Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Eines der Hauptmerkmale der SageMaker Modellparallelitätsbibliothek ist die Pipeline-Parallelität. Sie bestimmt die Reihenfolge, in der Berechnungen durchgeführt und Daten während des Modelltrainings geräteübergreifend verarbeitet werden. Pipelining ist eine Technik, um eine echte Parallelisierung der Modellparallelität zu erreichen, indem die GPUs Berechnungen gleichzeitig auf verschiedenen Datenproben durchgeführt werden, und um den Leistungsverlust aufgrund sequentieller Berechnungen zu überwinden. Wenn Sie Pipeline-Parallelität verwenden, wird der Trainingsauftrag per Pipeline über Mikro-Batches ausgeführt, um die GPU-Auslastung zu maximieren.
Anmerkung
Pipeline-Parallelität, auch Modellpartitionierung genannt, ist sowohl für als auch verfügbar. PyTorch TensorFlow Die unterstützten Versionen der Frameworks finden Sie unter Unterstützte Frameworks und AWS-Regionen.
Zeitplan für die Pipeline-Ausführung
Pipelining basiert auf der Aufteilung eines Mini-Batches in Mikrobatches, die in die Trainingspipeline eingespeist werden one-by-one und einem durch die Bibliothekslaufzeit definierten Ausführungsplan folgen. Ein Mikro-Batch ist eine kleinere Teilmenge eines bestimmten Trainings-Minibatches. Der Pipeline-Zeitplan bestimmt für jedes Zeitfenster, welcher Mikro-Batch von welchem Gerät ausgeführt wird.
Je nach Pipeline-Zeitplan und Modellpartition i kann die GPU beispielsweise Berechnungen (vorwärts oder rückwärts) für Microbatch durchführen, b während die GPU Berechnungen für Microbatch i+1 durchführt, wodurch beide gleichzeitig aktiv bleibenb+1. GPUs Während eines einzelnen Vorwärts- oder Rückwärtsdurchlaufs kann bei der Ausführung eines einzelnen Mikro-Batchs je nach Partitionierungsentscheidung dasselbe Gerät mehrmals aufgerufen werden. Eine Operation, die sich am Anfang des Modells befindet, kann z. B. auf demselben Gerät ausgeführt werden wie eine Operation am Ende des Modells, während die Operationen dazwischen auf verschiedenen Geräten ausgeführt werden. Das bedeutet, dass dieses Gerät zweimal aufgerufen wird.
Die Bibliothek bietet zwei verschiedene Pipeline-Zeitpläne, Simple und Interleaved, die mit dem pipeline Parameter im SageMaker Python-SDK konfiguriert werden können. In den meisten Fällen kann mit Interleaved-Pipelines eine bessere Leistung erzielt werden, wenn sie effizienter genutzt wird. GPUs
Überlappende Pipeline
In einer überlappenden Pipeline wird der Rückwärtsausführung der Mikro-Batches nach Möglichkeit Priorität eingeräumt. Dies erlaubt eine schnellere Freigabe des für Aktivierungen verwendeten Speichers. So wird der Speicher effizienter genutzt. Es ermöglicht auch, die Anzahl der Mikrobatches höher zu skalieren und so die Leerlaufzeit von zu reduzieren. GPUs Im Steady-State wechselt jedes Gerät zwischen Vorwärts- und Rückwärtsläufen hin und her. Das bedeutet, dass der Rücklauf eines Mikro-Batches ausgeführt werden kann, bevor der Vorwärtsdurchlauf eines anderen Mikro-Batches abgeschlossen ist.

Die vorherige Abbildung zeigt ein Beispiel für einen Ausführungsplan für die Interleaved-Pipeline über 2. GPUs In der Abbildung steht F0 für den Vorwärtsdurchlauf für Mikro-Batch 0 und B1 für den Rückwärtsdurchgang für Mikro-Batch 1. Aktualisierung steht für die Aktualisierung der Parameter durch den Optimizer. GPU0 priorisiert Rückwärtsdurchläufe, wann immer dies möglich ist (sie führt z. B. B0 vor F2 aus). So kann der Speicher gelöscht werden, der zuvor für Aktivierungen verwendet wurde.
