Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Visualisieren Sie Amazon SageMaker Debugger-Ausgabetensoren in TensorBoard
Wichtig
Diese Seite ist zugunsten von Amazon SageMaker AI with veraltet, das eine umfassende TensorBoard Erfahrung bietet TensoBoard, die in SageMaker Training und die Zugriffskontrollfunktionen von SageMaker AI Domain integriert ist. Weitere Informationen hierzu finden Sie unter TensorBoard in Amazon SageMaker AI.
Verwenden Sie SageMaker Debugger, um Ausgabetensordateien zu erstellen, die kompatibel sind mit. TensorBoard Laden Sie die Dateien, um Ihre SageMaker Trainingsjobs zu visualisieren TensorBoard und zu analysieren. Der Debugger generiert automatisch Ausgabetensordateien, die kompatibel sind mit. TensorBoard Für jede Hook-Konfiguration, die Sie zum Speichern von Ausgabetensoren anpassen, bietet Debugger die Flexibilität, skalare Zusammenfassungen, Verteilungen und Histogramme zu erstellen, in die Sie importieren können. TensorBoard
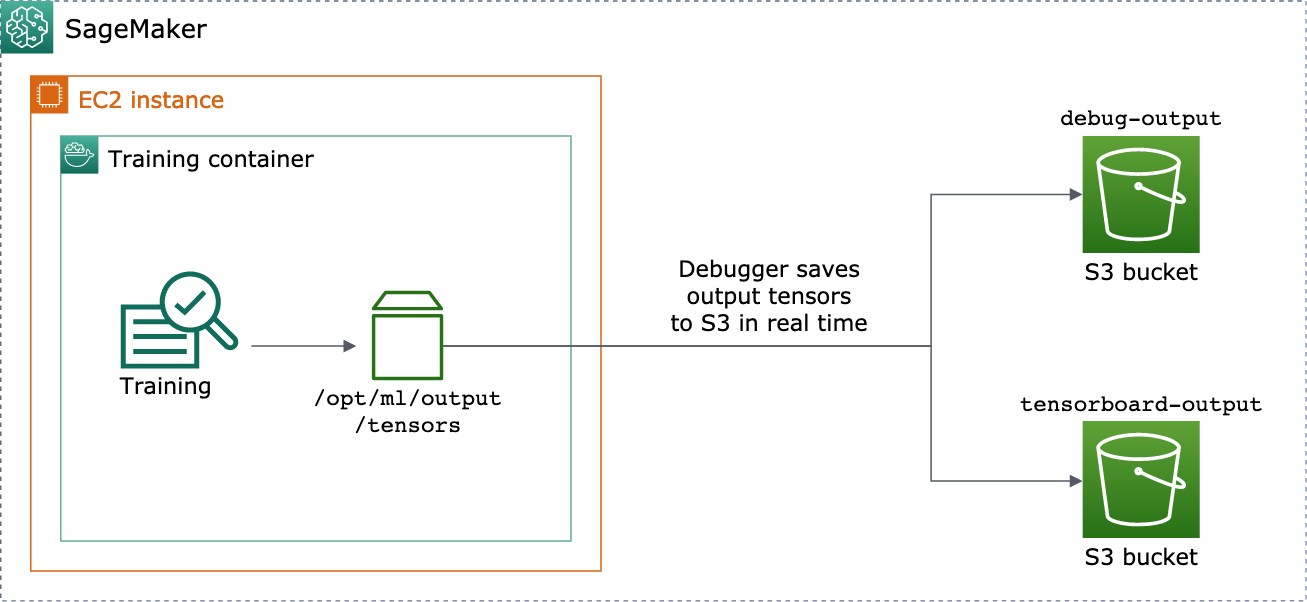
Sie können dies aktivieren, indem Sie DebuggerHookConfig und TensorBoardOutputConfig Objekte an eine estimator übergeben.
Das folgende Verfahren erklärt, wie Skalare, Gewichte und systematische Abweichungen als vollständige Tensoren, Histogramme und Verteilungen gespeichert werden, mit denen visualisiert werden kann. TensorBoard Der Debugger speichert sie im lokalen Pfad des Trainingscontainers (der Standardpfad ist /opt/ml/output/tensors) und synchronisiert sie mit den Amazon S3-Speicherorten, die über die Debugger-Ausgabekonfigurationsobjekte übergeben wurden.
