinamento de modelos de ML. Os tensores de saída incluem valores escalares (precisão e perda) e matrizes (pesos, gradientes, camadas de entrada e camadas de saída).
nota
Por padrão, o Debugger monitora e depura trabalhos de SageMaker treinamento sem nenhum Debugger-specific parâmetro configurado nos estimadores de IA. SageMaker O Depurador coleta métricas do sistema a cada 500 milissegundos e tensores de saída básicos (saídas escalares, como perda e precisão) a cada 500 etapas. Ele também executa a regra
ProfilerReportpara analisar as métricas do sistema e agregar insights e painéis do Depurador do Studio e um perfilador de relatório. O Depurador salva os dados de saída em seu bucket protegido do Amazon S3.
As regras integradas do Depurador são executadas em contêineres de processamento projetados para avaliar modelos de machine learning ao processar os dados de treinamento coletados em seu bucket do S3 (consulte Dados processados avaliar modelos). As regras integradas são totalmente gerenciadas pelo Depurador. Você também pode criar suas próprias regras personalizadas para o seu modelo e monitorar qualquer problema que desejar.