Einfache Pipeline
Eine einfache Pipeline beendet dagegen die Ausführung des Vorwärtsdurchlaufs für jedes Mikro-Batch, bevor der Rückwärtsdurchlauf gestartet wird. Das bedeutet, dass sie nur die Phasen des Vorwärtsdurchlaufs und des Rücklaufs in sich selbst weiterleitet. Die folgende Abbildung zeigt anhand eines Beispiels, wie dies funktioniert, mehr als 2. GPUs

Pipelining der Ausführung in bestimmten Frameworks
In den folgenden Abschnitten erfahren Sie mehr über die Framework-spezifischen Entscheidungen zur Pipeline-Planung, die die SageMaker Modellparallelitätsbibliothek für und vorsieht. TensorFlow PyTorch
Pipeline-Ausführung mit TensorFlow
Die folgende Abbildung zeigt ein Beispiel TensorFlow für einen Graphen, der durch die Modellparallelitätsbibliothek partitioniert wurde. Dabei wird automatisiertes Modellsplitting verwendet. Wenn ein Diagramm geteilt wird, wird jeder resultierende Teilgraph B-mal repliziert (mit Ausnahme der Variablen). Dabei ist B die Anzahl der Mikro-Batches. In dieser Abbildung wird jeder Teilgraph zweimal repliziert (B=2). An jeder Eingabe eines Teilgraphen wird eine SMPInput Operation eingefügt und eine SMPOutput Operation wird an jedem Ausgang eingefügt. Diese Operationen kommunizieren mit dem Bibliotheks-Backend, um Tensoren zu und voneinander zu übertragen.

Das folgende Bild ist ein Beispiel für zwei Teilgraphen, die mit B=2 geteilt wurden. Dabei wurden Steigungsoperationen hinzugefügt. Der Gradient einer SMPInput Operation ist eine SMPOutput Operation und umgekehrt. So können die Steigungen während der Rückwärtsverteilung rückwärts laufen.
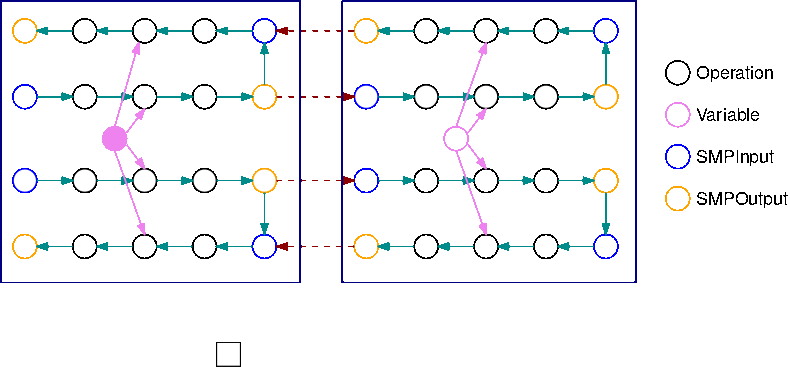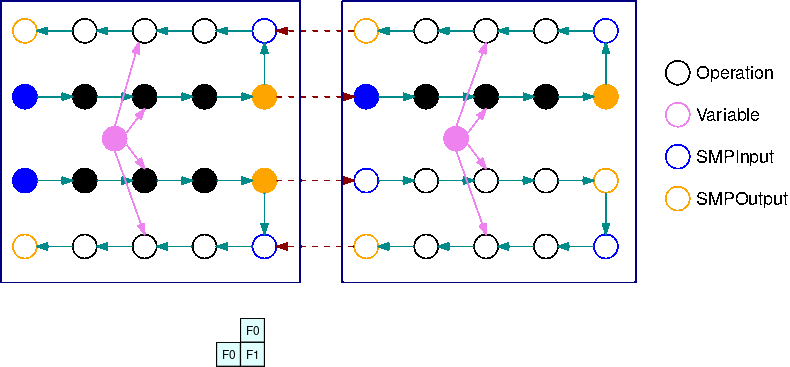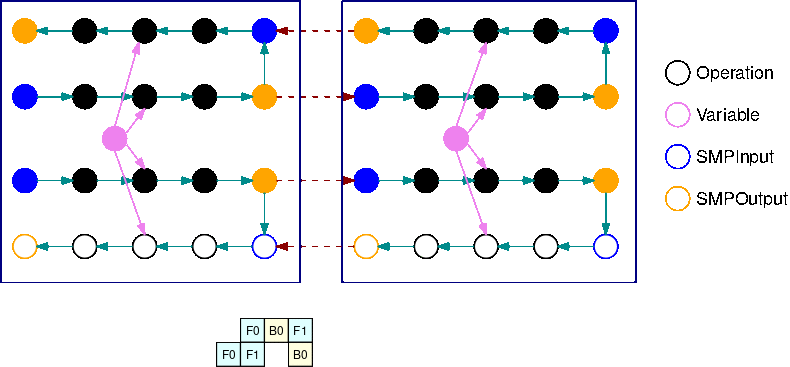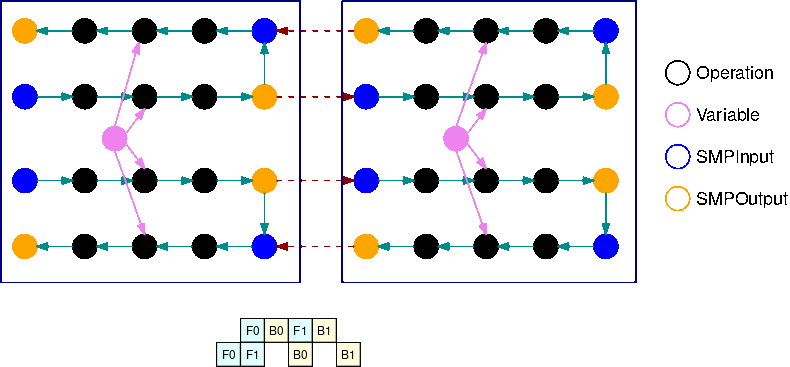