Um kompatible Ausgabetensordateien mit dem Debugger zu speichern TensorBoard
-
Richten Sie ein
tensorboard_output_configKonfigurationsobjekt ein, um die TensorBoard Ausgabe mithilfe derTensorBoardOutputConfigDebugger-Klasse zu speichern. Geben Sie für dens3_output_pathParameter den Standard-S3-Bucket der aktuellen SageMaker AI-Sitzung oder einen bevorzugten S3-Bucket an. In diesem Beispiel wird dercontainer_local_output_pathParameter nicht hinzugefügt, sondern auf den lokalen Standardpfad/opt/ml/output/tensorsgesetzt.import sagemaker from sagemaker.debugger import TensorBoardOutputConfig bucket = sagemaker.Session().default_bucket() tensorboard_output_config = TensorBoardOutputConfig( s3_output_path='s3://{}'.format(bucket) )Weitere Informationen finden Sie unter der
TensorBoardOutputConfigDebugger-API im Amazon SageMaker Python SDK. -
Konfigurieren Sie den Debugger-Hook und passen Sie die Hook-Parameterwerte an. Der folgende Code konfiguriert beispielsweise einen Debugger-Hook so, dass alle skalaren Ausgaben in Trainingsphasen alle 100 Schritte und in Validierungsphasen alle 10 Schritte, die
weightsParameter alle 500 Schritte (dersave_intervalStandardwert für das Speichern von Tensorsammlungen ist 500) und diebiasParameter alle 10 globalen Schritte gespeichert werden, bis der globale Schritt 500 erreicht.from sagemaker.debugger import CollectionConfig, DebuggerHookConfig hook_config = DebuggerHookConfig( hook_parameters={ "train.save_interval": "100", "eval.save_interval": "10" }, collection_configs=[ CollectionConfig("weights"), CollectionConfig( name="biases", parameters={ "save_interval": "10", "end_step": "500", "save_histogram": "True" } ), ] )Weitere Informationen zu den Debugger-Konfigurations-APIs finden Sie unter Debugger
CollectionConfigundDebuggerHookConfigAPIs im Amazon SageMaker Python SDK. -
Konstruieren Sie einen SageMaker AI-Schätzer mit den Debugger-Parametern, die die Konfigurationsobjekte übergeben. Die folgende Beispielvorlage zeigt, wie ein generischer SageMaker AI-Schätzer erstellt wird. Sie können
estimatorundEstimatordurch die übergeordneten Schätzklassen und Schätzerklassen anderer SageMaker KI-Frameworks ersetzen. Verfügbare SageMaker KI-Framework-Schätzer für diese Funktionalität sind, und.TensorFlowPyTorchMXNetfrom sagemaker.estimatorimportEstimatorestimator =Estimator( ... # Debugger parameters debugger_hook_config=hook_config, tensorboard_output_config=tensorboard_output_config ) estimator.fit()Die
estimator.fit()Methode startet einen Trainingsjob und der Debugger schreibt die Ausgabetensordateien in Echtzeit in den Debugger S3-Ausgabepfad und in den TensorBoard S3-Ausgabepfad. Verwenden Sie die folgenden Schätzmethoden, um die Ausgabepfade abzurufen:-
Für den Debugger S3-Ausgabepfad, verwenden Sie
estimator.latest_job_debugger_artifacts_path(). -
Verwenden Sie für den TensorBoard S3-Ausgabepfad.
estimator.latest_job_tensorboard_artifacts_path()
-
-
Überprüfen Sie nach Abschluss des Trainings die Namen der gespeicherten Ausgabetensoren:
from smdebug.trials import create_trial trial = create_trial(estimator.latest_job_debugger_artifacts_path()) trial.tensor_names() -
Überprüfen Sie die TensorBoard Ausgabedaten in Amazon S3:
tensorboard_output_path=estimator.latest_job_tensorboard_artifacts_path() print(tensorboard_output_path) !aws s3 ls {tensorboard_output_path}/ -
Laden Sie die TensorBoard Ausgabedaten auf Ihre Notebook-Instance herunter. Mit dem folgenden AWS CLI Befehl werden die TensorBoard Dateien beispielsweise in das
/logs/fitaktuelle Arbeitsverzeichnis Ihrer Notebook-Instanz heruntergeladen.!aws s3 cp --recursive {tensorboard_output_path}./logs/fit -
Komprimieren Sie das Dateiverzeichnis in eine TAR-Datei, um es auf Ihren lokalen Computer herunterzuladen.
!tar -cf logs.tar logs -
Laden Sie die Tensorboard-TAR-Datei herunter und extrahieren Sie sie in ein Verzeichnis auf Ihrem Gerät, starten Sie einen Jupyter-Notebook-Server, öffnen Sie ein neues Notizbuch und führen Sie die App aus. TensorBoard
!tar -xf logs.tar %load_ext tensorboard %tensorboard --logdir logs/fit
Der folgende animierte Screenshot veranschaulicht die Schritte 5 bis 8. Es zeigt, wie Sie die Debugger-TAR-Datei herunterladen und TensorBoard die Datei in ein Jupyter-Notebook auf Ihrem lokalen Gerät laden.