Dieses GIF zeigt ein Beispiel für einen Ausführungsplan für überlappende Pipelines mit B=2 Mikro-Batches und 2 Teilgraphen. Jedes Gerät führt nacheinander eines der replizierten Teilgraphen aus, um die GPU-Auslastung zu verbessern. Wenn B größer wird, geht der Anteil der Leerlaufzeitfenster gegen Null. Immer wenn es an der Zeit ist, Berechnungen (vorwärts oder rückwärts) für einen bestimmten replizierten Teilgraphen auszuführen, signalisiert die Pipeline-Layer den entsprechenden blauen SMPInput Operationen, das sie mit der Ausführung beginnen sollen.
Sobald die Steigungen aller Mikro-Batches in einem einzelnen Mini-Batch berechnet wurden, kombiniert die Bibliothek die Steigungen der einzelnen Mikro-Batches, die dann auf die Parameter angewendet werden können.
Pipeline-Ausführung mit PyTorch
Konzeptionell folgt das Pipelining einer ähnlichen Idee in. PyTorch Da PyTorch es sich jedoch nicht um statische Graphen handelt, verwendet die PyTorch Funktion der Modellparallelitätsbibliothek ein dynamischeres Pipelining-Paradigma.
Wie in TensorFlow, wird jeder Batch in eine Reihe von Mikrobatches aufgeteilt, die nacheinander auf jedem Gerät ausgeführt werden. Der Ausführungsplan wird jedoch über Ausführungsserver verwaltet, die auf jedem Gerät gestartet werden. Immer wenn die Ausgabe eines Submoduls, das sich auf einem anderen Gerät befindet, auf dem aktuellen Gerät gebraucht wird, wird zusammen mit den Eingangstensoren für das Submodul eine Ausführungsanfrage an den Ausführungsserver des entfernten Gerätes gesendet. Der Server führt dieses Modul dann mit den angegebenen Eingaben aus und gibt die Antwort an das aktuelle Gerät zurück.
Da sich das aktuelle Gerät während der Ausführung des Remote-Submoduls im Leerlauf befindet, wird die lokale Ausführung des aktuellen Mikro-Batches angehalten und die Bibliothekslaufzeit schaltet die Ausführung auf ein anderes Mikro-Batch um, an dem das aktuelle Gerät aktiv arbeiten kann. Die Priorisierung von Mikro-Batches wird durch den ausgewählten Pipeline-Zeitplan bestimmt. Bei einem überlappenden Pipeline-Zeitplan werden Mikro-Batches möglichst priorisiert, die sich in der Rückwärtsphase der Berechnung befinden.
